はじめに
こんにちは。Algomatic LLM STUDIO 機械学習エンジニアの宮脇(@catshun_)です。
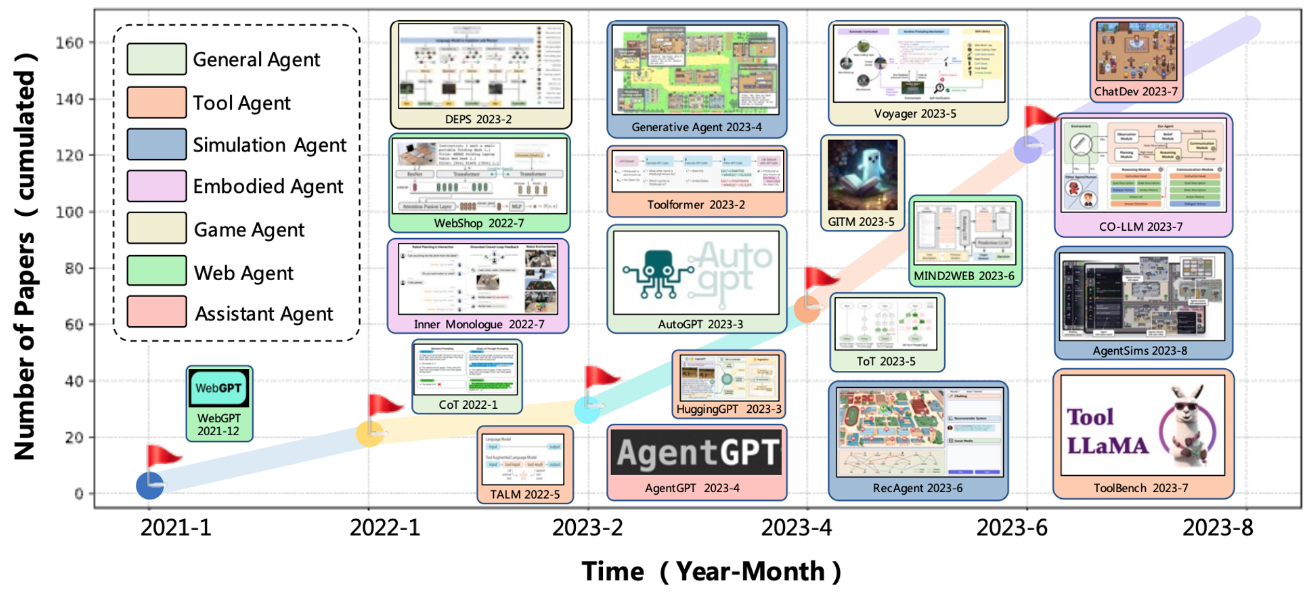
ChatGPT が発表されてからおよそ 1 年が経ち、AutoGPT, BabyAGI, HuggingGPT, Generative Agents, ChatDev, Mind2Web, Voyager, MetaGPT, Self-Recovery Prompting, OpenCodeInterpreter, AutoAgents などなど、大規模言語モデル (LLM) の抱負な知識および高度な推論能力を活用した LLM エージェント (AIエージェント) が発表されています。
直近ではコード生成からデバッグ、デプロイまで自律的に行うAI ソフトウェアエンジニア Devin, 3D 環境やビデオゲーム環境において自然言語の指示通りゲームをプレイする SIMA, GPT 等の LLM による高度な視覚及び言語能力を組み込んだヒューマノイドロボット Figure 01 も発表され注目を集めています。

Algomatic では LLM エージェントの開発にも注力していますが、本記事ではその一端となる「計画立案と実行に基づく推論」について、LangChain より公開された以下のブログとともに紹介いたします。
おことわり
- 本記事では LangChain の概要を理解されている方を想定読者としています。
- 記事の誤り等がありましたらご指摘いただけますと幸いです。
- 本記事はプログラム解説であり標準実行を保証するものではありません。実行詳細については 参照元スクリプト をご覧下さい。
はじめに
本記事では以下の環境を用いています。
langchain==0.1.12 langchain_openai==0.0.8 tavily-python==0.3.1 langchainhub==0.1.15 langgraph==0.0.28
言語モデルの呼び出しとして OpenAI API、また WEB 検索ツールとして Tavily API を使用します。
export OPENAI_API_KEY="Add your API key" export TAVILY_API_KEY="Add your API key"
またデータ型もここで宣言しておきます。
from typing import List, Union from langchain_core.messages.function import ( AIMessage, ChatMessage, FunctionMessage, HumanMessage, SystemMessage, ToolMessage ) Message = Union[AIMessage, ChatMessage, FunctionMessage, HumanMessage, SystemMessage, ToolMessage]
背景
LLM エージェント
Franklin and Graesser (1997) は 自律エージェント について以下のように言及しています。
自律エージェントとは、環境の中に位置し、環境の一部であるシステムであり、環境を感知し、時間をかけて、自らの課題を追求し、将来、感知したことに影響を及ぼすように行動するものである。 —— Franklin and Graesser (1997)
LLM エージェントの明確な定義があるか分かりませんが、LLM エージェントが指す一般的な共通認識は LLM を搭載した自律駆動型のシステム、すなわち「LLM がエージェントの脳として機能するいくつかのコンポーネントで構成されたシステム」という認識が 1 つあるかと思います。

なおAIエージェントに関する論文等の一覧はこちらにまとめていますので、こちらもご活用ください。
エージェント構築に関連するライブラリは、agents, agent-protocol, crewAI, AgentLite, AutoGen など様々ですが、本記事では LangChain を採用します。
LangChain を用いたエージェントの最も簡単な構築方法の一つは create_openai_functions_agent を呼び出すことです。
from langchain import hub from langchain.agents import AgentExecutor, create_openai_functions_agent from langchain_community.chat_models import ChatOpenAI from langchain_community.tools.tavily_search import TavilySearchResults from langchain_core.messages import AIMessage, HumanMessage search_tool = TavilySearchResults(max_results=1) tools = [search_tool] prompt = hub.pull("hwchase17/openai-functions-agent") model = ChatOpenAI() agent = create_openai_functions_agent(model, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) response = agent_executor.invoke({ "input": "Algomatic シゴラクAIとはどのようなプロダクトですか?", "chat_history": [], }) print(response.output)
上記を実行すると以下のような出力結果が表示されます。
> Entering new AgentExecutor chain...
