こんにちは。LLM STUDIO 機械学習エンジニアの宮脇(@catshun_)です。 本記事では最近注目を集めている AI ソフトウェアエンジニアに関するプロダクトについてざっくりと紹介します。
社内勉強会に向けたキャッチアップ資料として作成しており、加筆修正する可能性がありますが、本記事を読んだ方の議論のネタ程度になってくれれば幸いです。
おことわり
- 本記事では AI ソフトウェアエンジニアに関する 詳細な解説は含みません。
- Devin を参考に AI ソフトウェアエンジニアと呼称していますが、主語が大きく曖昧性の高い表現を使用しています。詳細については 参照元をご確認ください。
- 不十分また不適切な言及内容がございましたらご指摘いただけますと幸いです。
- プロダクト等の利用時は 必ずライセンスや利用規約を参照して下さい。
本記事の目次
プログラム生成を伴う推論
はじめの 4 つは、著者が以前 Geography & Language Study Group 勉強会 #04 にて発表したスライドからの引用です。
Self-Refine (Madaan+'23, NeurIPS)

Self-Repair (Olausson+'23)

Self-Edit (Zhang+'23, ACL)

Self-Evolve (Jiang+'23)

CodeAct (Wang +’24)
CodeAct は、行動をコードとして記述するエージェント型の推論フレームワークです。行動を記述する中間媒体が、テキストや JSON である ReAct や関数呼び出し型の推論フレームワークとは異なり、事前定義されたツールの使い方・使い所をコードとして記述する ことで、対象タスクを解く上でのユーザインタラクション回数を削減します。また CodeVQA (Subramanian +’23) に近い推論方法ですが、コード実行およびヒトからの FB を反映したマルチターンの反復改良型エージェントを採用している点で異なります。

