こんにちは。Algomatic の宮脇(@catshun_)です。 本記事では文書検索において一部注目された BGE M3-Embedding について簡単に紹介します。
LLM評価ツールpromptfooとアサーションの解説
こんにちは、Algomatic LLM STUDIO インターンのなべ(@_h0jicha)です。
前回の記事では、LLM の日本語性能を評価するための様々なベンチマークを紹介しました。
しかし、こうしたベンチマークには以下のような課題が存在します。
- ベンチマークの導入に負担がかかってしまうため、もっと 気軽に評価したい
- 既存のベンチマークによる評価が難しく独自実装が必要なとき、あらかじめ基本的な機能が搭載されている評価ツールを利用したい
- LLM の評価とともに、LLM を使用する際の プロンプトの評価も同時に行いたい
そこで本記事では、LLM の出力品質を評価する際に活用できる promptfoo について紹介します。
目次
- promptfoo とは?
- 導入方法
- 環境構築
- 実験設定
- 評価実行
- アサーションについて
- おわりに
- 参考
- 筆者情報
Object-Oriented Conference2024 のランチセッションで生成AIの話をしました
2024年3月24日 (日) 開催の Object-Oriented Conference2024にて、ランチセッション登壇させていただきました。
登壇資料
登壇資料はこちらです。 speakerdeck.com
続きを読む生成AIで毎日がちょっと楽しくなる?LLM STUDIOの「今日の一言のお題」自動生成の舞台裏
こんにちは、Algomaticのnaotoota(@OTA57)です。現在はChief of Staffとして横断的にさまざまなカンパニーの支援を実施しています。 LLM STUDIOにおいてはPOの役割を担っているのですが、今日はLLM STUDIOのチーム運営における生成AIを活用したちょっとした取り組みをご紹介します。
LLM STUDIOではリモートのメンバーもいるため、メンバーが毎日の勤怠ややること、相談事項等をSlackにて毎日投稿(dailyスレッドと呼んでいます)しているのですが、 そこに生成AIを絡めてちょっとした楽しみを加えてみたという事例です。
【この記事に書いてあること】
- 「今日の一言のお題」自動生成開発の経緯
- 生成AIの得意、不得意について
- 「今日の一言のお題」自動生成の具体的な仕組み
- 生成AIの使い所を見極めて、業務に組み込むことの重要性
【この記事の想定読者】
- 生成AIを業務に活用したいと考えているエンジニアの方
- LLMの特性について興味がある方
LangGraph を用いた LLM エージェント、Plan-and-Execute Agents の実装解説
はじめに
こんにちは。Algomatic LLM STUDIO 機械学習エンジニアの宮脇(@catshun_)です。
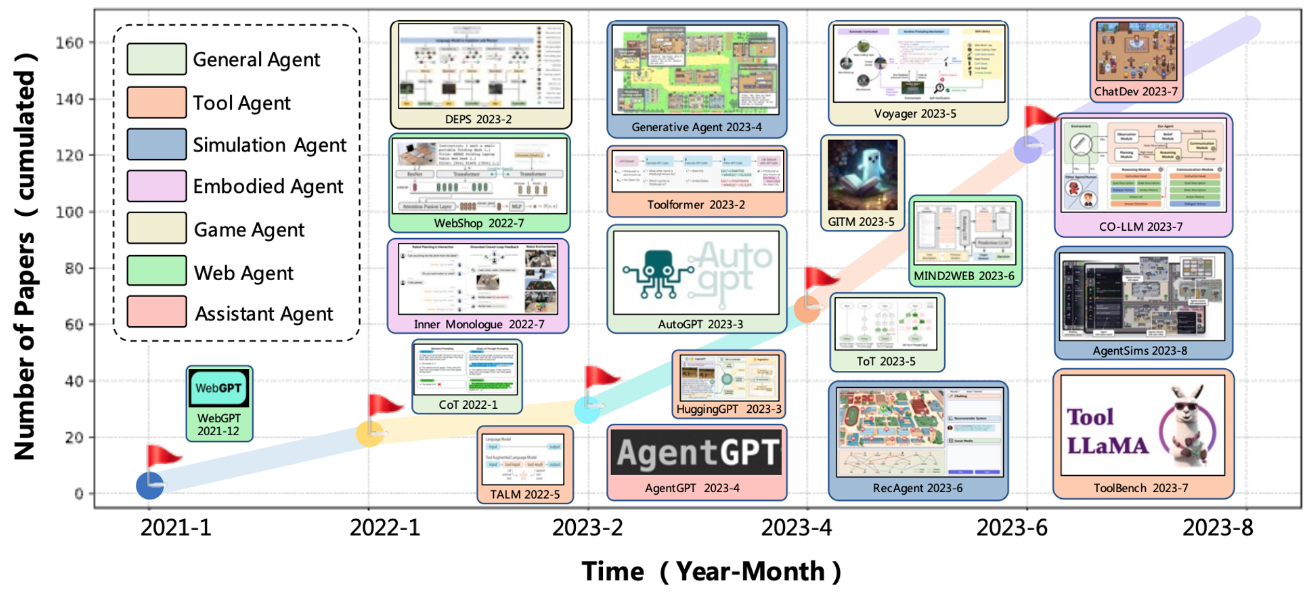
ChatGPT が発表されてからおよそ 1 年が経ち、AutoGPT, BabyAGI, HuggingGPT, Generative Agents, ChatDev, Mind2Web, Voyager, MetaGPT, Self-Recovery Prompting, OpenCodeInterpreter, AutoAgents などなど、大規模言語モデル (LLM) の抱負な知識および高度な推論能力を活用した LLM エージェント (AIエージェント) が発表されています。
続きを読む