Invoking: `tavily_search_results_json` with `{'query': 'Algomatic シゴラクAI'}`
[{'url': 'https://algomatic.jp/news/shigorakuai_release', 'content': 'Algomaticが提供する法人向けChatGPTが、あらゆるシゴトをラクにする「シゴラクAI」としてリニューアル. 大規模言語モデル等生成AI技術を活用したサービスの開発・提供を手掛ける株式会社Algomatic(本社:東京都港区、代表取締役社長:大野峻典、以下Algomatic ...'}]Algomaticが提供する法人向けChatGPTが、あらゆるシゴトをラクにする「シゴラクAI」としてリニューアルされました。Algomaticは大規模言語モデル等生成AI技術を活用したサービスの開発・提供を手掛ける企業です。詳細については[こちらのリンク](https://algomatic.jp/news/shigorakuai_release)をご覧ください。
> Finished chain.
Algomaticが提供する法人向けChatGPTが、
あらゆるシゴトをラクにする「シゴラクAI」としてリニューアルされました。
Algomaticは大規模言語モデル等生成AI技術を活用した
サービスの開発・提供を手掛ける企業です。
詳細については [こちらのリンク](https://algomatic.jp/news/shigorakuai_release)
をご覧ください。
もう少し詳しくみると create_openai_functions_agent には model, tools, prompt の 3 つが渡されます。
model は言語モデルであり AIMessage を返します。
>>> model.invoke("hello") AIMessage(content='Hello! How can I assist you today?', response_metadata={'finish_reason': 'stop', 'logprobs': None})
tools は言語モデルが呼び出す対象で、かつ実行可能なツール集合です。この例では検索ツールとして Tavily API を登録しています。
>>> search_tool.invoke("Algomatic シゴラクAI") [{'url': 'https://prtimes.jp/main/html/rd/p/000000011.000120362.html', 'content': '株式会社Algomatic(本社:東京都港区、代表取締役社長:大野峻典、以下Algomatic)は、ChatGPTをビジネスで簡単かつ安心して活用できる「シゴラクAI ...'}]
prompt は言語モデルに渡す指示文です。展開すると以下のようなテンプレートが表示されます。入力の引数は、実行中に使用されたツール等の実行値などが格納される agent_scratchpad と、ユーザから入力されるクエリ要求 input が渡されます。
>>> prompt
ChatPromptTemplate(
input_variables=["agent_scratchpad", "input"],
input_types={
"chat_history": List[Message],
"agent_scratchpad": List[Message],
},
metadata={},
messages=[
# システムプロンプト
SystemMessagePromptTemplate(
prompt=PromptTemplate(input_variables=[], template="You are a helpful assistant"),
),
# 対話履歴
MessagePlaceholder(
variable_name="chat_history", optional=True,
),
# ユーザ要求
HumanMessagePromptTemplate(
prompt=PromptTemplate(input_variables=["input"], template="{input}")
),
# ツール等の実行結果
MessagePlaceholder(
variable_name="agent_scratchpad"
)
]
)
上記 3 つを引数として create_openai_functions_agent は LangChain Expression Language を用いて連結された RunnableSequence を返します。これによりユーザ入力が input として渡されます。なお LLM がツールを呼び出し可能にするために tools は function calling で呼び出せる JSON 形式に変換されます。
>>> agent
agent: RunnableSequence = (
RunnablePassthrough.assign(
agent_scratchpad=lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
)
)
| prompt
| llm.bind(functions=[convert_to_openai_function(t) for t in tools])
| OpenAIFunctionsAgentOutputParser()
)
LangGraph
LangGraph は LangChain との使用が想定されたライブラリで、LLM を用いたステートフルなマルチアクタアプリケーションを構築することができます。