フィードバックを伴うコード生成と推論
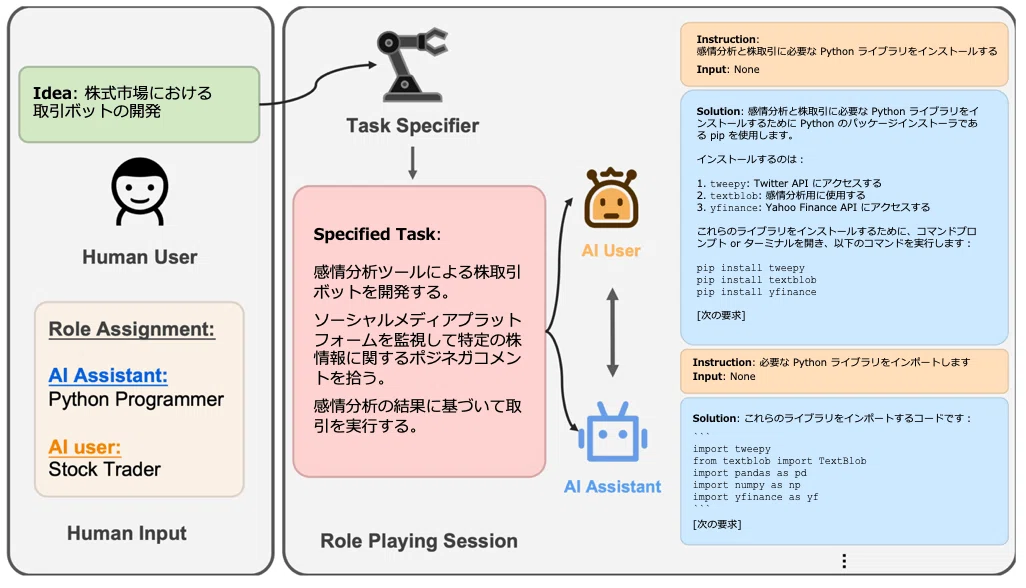
CAMEL (Li+'23)
CAMEL はロールプレイ型の対話を採用した推論フレームワークで、ユーザからのタスク要求を解決するために AI User と AI Assistant の役割が付与された 2 つの言語生成器がコード生成等を伴う対話を展開します。
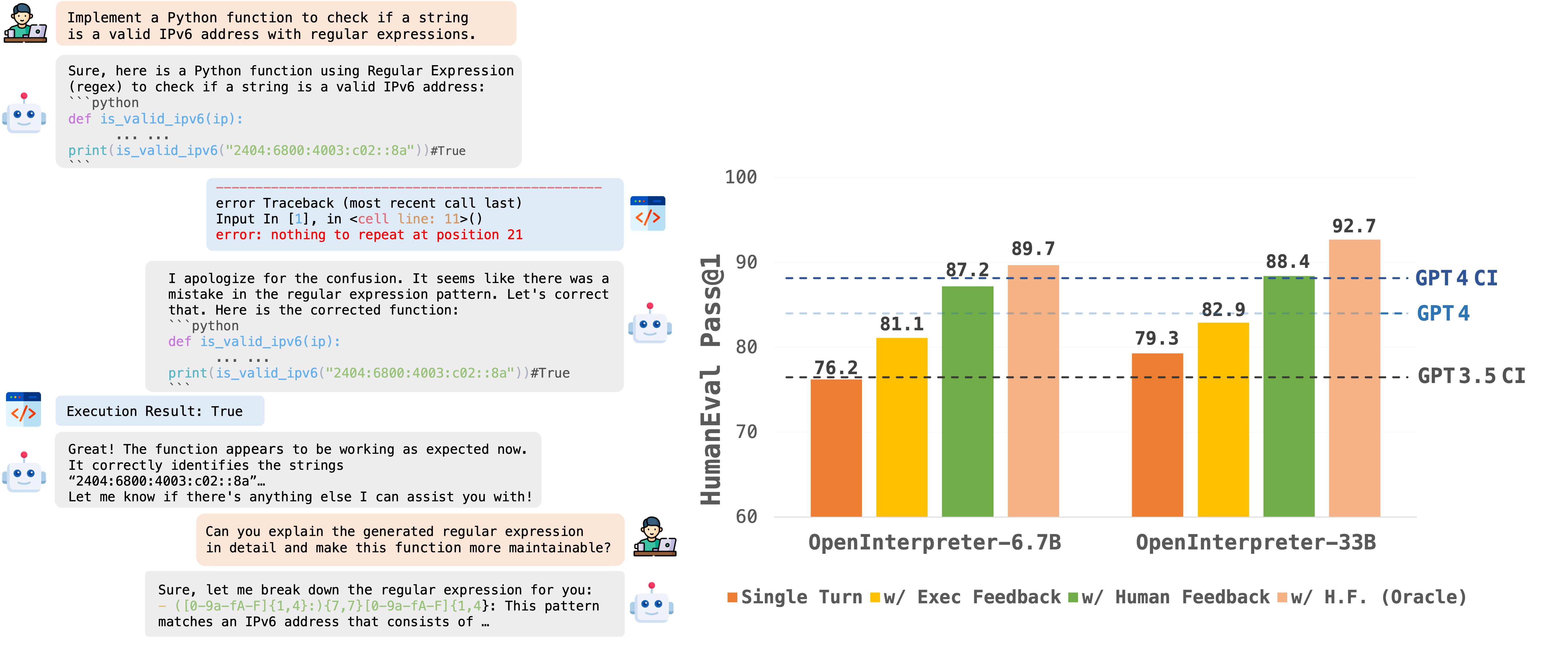
OpenCodeInterpreter (Zheng+'24)
OpenCodeInterpreter は、CodeInterpreter のようなコード生成・実行と反復改良を行うシステムで、CodeInterpreter とは異なりオープンソースとして公開されています。著者らは新たに ユーザ・インタープリタ・コード生成モデル間の複数ターンの対話データを収集した CodeFeedback と呼ばれるデータセットで CodeLlama (Roziere+'23), DeepSeekCoder (Guo+'24) をベースモデルとして学習しています。
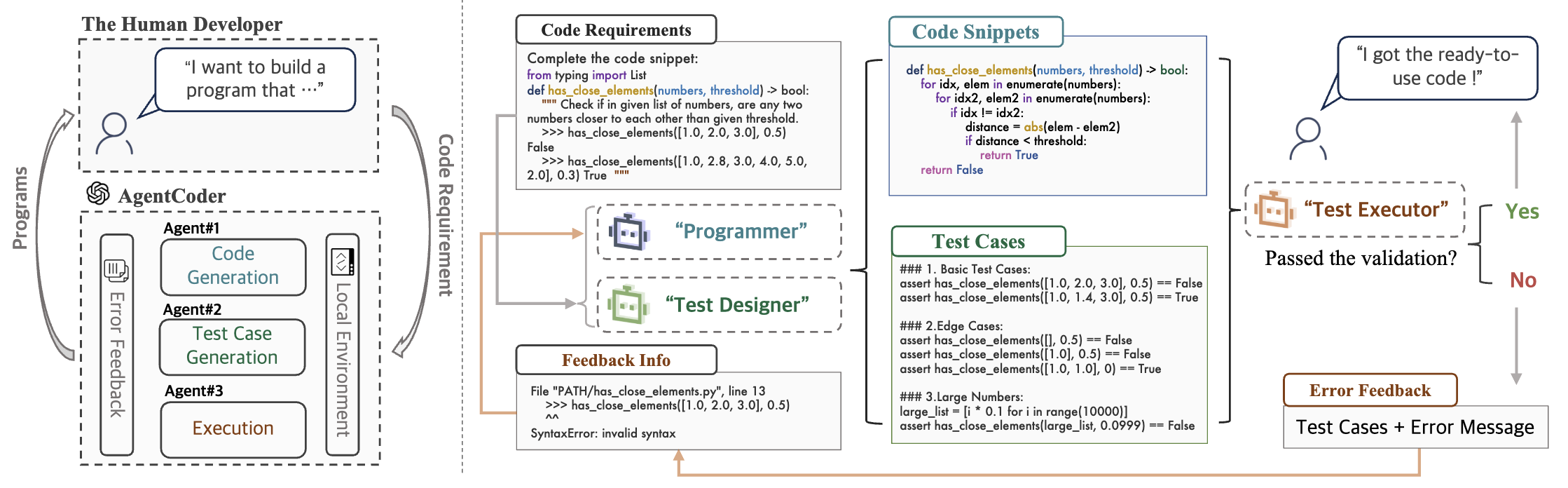
AgentCoder (Huang+'23)
AgentCoder はプログラマ、テスト設計者、テスト実行者の 3 つのエージェントで構成されるマルチエージェント型の推論フレームワークです。❶ プログラマは特定のタスクを解決するため、問題の把握・明瞭化・アルゴリズムやメソッドの選択・擬似コード生成・コード生成による思考の連鎖を伴うコード生成を実行します。またコード実行が失敗した際のコード修正の役割も担っています。❷ テスト設計者は {基本的な, エッジとなる, 大規模な入力を伴う} テストケースを生成します。❸テスト実行者はローカル環境でテストを実行し、合否に応じてユーザおよびプログラマにその結果を返します。
