こんにちは。NEO(x) 機械学習エンジニアの宮脇(@catshun_)です。
LLM から望ましい出力を得るための評価については、評価セットを用いた定量評価などが挙げられますが、本記事では システムへのLLM導入 という側面から動作検証に焦点を当てた話をコラムとして記述します。
LLM の評価に関する紹介は、以下のブログで紹介しているのでこちらもご参照いただけると嬉しいです。
なお本記事は社内に向けたキャッチアップ資料として作成しており、加筆修正する可能性がありますが、本記事を読んだ方の議論のネタ程度になってくれれば幸いです。
おことわり
- 解釈や引用に誤りがありましたらご指摘いただけると幸いです。
- 本記事では詳細な解説を含みません。詳細な調査等は必ず参照元の論文等をご確認ください。
- プロダクト等の利用時は 必ずライセンスや利用規約を参照して下さい。
動作検証とは?
動作検証 (behavioral testing) は、ソフトウェア開発において、システムの動作が期待通りであるかを確認する検証方法 です。システムの内部構造を考慮せず、さまざまな入力やシナリオに対してシステムの挙動が想定される動作であるか検証します。
詳細は以下をご参照ください。
Ribeiro et al., 2020 (ACL)
ACL2020 ベストペーパーである以下の論文について、簡単に紹介いたします。 本論文は NLP モデルを動作検証するためのチェックリストを提案し、商用/最新モデルによる欠陥の検出を効率化した という内容です。
たとえば BERT を用いたポジネガのニ値分類では、分類対象が同じ意味でも予測値が大きく異なる という問題が見られます。具体的に 大規模言語モデル入門 で提供される llm-book/bert-base-japanese-v3-wrime-sentiment を用いて、同じ意味を持つ分類対象に対して評価してみます。
▶︎ Google Colab で BERT による感情分類を実行する(クリックで展開)
$ python -V Python 3.10.12
$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2023 NVIDIA Corporation Built on Tue_Aug_15_22:02:13_PDT_2023 Cuda compilation tools, release 12.2, V12.2.140 Build cuda_12.2.r12.2/compiler.33191640_0 $ nvidia-smi +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+
$ cat requirements.txt torch==2.3.1+cu121 transformers==4.42.4 fugashi==1.3.2 unidic-lite==1.0.8
import torch from transformers import AutoTokenizer, AutoModelForSequenceClassification, TextClassificationPipeline device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model_name_or_path = "llm-book/bert-base-japanese-v3-wrime-sentiment" tokenizer = AutoTokenizer.from_pretrained(model_name_or_path) model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path) classifier = TextClassificationPipeline(model=model, tokenizer=tokenizer, device=device, return_all_scores=True) batch_text = ["「DMM動画翻訳」は、動画コンテンツの字幕翻訳と音声合成を通じて、クリエイターや企業の国際展開を支援します。"] batch_score = classifier(batch_text) print(batch_score) # [[{'label': 'positive', 'score': 0.9976571798324585}, # {'label': 'negative', 'score': 0.002342833671718836}]]