LangGraph の特徴は有向非巡回グラフ(Directed Acyclic Graph; DAG)を構築する点にあり、LCEL (LangChain Expression Language) では実現困難であった ループを伴う連鎖 が実現可能となります。LangGraph の解説については以下の記事で紹介されていますので、詳細を知りたい方はこちらを参照ください。
LangGraph では、任意の機能(LLM や関数の実行など)を ノード とし、機能間の遷移を エッジ として定義することでグラフを構築します。共通するスクラッチパッドを各ノードがアクセス可能な グラフステート として利用し、各ノードでグラフステートを参照することでタスク要求に応えます。
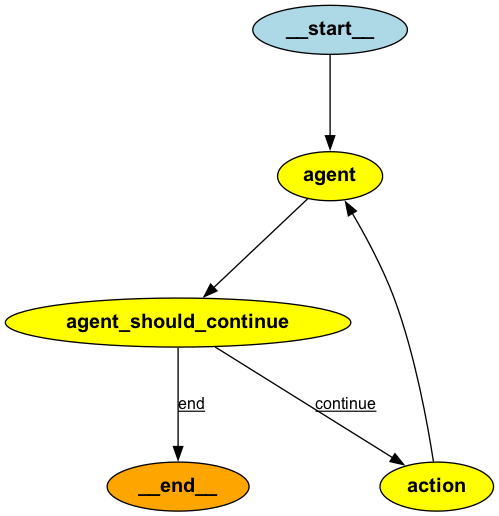
Agents における Plan-and-Execute の仕組み
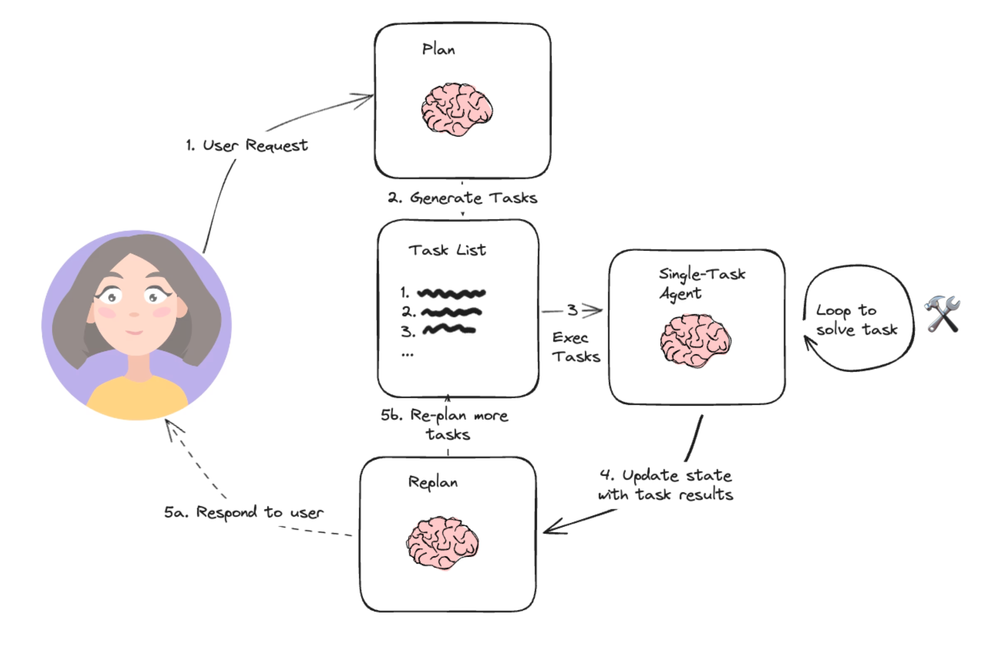
Plan-and-Solve Agent
1 つ目に紹介するのは Plan-and-Solve Prompting (Wang+'23) を踏襲したエージェントシステムです。元の論文については以下の記事で紹介していますので併せてご覧ください。
コードの詳細は以下を参照ください。
Plan-and-Solve Agent は以下の planner_content で定義する指示を用いて LLM に計画立案を誘起するプロンプト手法です。まずはプラン生成についてみてみます。
from langchain.chains.openai_functions import create_structured_output_runnable from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel class Plan(BaseModel): steps: List[str] = Field(description="異なるステップをたどる場合はソートされた順序に従うこと") planner_content = """ 与えられた目的について、簡単な step-by-step の計画を考えなさい。 この計画には、正しく実行すれば正しい答えが得られるような、個々の作業を含むようにします。 余計なステップを追加しないでください。 最終ステップの結果が最終的な答えであるべきです。 各ステップに必要な情報がすべて含まれていることを確認してください。 {objective}""" planner_prompt = ChatPromptTemplate.from_template(planner_content) planner = create_structured_output_runnable( Plan, ChatOpenAI(model="gpt-4-turbo-preview", temperature=0), planner_prompt )
planner を実行すると、入力されたクエリ要求がタスク系列として出力されます。
>>> planner.invoke({"objective": "日本一ラーメンの消費額の多い県では、どのようなラーメンが有名ですか?"})
Plan(steps=['日本一ラーメンの消費額の多い県を調べる。', 'その県で有名なラーメンの種類を調べる。'])
ここでは上記のように作成されたタスク系列を 1 つずつ実行していくようなグラフを構築します。
from langchain_core.pydantic_v1 import BaseModel, Field from typing import List, Tuple, Annotated, TypedDict import operator class GraphState(TypedDict): # 各ノードがアクセス可能なスクラッチパッド。 # このステートを各ノード遷移で更新していく。 input: str plan: List[str] past_steps: Annotated[List[Tuple], operator.add] # 値が extend によって更新される response: str
ノードでの実行内容をノード関数として定義します。ノード関数は任意の粒度で実装可能であり、ツールや LLM 呼び出し等が可能です。
各ノード関数は、先ほど定義した GraphState を入力として受け取り、GraphState に関して更新する一部の内容を辞書として返します。
async def node_plan(state: PlanExecute): # planner を実行してタスク系列を生成するノード。 # 生成されたタスク系列はスクラッチパッドの plan として更新される。 plan = await planner.ainvoke({"objective": state["input"]}) return {"plan": plan.steps} async def node_execute(state: PlanExecute): # タスク系列から先頭のタスクを選択して実行するノード。 # 実行結果はスクラッチパッドの past_steps として更新される。 task = state["plan"][0] agent_response = await agent_executor.ainvoke({"input": task, "chat_history": []}) return { "past_steps": (task, agent_response["agent_outcome"].return_values["output"]) } async def node_replan(state: PlanExecute): # タスク系列から先頭のタスクを選択して実行するノード。 # 実行結果はスクラッチパッドの past_steps として更新される。 output = await replanner.ainvoke(state) if isinstance(output, Response): return {"response": output.response} else: return {"plan": output.steps}