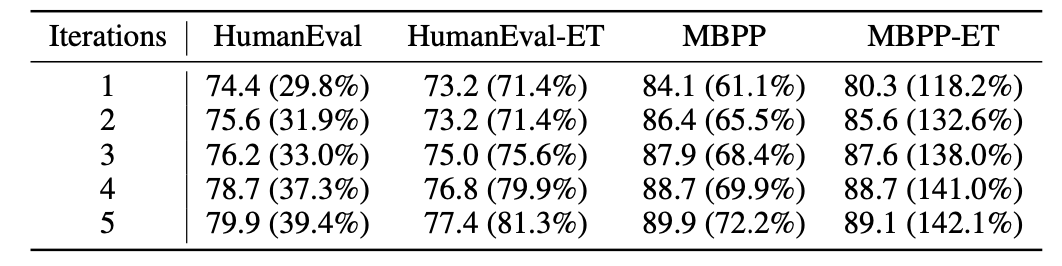

ソフトウェアエンジニアリング
ここからはソフトウェア開発やデータ分析など、エンジニアとして要求されるより広義なタスクに関するフレームワークを紹介します。
ChatDev (Qian+'23)
ChatDev は、ソフトウェアテクノロジにおける開発組織を模倣したマルチエージェント型のソフトウェア開発システムです。各エージェントの役割は CEO, CTO, Programmer, Tester など様々で、ウォーターフォール型の開発モデルを採用することで各フェーズごとに任命されたエージェントがサブタスクとして実行し、ユーザからのタスク要求を満たします。
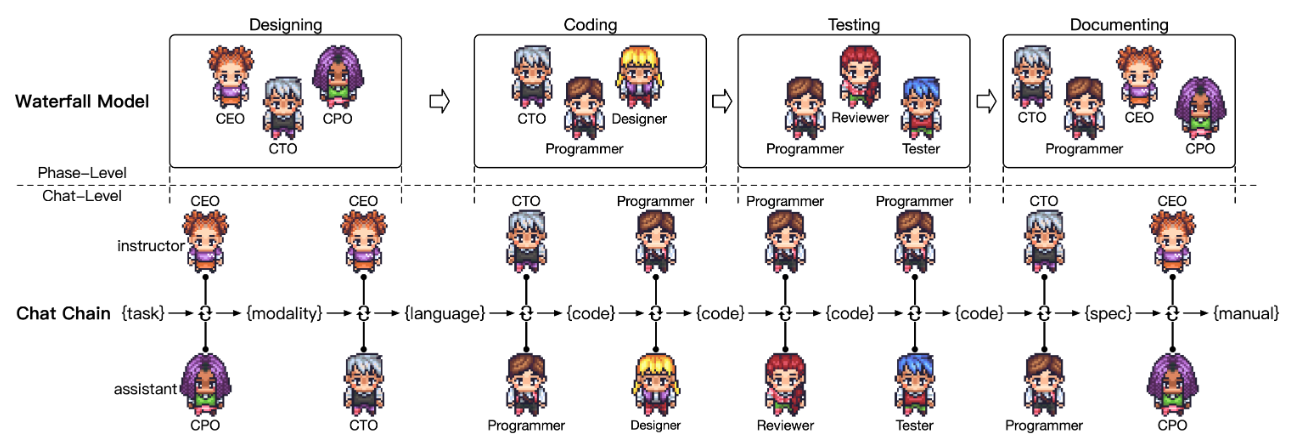
以下の解説記事が参考になりますので、詳細はこちらを参照して下さい。 ai-scholar.tech
MetaGPT (Hong+'24, ICLR)
MetaGPT はマルチエージェント型のソフトウェア開発システムであり、標準作業手順書 (SOPs) を用いたメタプログラミングによる推論を採用しています。CAMEL, ChatDev と異なり、エージェントは厳格な作業手順に従い構造化文書 (要求定義書, 設計成果物, フローチャート, インターフェース仕様など) を生成します。
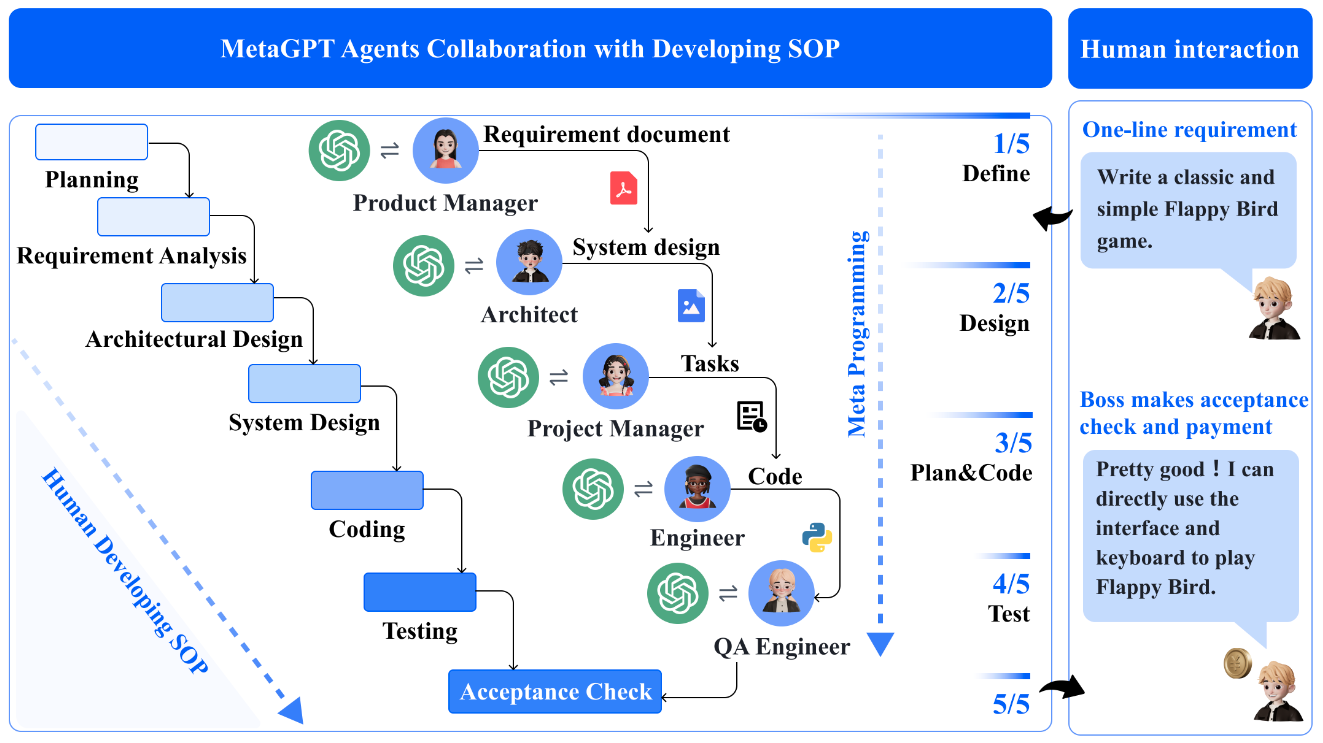
こちらも以下の解説記事が参考になりますので、詳細はこちらを参照して下さい。 ai-scholar.tech
Devin
Devin は 2024.03.12 に Cognition から発表された AIソフトウェアエンジニア です。