| 分類対象 | ポジティブ | ネガティブ |
|---|---|---|
| 生成AIは未来のHRをどう変える? | .469 | .531 |
| 生成AIは未来のHRをどう変える | .839 | .161 |
| 生成AIは未来の Human Resource をどう変える? | .609 | .391 |
| 生成AIは未来の人的資源をどう変える? | .181 | .819 |
| 未来のHRを生成AIはどう変える? | .808 | .192 |
宣伝ですが、例文はPeopleX社との共同制作記事「生成AIは未来のHRをどう変える?」から選択しました。
なお BERT のファインチューニング用の学習セット WRIME は研究目的で利用可能であることに注意してください。
上記では「生成AIは未来のHRをどう変える?」という文に対して、疑問符を削除 したり、「HR」の表記を変更 したり、句構造を変える といった操作をしています。 これらは分類対象である感情表現(ポジティブ or ネガティブ)を変更させない範囲での操作ですが、分類結果が変化していることが分かります。
Behavioral testing
Ribeiro et al., 2020 (ACL) では、このような動作検証の操作を行い タスクに依存しない検証項目からなるチェックリストを作成しています。 チェックリストにおける操作は以下の3種類で構成されます。
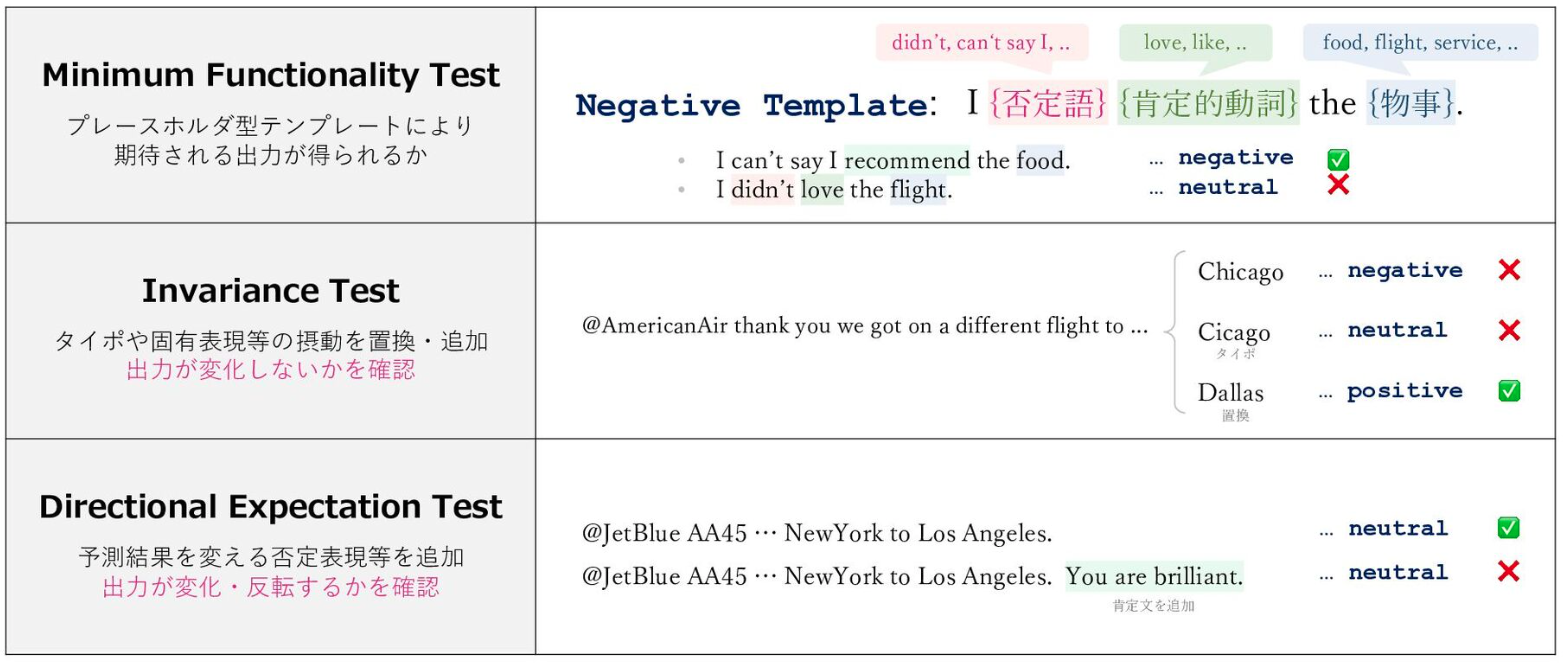
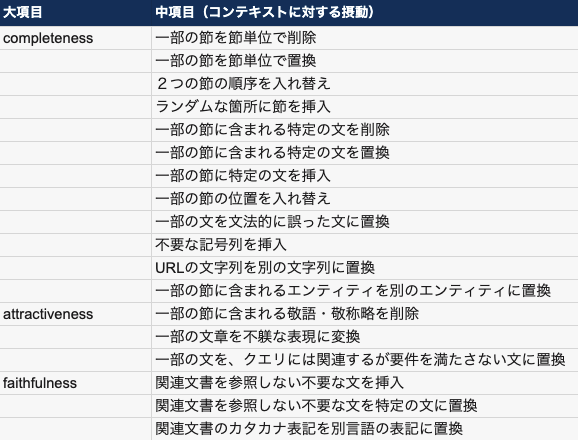
私個人としては、出力を想定して摂動を加える Directional Expectation Test, Invariance Test を用いて動作検証することが多いです。 例えば以下の例では ①完全性(出力文の形式が適切であるか)、②魅力性(ユーザにとって望ましい内容を生成しているか)、③忠実性(関連文書の情報を正しく参照するか)という3つの大項目を設けており、目検でチェックしてプロンプトを修正する というサイクルを素早く回せるよう 100 件ほど検証項目を作成します。
Negative instructions
Ribeiro et al., 2020 (ACL) では、「固有表現を置換する」などの摂動によって検証項目を作成していますが、他にもいくつかの作成方法が挙げられます。
視覚言語タスクにおける例として、Liu et al., 2024 (ICLR) では 画像に含まれない物体について LLM に回答を求める指示文 や、画像に含まれる物体に対して事実性の異なる指示文 を導入することで大規模視覚言語モデルにおける object hallucination の影響について調査しています。

また RAG を用いた応答生成システムの検証では、想定される『質問・答え・関連文書』のペアを用いて評価することが一般的ですが、関連文書に含まれる答えを置換した際に想定される回答をするか、複数の異なる質問タイプから同様の答えが得られるか などを確認することも重要となる場合があります。
また選択肢付き QA タスクにおいては、回答順序を入れ替えたり (Zong et al., 2024)、正解となる選択肢を除外する (Xu et al., 2024) といった操作により、LLM の脆弱性を調査する研究がいくつか存在します。選択肢付きタスクではこうした操作に対する検証も有効だと考えられます。
このようにシステムの堅牢性を懸念される場合は、特定の入力文に対して恣意的な摂動や操作を加えて LLM の出力を検証してみるのも良いかもしれません。
Property-based testing