ノードを記述したので、グラフを作成します。
from langgraph.graph import StateGraph, END graph = StateGraph(State) # ノード(任意の機能)の定義 graph.add_node("planner", node_plan) graph.add_node("agent", node_execute) graph.add_node("replan", node_replan) # 開始ノードの指定 graph.set_entry_point("planner") # エッジ(ノード間の遷移)の定義 graph.add_edge("planner", "agent") # planner -> execute graph.add_edge("agent", "replan") # execute -> replan # 条件付きエッジの定義 graph.add_conditional_edges( "replan", lambda state: True if state["response"] else False, # response が格納されていれば True { True: END, # replan -> END (if True) False: "agent", # replan -> execute (if False) }, ) # コンパイル app = graph.compile()
ReWOO
2つ目に紹介するのは ReWOO (Xu+'23) です。先ほどの Plan-and-Solve Agent とは異なり、タスク実行後に LLM による観察フェーズを省いているのが特徴です。元の論文については以下の記事で紹介していますので併せてご覧ください。

コードの詳細は以下を参照ください。
ReWOO は (Plan, #E) を 1 つの単位とするタスク系列を立案します。具体的には以下のようにプロンプトを用いてタスク系列を生成します。
prompt = """以下のタスクについて、step-by-step に問題を解決可能な計画を立案してください。各計画では、どの外部ツールとツール入力を組み合わせて証拠を取り出すかを示します。証拠を変数 #E に格納し、後のツールから呼び出すことができます。(Plan, #E1, Plan, #E2, Plan, ...) のように Plan と #E は交互に計画します。 ツールは以下のいずれかです。 (1) Google[input]: Google から結果を検索するワーカー。特定のトピックについて短く簡潔な答えを見つけたいときに便利。入力は検索クエリーでなければならない。 (2) LLM[input]: 自分のように事前に訓練されたLLM。一般的な世界の知識や常識で行動する必要があるときに役立つ。自分で問題を解決する自信がある場合に優先的に使う。入力はどのような命令でもよい。 具体例。 Task: トーマス、トビー、レベッカは1週間で合計157時間働いた。トーマスは x 時間働いた。トビーはトーマスの2倍より10時間少なく働き、レベッカはトビーより8時間少なく働いた。レベッカは何時間働いたか? Plan: トーマスが x 時間働いたとすると,この問題を代数式に変換し Wolfram Alpha を用いて解きなさい. #E1 = WolframAlpha[Solve x + (2x - 10) + ((2x - 10) - 8) = 157]. Plan: トーマスの労働時間を求める #E2 = LLM[#E1 が与えられたとき x は何か] Plan: レベッカの労働時間を計算する #E3 = LLM[(2 ∗ #E2 - 10) - 8] では始めます。 計画を詳細に記述してください。各計画には #E を1つだけ付与して下さい。 Task: {task}"""
実際に以下の例で推論計画を生成してみます。
>>> model.invoke(prompt.format(task="東京タワーとスカイツリーの高さの差分は何メートルですか?")) Plan: 東京タワーとスカイツリーの高さを調べ、その差分を計算する。 #E1 = Google[input: "東京タワー 高さ"] Plan: 東京タワーの高さを取得する。 #E2 = LLM[#E1 から東京タワーの高さを取得する] Plan: スカイツリーの高さを調べる。 #E3 = Google[input: "スカイツリー 高さ"] Plan: スカイツリーの高さを取得する。 #E4 = LLM[#E3 からスカイツリーの高さを取得する] Plan: 東京タワーとスカイツリーの高さの差分を計算する。 #E5 = LLM[#E2 - #E4]
計画の生成結果からツールを適切に選択して計画立案することがわかります。 ここでは以下のスクラッチパッドを用います。