もう少し丁寧に説明すると、ソフトウェアエンジニアリングで要求されるタスク等を実行するために設計された自律型エージェントで、シェル・コードエディタ・ウェブブラウザにアクセス可能なツールを組み込むことで、コード生成や修正を伴う推論を実行します。
2024.04.03 現在は、公開待ち (waiting list) となっており、デモ動画 と SWE-bench におけるテクニカルレポート が公開されています。
デモ動画 では、以下のようなクエリを Devin に入力しています。
Hey Devin, I’d like for you to benchmark Llama 2 on three different providers: Replicate, Together, Perplexity. Figure out their API formats and write a script that sends the same prompt/ params to all of them.
動画内にて Devin はクエリを受け取ると、タスク要求を満たすような計画をはじめに立案しています。計画立案後、Devin はブラウザから API ドキュメントを取得してクエリ要求を満たすための処理を実行します。実行エラーに遭遇すると実行ログからコードエディタにアクセスしてバグを修正し、修正後はクエリ要求に対する実行結果を表示するためのサイトをデプロイしています。
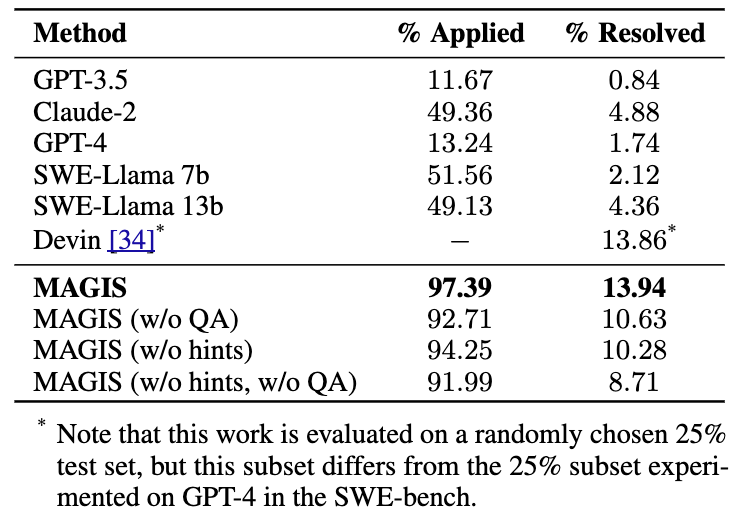
SWE-bench における評価
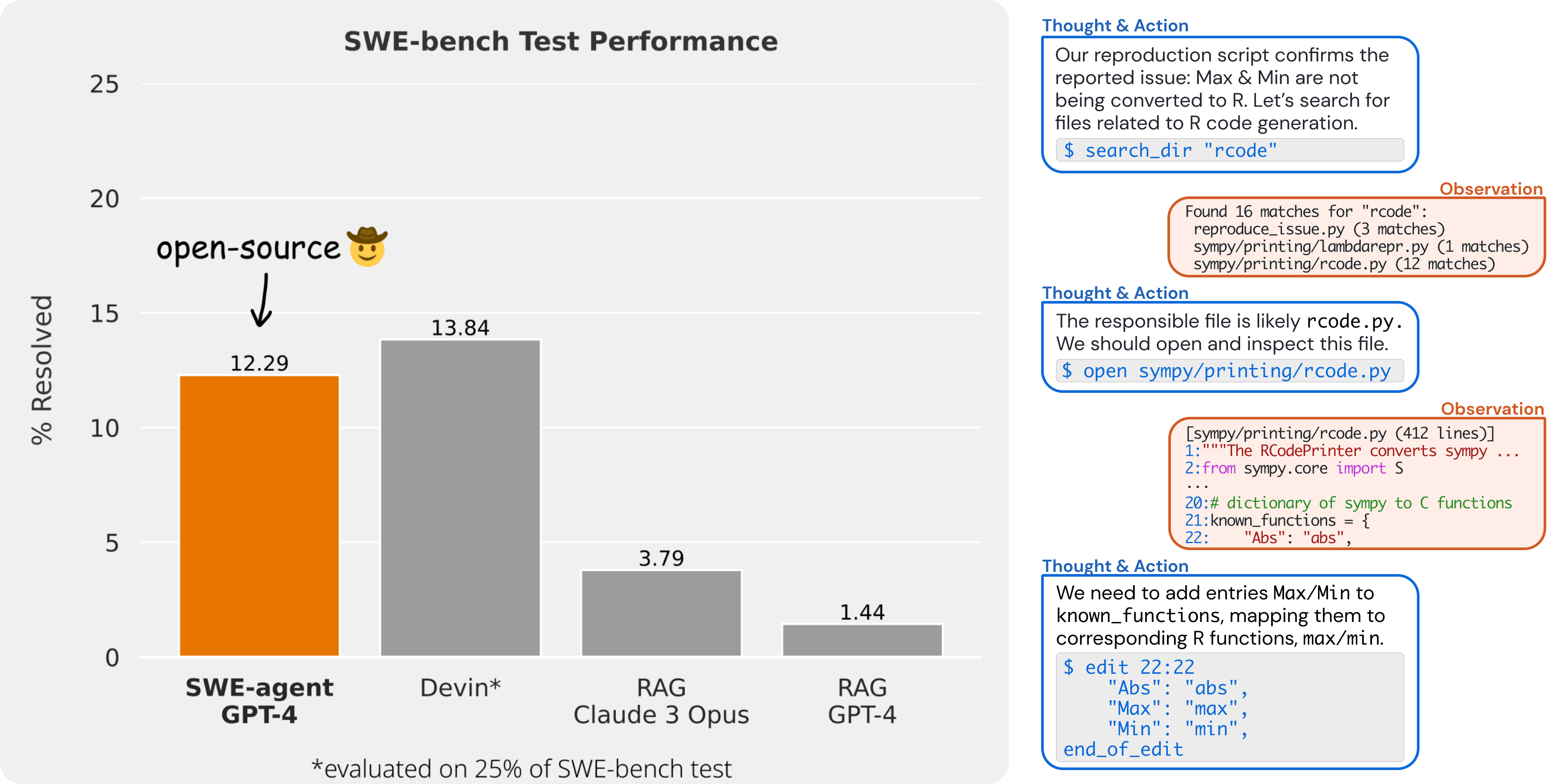
Devin が注目を集めるきっかけとなった一つの要因は SWE-bench において、既存の Claude 2 や GPT-4 を大幅に凌駕する結果を示したことでしょうか。