前述した動作検証論文の同著者である Ribeiro 氏のブログでは、入力文に対する操作とは別に、出力文の属性に着目した検証方法 を紹介しています。
上記では、「30字以内で答えて」や「文頭に『こんにちは!』を含む」といった指示文を用いた場合に、出力文に対して assert len(repsonse) <= 30 や assert response.startswith("こんにちは!") といった静的なテストを行うことができると指摘しています。
特に、こうした静的なテストに関しては promptfoo が 文字列一致 や 出力形式、類似性 などに基づくアサーションタイプを用意しているので、これらを用いた検証も有効かと思います。
また出力文に対する形式という属性の側面では、Pydantic や Zod Schema を用いて 型チェック を行う方法もいくつか紹介されていたりします。
▶︎ LangChain では、ツール呼び出しモデルにおける
.bind_tools メソッドを用いたオブジェクトの引き渡しなども可能です(クリックで展開)
from langchain_anthropic import ChatAnthropic from langchain_core.pydantic_v1 import BaseModel, Field from langchain_core.tools import tool # Pydantic 形式 class multiply(BaseModel): """Return product of 'x' and 'y'.""" x: float = Field(..., description="First factor") y: float = Field(..., description="Second factor") # LangChain ツール形式 @tool def exponentiate(x: float, y: float) -> float: """Raise 'x' to the 'y'.""" return x**y # 関数形式 def subtract(x: float, y: float) -> float: """Subtract 'x' from 'y'.""" return y-x # OpenAI dict 形式 add = { "name": "add", "description": "Add 'x' and 'y'.", "parameters": { "type": "object", "properties": { "x": {"type": "number", "description": "First number to add"}, "y": {"type": "number", "description": "Second number to add"} }, "required": ["x", "y"] } } llm = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0) llm_with_tools = llm.bind_tools([multiply, exponentiate, add, subtract])
おわりに
ここまでお読みいただきありがとうございました! 紹介だけで終わってしまったので、ブログというよりは『つぶやき』に近い形となってしまいましたが、他にも良い検証方法等がありましたら、コメントで教えていただけると嬉しいです!
Algomatic では LLM を活用したプロダクト開発等を行っています。 LLM を活用したプロダクト開発に興味がある方は、下記リンクからカジュアル面談の応募ができるのでぜひお話ししましょう!
生成AI領域にしぼった転職エージェント
Algomatic グループでは、生成AI領域への転職を考えている方と並走してキャリア相談や転職相談をおこなう転職エージェントサービス 『.AI CAREER』 を展開しています。
転職を考えている方は、こちらから無料登録できます:
またAI人材を募集している企業の皆様は、works@algomatic.jp よりご相談ください!