from typing import TypedDict, List class GraphState(TypedDict): task: str # ユーザからのクエリ plan_string: str # タスク系列(計画)の文字列 steps: List # タスク系列 results: dict # タスクの実行結果が格納される result: str
Planner
先ほどタスク系列を生成しましたがノードとして再定義します。
import re from langchain_core.prompts import ChatPromptTemplate # Plan: * #E1 = *[*] のような文字列を見つけるための正規表現 regex_pattern = r"Plan:\s*(.+)\s*(#E\d+)\s*=\s*(\w+)\s*\[([^\]]+)\]" # 先ほど定義した計画プロンプトを利用 prompt_template = ChatPromptTemplate.from_messages([("user", prompt)]) # RunnableSequence を作成 planner = prompt_template | model def get_plan(state: GraphState): # ユーザからのクエリ入力からタスク系列を生成 # 正規表現を用いてタスク系列のリストを取得 result = planner.invoke({"task": state["task"]}) steps = re.findall(regex_pattern, result.content) return {"steps": steps, "plan_string": result.content}
Executor
Executor はタスクを受け取り、順番にツール実行を伴う推論を実施します。
def _get_current_task(state: GraphState): # タスク未実施の場合 if state["results"] is None: return 1 # タスクが全て終了している場合 if len(state["results"]) == len(state["steps"]): return None # それ以外、現在のタスク番号を返す。 else: return len(state["results"]) + 1 def tool_execution(state: GraphState): """ ツール実行ノード """ # 現在のタスクを取得 step_id = _get_current_task(state) current_task = state["steps"][step_id - 1] plan_desc, step_name, tool, tool_input = current_task # plan_desc = '東京タワーとスカイツリーの高さを調べ、その差分を計算する。' # step_name = '#E1' # tool = Google # tool_input = input: "東京タワー 高さ" # 既に #Ei に値が格納されている場合は置換する _results = state["results"] or {} for k, v in _results.items(): tool_input = tool_input.replace(k, v) # ツールの実行 if tool == "Google": result = search.invoke(tool_input) elif tool == "LLM": result = model.invoke(tool_input) else: raise ValueError("ToolNotFound") # 実行結果を results 更新 _results[step_name] = str(result) # {"#E2": result} return {"results": _results}
Solver
タスク系列におけるツール実行を伴う推論が全て完了したら、ユーザに応答文を返します。 具体的には Solver がタスク系列を受け取り、最終的な応答文を生成します。
solve_prompt = """次の課題を解いて下さい。 この問題を解決するために、我々は段階的な計画を立て、各計画に対応する証拠を検索しました。 長い証拠には無関係な情報が含まれている可能性があるので注意して下さい。 {plan} では提供された証拠に従って問題を解いてください。 余分な言葉を使わず、直接答えを答えること。 Task: {task} Response:""" def node_solve(state: GraphState): """ 最終的な応答文を生成するノード """ # 過去実施したタスクの結果をまとめる plan = "" for _plan, step_name, tool, tool_input in state["steps"]: _results = state["results"] or {} for k, v in _results.items(): tool_input = tool_input.replace(k, v) plan += f"Plan: {_plan}\n{step_name} = {tool}[{tool_input}]" # 応答文を生成 prompt = solve_prompt.format(plan=plan, task=state["task"]) result = model.invoke(prompt) return {"result": result.content}
ノード関数を定義したのでグラフを作成します。