ただレポートでも言及されていますが、Devin はおそらく内省やツール呼び出しを含む反復改良型のエージェント設定であり Claude 2, GPT-4 と精緻な比較が出来ていない可能性があるかもしれません。また評価結果については SWE-bench のみが言及されており、横断的な評価が出来ていない点も留意する必要があります。
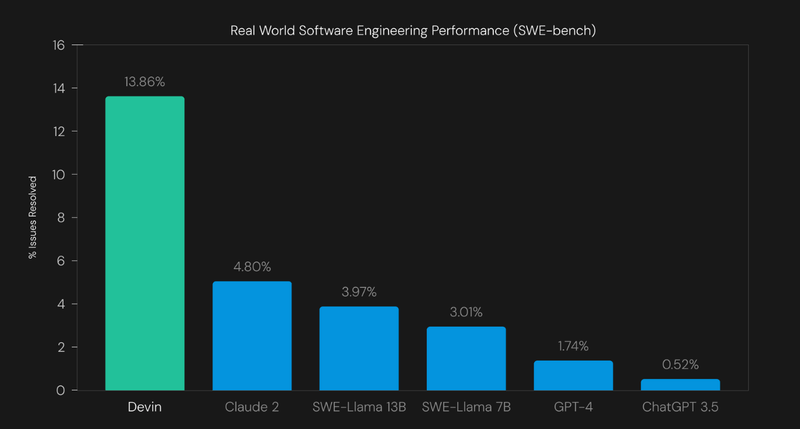
--- SWE-bench について簡単な補足です。
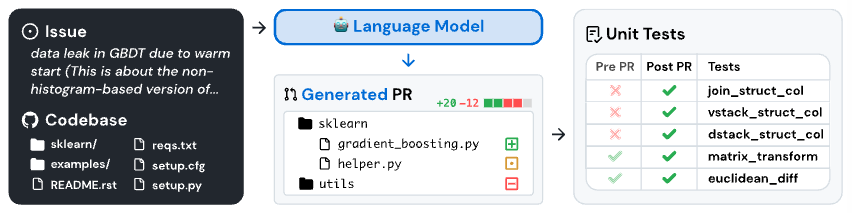
SWE-Bench (Jimenez+'24, ICLR) は、現実世界のコードを作成するシステムの能力を評価することを目的として、GitHub 上の人気のオープンソース Python リポジトリから収集された 2,294 件の issues, プルリクエスト (PR) から構成されるデータセットです。PR には単体テストを含める必要があり、コード変更前は失敗、変更後は合格するようなテストが含まれます。

Devika
Devika は Devin のような AI ソフトウェアエンジニアで、 Devin に代わるオープンソース化を目的に 2024.03.21 (あたり) に公開されました。ユーザからの指示をサブタスクに分解し、関連情報を調査し、要求タスクを達成するためのコードを記述します。
現在進行形で開発中のプロダクトで、以下のように記述されています。
This project is currently in a very early development/experimental stage. There are a lot of unimplemented/broken features at the moment. Contributions are welcome to help out with the progress!
OpenDevin
OpenDevin も Devika 同様、2024.03.27 (あたり) に公開されたオープンソースの AI ソフトウェアエンジニアです。シェル・コードエディタ・ウェブブラウザ等のツールを利用することで、ユーザからのタスク要求に取り組みます。
Devika との差分について明示な言及はありませんが、観測に基づくいくつかの差分が 投稿 されたりしています。
SWE-agent
SWE-agent も同様に AI ソフトウェアエンジニアと呼ばれていますが、SWE-bench における評価が行われており、12.29 %の解決率を示しています(実験設定については公開予定の論文をご確認ください)。
AutoCodeRover (Zhang+'24)
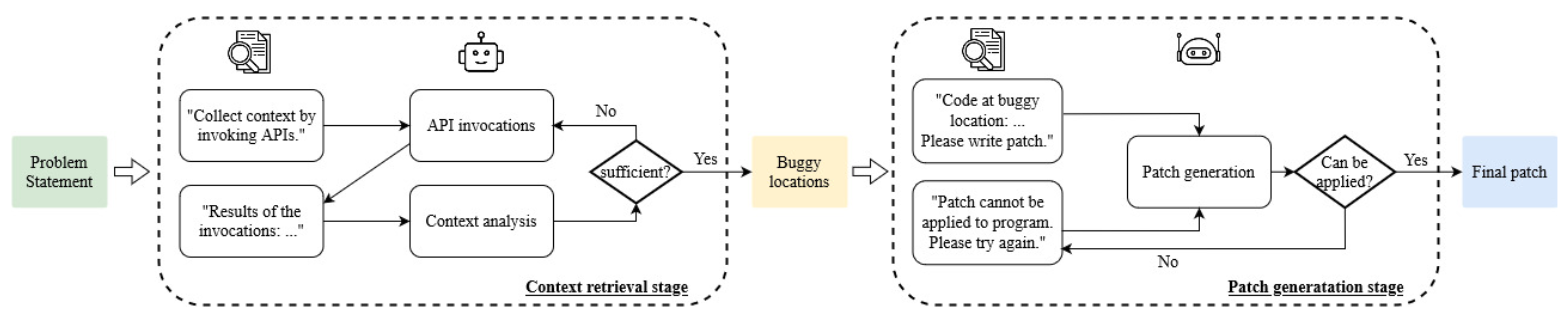
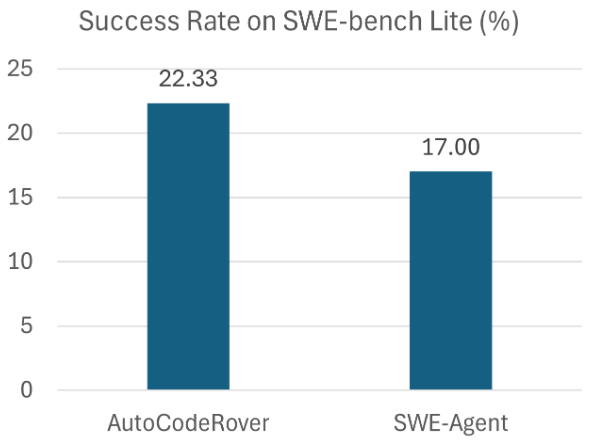
AutoCodeRover は、GitHubの課題解決(バグ修正と機能追加)を完全に自動化したアプローチで、LLMと分析およびデバッグ機能を組み合わせて、最終的にパッチを適用する場所の優先順位を決定します。