from langgraph.graph import StateGraph, END graph = StateGraph(ReWOO) # ノード(任意の機能)の定義 graph.add_node("plan", get_plan) graph.add_node("tool", tool_execution) graph.add_node("solve", solve) # 開始ノードの指定 graph.set_entry_point("plan") # エッジ(ノード間の遷移)の定義 graph.add_edge("plan", "tool") # plan -> tool graph.add_edge("solve", END) # solve -> END # 条件付きエッジの定義 graph.add_conditional_edges( "tool", lambda state: "solve" if _get_current_task(state) is None else "tool", { "solve": "solve", # tool -> solve "tool": "tool", # tool -> tool } ) # コンパイル app = graph.compile()
グラフを作成したので以下のようなクエリをグラフに入力してみます。
{"task": "東京タワーとスカイツリーの高さの差分は何メートルですか?"}
実行した結果を一部抜粋します。
変数 #Es に実行結果が格納されていることが分かります。
{
'results': {
'#E1': "[{'url': 'https://www.dictionary.com/browse/input', 'content': '省略'}]",
'#E2': "content='東京タワーの高さは332.9メートルです。',
'#E3': '[{\'url\': \'https://dictionary.cambridge.org/dictionary/english/input\', \'content\': "省略"}]',
'#E4': "content='スカイツリーの高さは634メートルです。2012年に完成し、東京都墨田区に位置しています。',
'#E5': "content='東京タワーの高さは332.9メートルであり、スカイツリーの高さは634メートルです。スカイツリーは2012年に完成し、東京都墨田区に位置しています。'
},
'result': '301.1メートル',
}
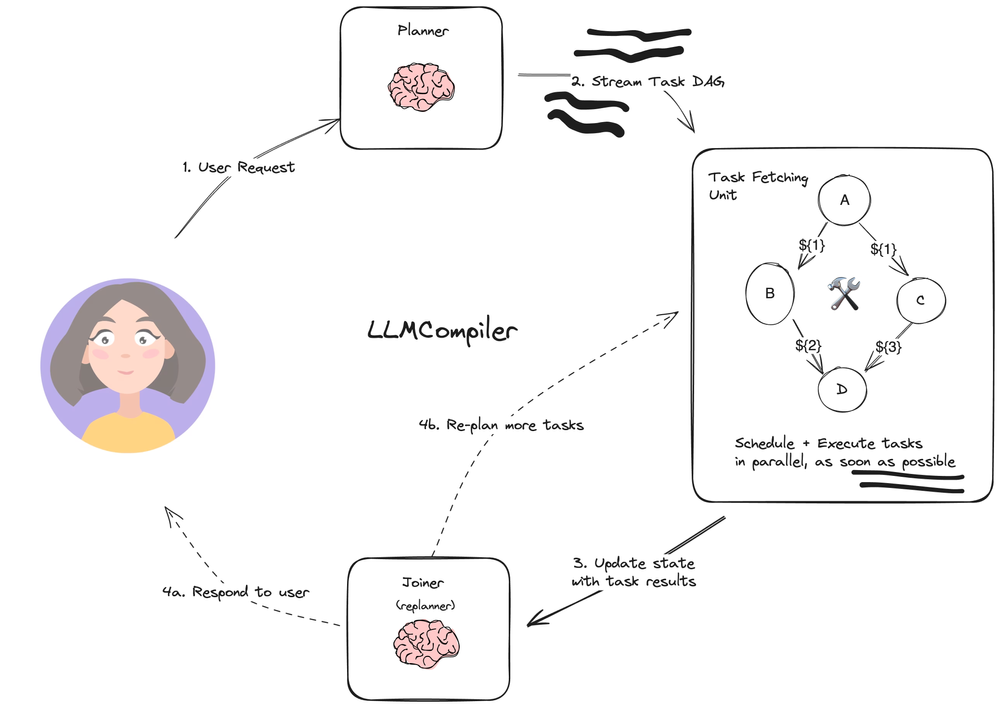
LLM Compiler
最後に紹介するのは LLM Compiler (Kim+'23) です。先ほどの ReWOO とは異なり、タスク系列を並列化することで高速な推論を実現するのが特徴です。元の論文については以下の記事で紹介していますので併せてご覧ください。
コードの詳細は以下を参照ください。なお LLM Compiler のコード行数が多いため、ここではキモとなるコードを引用する形で解説のみを行います。
LLM Compiler は ReWOO と同様にタスク系列を生成します。生成されたタスク系列は逐次実行ではなく並列実行されます。
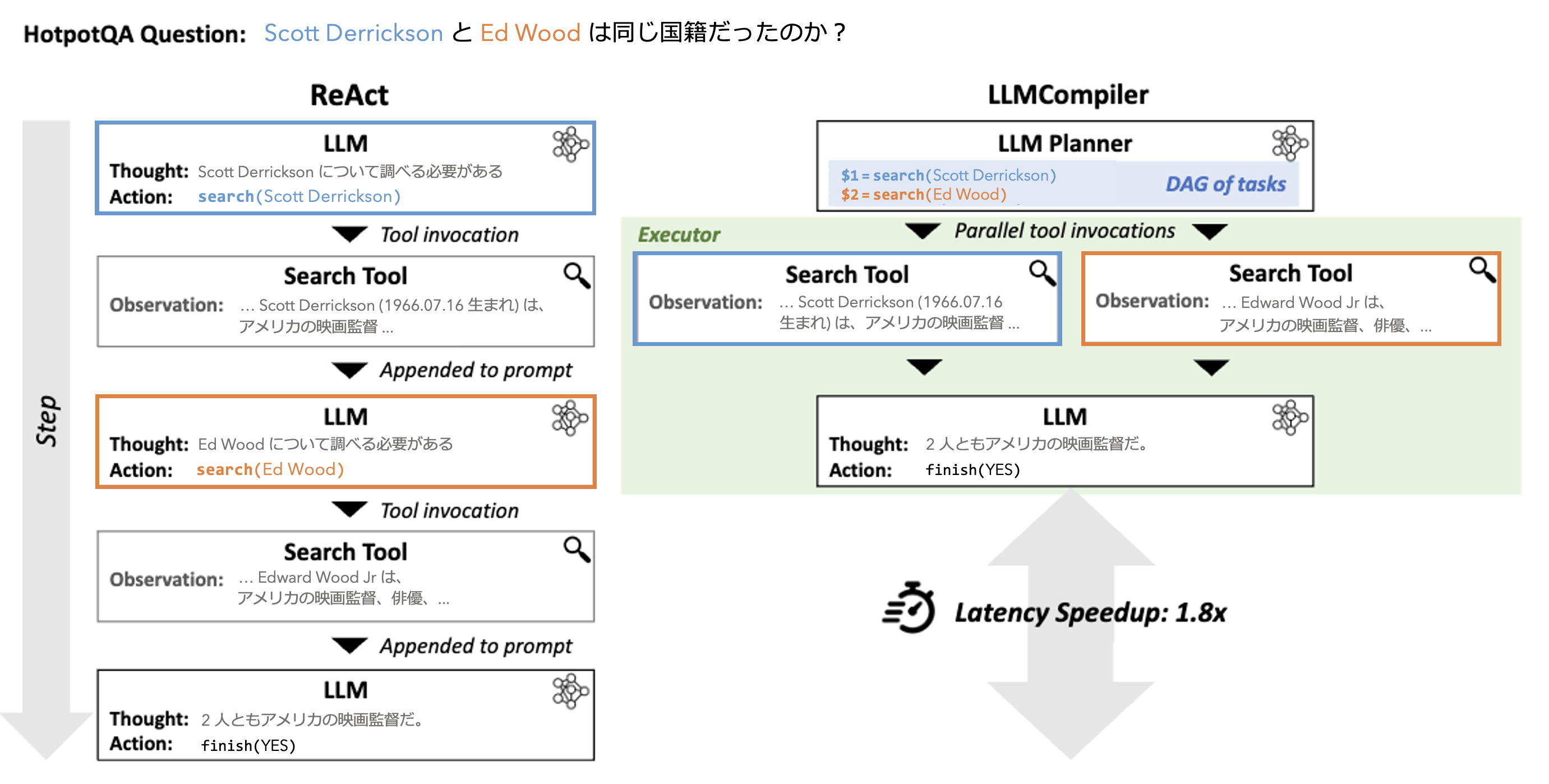
LLM Compiler では、以下のようなグラフを作成します。
from langgraph.graph import MessageGraph, END from typing import Dict graph_builder = MessageGraph() # ノード(任意の機能)の定義 graph_builder.add_node("plan_and_schedule", plan_and_schedule) graph_builder.add_node("join", joiner) # 開始ノードの指定 graph_builder.set_entry_point("plan_and_schedule") # エッジ(ノード間の遷移)の定義 graph_builder.add_edge("plan_and_schedule", "join") # plan_and_schedule -> join def should_continue(state: List[BaseMessage]): if isinstance(state[-1], AIMessage): return END return "plan_and_schedule" # 条件付きエッジの定義 graph_builder.add_conditional_edges( "join", lambda state: "END" if isinstance(state[-1], AIMessage) else "plan_and_schedule", { "END": END, # join -> END (正常終了) "plan_and_schedule": "plan_and_schedule" # join -> plan_and_schedule (再計画) } ) graph = graph_builder.compile()
以降では plan_and_schedule ノードを取り上げてみてみます。