300の実際のGitHub課題から構成されるSWE-bench liteにおいて、AutoCodeRoverは課題の~22%を解決し、AIソフトウェアエンジニアの現在の最先端の有効性よりも向上しています。
AutoDev (Tufano+'24)
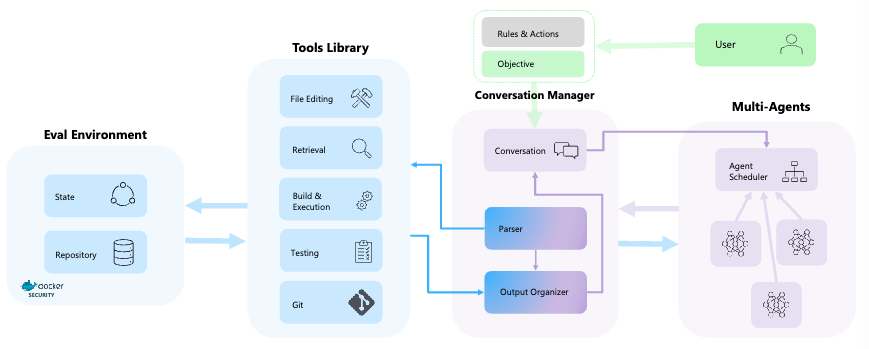
AutoDev は、複雑なソフトウェアエンジニアリングタスクの自律的な計画と実行のために設計された、自律駆動型のソフトウェア開発フレームワークです。ユーザはエージェントの数と動作を定義し特定のプロファイルや実行可能な行動を選択することが可能で、ファイル編集、検索、スクリプト実行、テスト、Github 操作など、コードベース上で様々な操作を選択できます。
AutoDev の構成要素は 4 つで、ユーザとエージェントの対話履歴を管理する Conversation Manager、様々なコードやツールが含まれる Tools Library、複数のエージェントのオーケストレーションを担当する Agent Scheduler、コードとテストの実行機能を有する Eval Environment から構成されます。
MAGIS (Tao+'24)