import itertools @as_runnable def plan_and_schedule(messages: List[BaseMessage], config): tasks = planner.stream(messages, config) tasks = itertools.chain([next(tasks)], tasks) scheduled_tasks = schedule_tasks.invoke( { "messages": messages, "tasks": tasks, }, config, ) return scheduled_tasks
Planner からストリーム生成されたタスク系列を用いて schedule_tasks 関数を呼び出しています。
初めのタスクを next(tasks) で切り分けて itertools.chain で tasks と連結することで planner の実行をすぐに開始することが可能になります(らしい)。
以降では planner と schedule_tasks の順序でそれぞれ深掘りします。
Planner
ここでは検索器と計算機の 2 つツール利用を想定します。
from langchain_openai import ChatOpenAI from langchain_community.tools.tavily_search import TavilySearchResults calculate = get_math_tool(ChatOpenAI(model="gpt-4-turbo-preview")) search = TavilySearchResults( max_results=3, description='tavily_search_results_json(query="the search query") - a search engine.', ) # 検索, 計算ツールを利用 tools = [search, calculate]
計算機は LLM を解釈器として採用しており numexpr.evaluate() を用いて評価可能な記号列を生成します。
>>> calculate.invoke({"problem": "What's the temp of sf + 5?", "context": ["The temperature of sf is 32 degrees"]})
37
Planner のプロンプトを定義します。
from langchain import hub prompt = hub.pull("wfh/llm-compiler")
システムプロンプトを切り出して日本語に翻訳したものが以下になります。
ユーザからクエリ要求が与えられた場合、最大限の並列化で要求を解決するための計画を立案します。
各計画は次の {num_tools} 種類のアクションで構成される必要があります:
{tool_descriptions}
{num_tools}. join(): 前のアクションからの結果を収集し結合します。
- join() を呼び出すと、LLMエージェントはユーザークエリを最終的に決定するか、計画が実行されるまで待機します。
- join は常に計画内の最後のアクションである必要があり、次の2つのシナリオで呼び出されます:
(a) 出力を収集して最終的な応答を生成するタスクから出力を集めることで答えが決定できる場合。
(b) 計画を実行する前に答えが計画フェーズで決定できない場合。Guideline:
- 上記の各アクションには入力/出力タイプと説明が含まれています。
- 各アクションは、入力と出力のタイプに厳密に従う必要があります。
- アクションの説明にはガイドラインが含まれます。アクションを使用する際は、ガイドラインに厳密に従います。
- 計画中の各アクションは、上記の種類のいずれかに厳密に従います。各アクションはPythonの規約に従ってください。
- 各アクションは一意な ID を持ちます (MUST)。
- アクションの入力は、定数でも先行するアクションからの出力でも構いません。後者の場合、$idという書式を使って、出力が入力となる前のアクションのIDを表します。
- 常に計画の最後のアクションとして join を呼び出します。join を呼び出した後は '<END_OF_PLAN>' を出力して下さい。
- 計画が最大限に並列化されていることを確認します。
- 提供されたアクションタイプのみを使用します。これらを使用してクエリを対処できない場合は、次の手順のために join アクションを呼び出します。
- 提供されたアクション以外の新しいアクションを導入しないでください。
Planner は以下のように定義されます。
再計画の処理については本記事では省略しますが、should_replan 関数で計画 or 再計画の判定を行います。
from langchain_core.runnables.base import RunnableSequence llm = ChatOpenAI(model="gpt-4-turbo-preview") planner: RunnableSequence = ( RunnableBranch( # should_replan が True を返す場合、再計画を実施 (should_replan, wrap_and_get_last_index | replanner_prompt), # should_replan が False を返す場合、計画を立案 wrap_messages | planner_prompt, ) | llm | LLMCompilerPlanParser(tools=tools) )
ここでは以下を JSONL 形式で出力してみます。
planner.stream([HumanMessage(content="東京タワーの高さとスカイツリーの高さの差を2で割ると何メートルですか?")])
{'idx': 0, 'tool': TavilySearchResults(description='tavily_search_results_json(query="the search query") - a search engine.', max_results=3), 'args': {'query': '東京タワーの高さ'}, 'dependencies': [], 'thought': None}
{'idx': 1, 'tool': TavilySearchResults(description='tavily_search_results_json(query="the search query") - a search engine.', max_results=3), 'args': {'query': 'スカイツリーの高さ'}, 'dependencies': [], 'thought': None}
{'idx': 2, 'tool': StructuredTool(name='math', description='省略', args_schema=<class 'pydantic.v1.main.mathSchema'>, func=<function get_math_tool.<locals>.calculate_expression at 0x7ce52ca5b5b0>), 'args': {'problem': '($1 - $0) / 2', 'context': ['$1', '$0']}, 'dependencies': [1], 'thought': None}
{'idx': 3, 'tool': 'join', 'args': (), 'dependencies': [1, 2], 'thought': None}
ここで idx=2 の dependencies を見ると [1] が割り当てられています。
これは args に含まれる 0 を除く $d の値を依存関係として取得しているためで、idx=1 の「スカイツリーの高さ」を取得しないと idx=2 のタスクが実行できないことを表しています。なお join では range(1, idx) が依存関係となるため、ここでは [1,2] が依存関係となります。
schedule_tasks
schedule_tasks 関数では ThreadPoolExecutor を用いて複数のタスク系列を並列処理します。
@as_runnable def schedule_tasks(scheduler_input: dict) -> List[FunctionMessage]: """ Group the tasks into a DAG schedule. """ # 再計画が実施された場合、以前の計画に依存する呼び出しがあるため過去のツール実行の結果を保持しておく。 observations = _get_observations(scheduler_input["messages"]) # 過去のツール実行の結果を {idx: 結果} として返す original_observations = set(observations) # ユニークな key 一覧を取得 # 複数のスレッドで同時に関数を実行 task_names = {} futures: List[Future] = [] with ThreadPoolExecutor() as executor: for task in scheduler_input["tasks"]: deps = task["dependencies"] # ツール名を取得 task_name = task["tools"] if isinstance(task["tool"], str) else task["tool"].name task_names[task["idx"]] = task_name # 未完了な依存関係する場合 → タスクをキューに追加 if deps and any([dep not in observations for dep in deps]): futures.append( executor.submit(schedule_pending_task, task, observations, retry_after) ) # 依存関係が存在しない or 依存関係が全て終了している場合 → タスクを実行 else: schedule_task.invoke(dict(task=task, observations=observations)) # 各 Future インスタンスの完了を待つ wait(futures) # ツール実行の結果を更新する new_observations = { k: (task_names[k], observations[k]) for k in sorted(observations.keys() - original_observations) } # ツール実行の結果を FunctionMessage として定義 tool_messages = [ FunctionMessage(name=name, content=str(obs), additional_kwargs={"idx": k}) for k, (name, obs) in new_observations.items() ] return tool_messages
依存関係を持つタスクに適用される schedule_pending_task は以下のように記述されており、依存関係を持つタスク系列において依存先のタスク実行が完了されるのを待ちます。
def schedule_pending_task( task: Task, observations: Dict[int, Any], retry_after: float = 0.2 ): while True: deps = task["dependencies"] # 未完了な依存関係する場合 if deps and (any([dep not in observations for dep in deps])): time.sleep(retry_after) continue # 依存関係が存在しない or 依存関係が全て終了している場合 schedule_task.invoke({"task": task, "observations": observations}) break
Plan-and-Solve Agent, ReWOO では立案されたタスク系列を逐次実行していましたが、LLM Compiler では依存関係を考慮することで並列実行を可能にしています。
以上が LLM Compiler のキモとなる箇所の紹介になりますが、実装の詳細を知りたい方は以下をご参照ください。
おわりに
本記事では、LangGraph における Plan-and-Execute Agents の実装紹介ブログを元に、Plan-and-Solve Prompting, ReWOO, LLM Compiler について紹介しました。
今後も LLM エージェントやマルチエージェントシステム等についての技術発信をしていこうと思います。 ぜひブックマークしていただけると大変励みになります。
また Algomatic では LLM を活用したプロダクト開発等を行っています。
LLM を活用したプロダクト開発に興味がある方は、下記リンクからカジュアル面談の応募ができるのでぜひお話ししましょう!
参考
- Dory氏 - 新たなトレンド「AIエージェント」がもたらす未来のユーザ体験
- Dory氏 - AI時代のユーザ体験は「AAAA」モデルで考えよう
- 西見公宏氏 - エージェント型AIシステム構築の7つの原則: OpenAI『Practices for Governing Agentic AI』を読み解く
- 西見公宏氏 - その仕事、AIエージェントがやっておきました。 ――ChatGPTの次に来る自律型AI革命
- 太田真人氏+'23 - LLMマルチエージェントを俯瞰する
- 大嶋勇樹氏+'24 - いまこそ学ぶLLMベースのAIエージェント入門―基本的なしくみ/開発ツール/有名なOSSや論文の紹介
- ブレインパッド DOORS編集部+'23 - 自律型AIエージェントのご紹介
- Prompt Engineering Guide - LLM Agents
- Lillian氏+'23 - LLM Powered Autonomous Agents
- NVIDIA Technical Blog - Introduction to LLM Agents