MAGIS は、GitHub issue の解決を行うマルチエージェント型の推論フレームワークで、ソフトウェア開発を行うためカスタマイズされた (Manager, Repository Custodian, Developer, Quality Assurance Engineer) の 4 つのエージェントで構成されます。
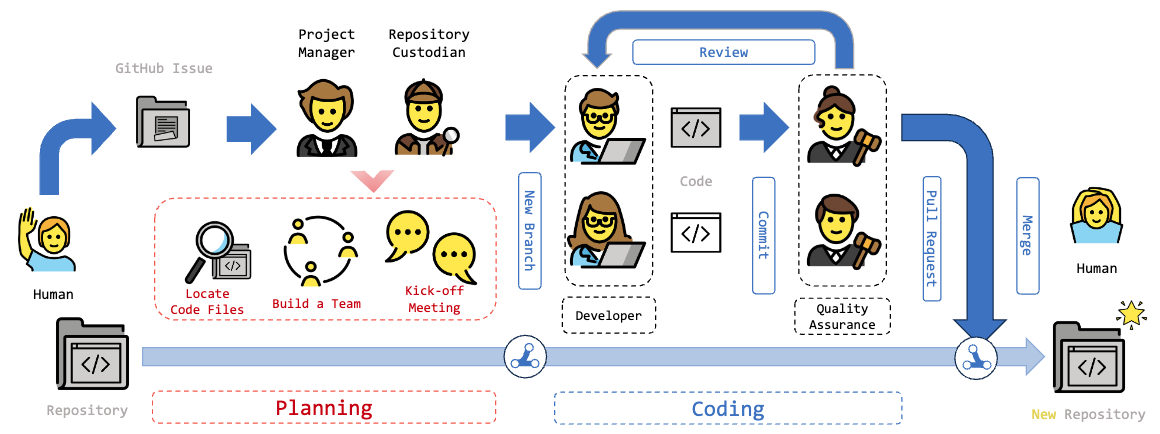
データ分析
TaskWeaver (Qiao+'23)
TaskWeaver は、ユーザからのタスク要求を実行可能なコードに変換し、ユーザが事前に定義したプラグインを関数として呼び出しながら推論を行うコード生成を伴うインタラクティブなチャットフレームワークです。
ユーザからのタスク要求をサブタスクに分解する Planner、関連するプラグインの関数名・説明・引数・戻り値を含む定義からサブタスクを解決するためのコード生成を行う Code Generator、生成されたコードを実行する Code Executor の 3 つのコンポートで構成されてます。
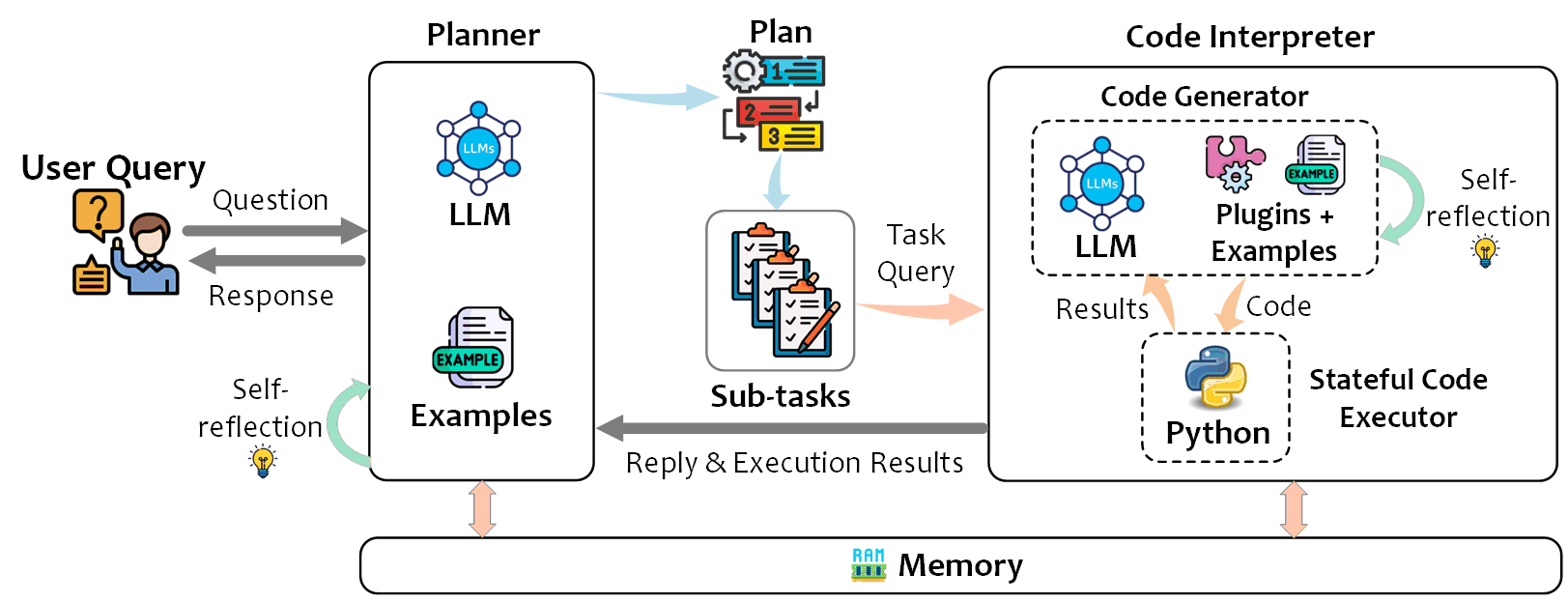
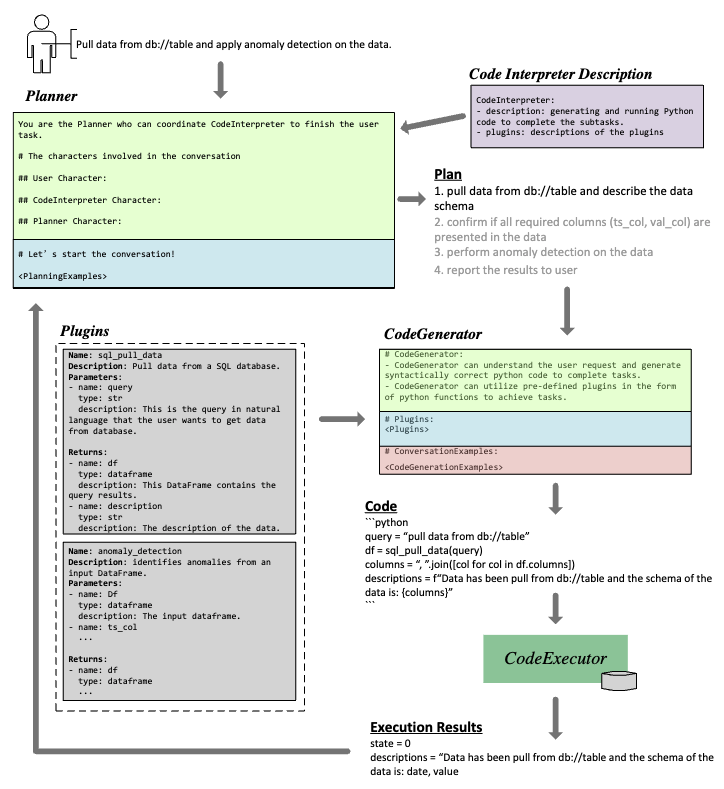
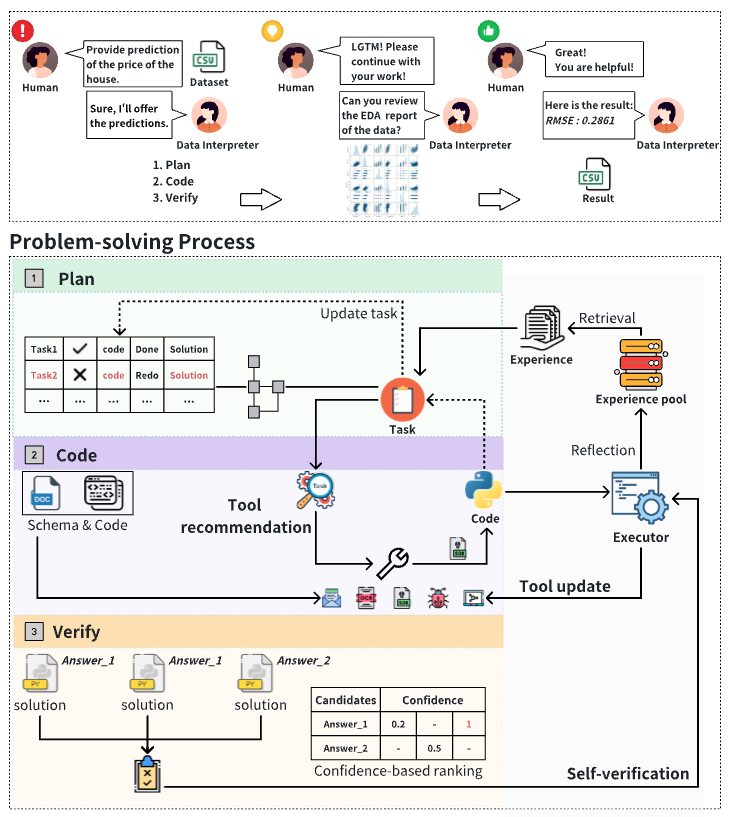
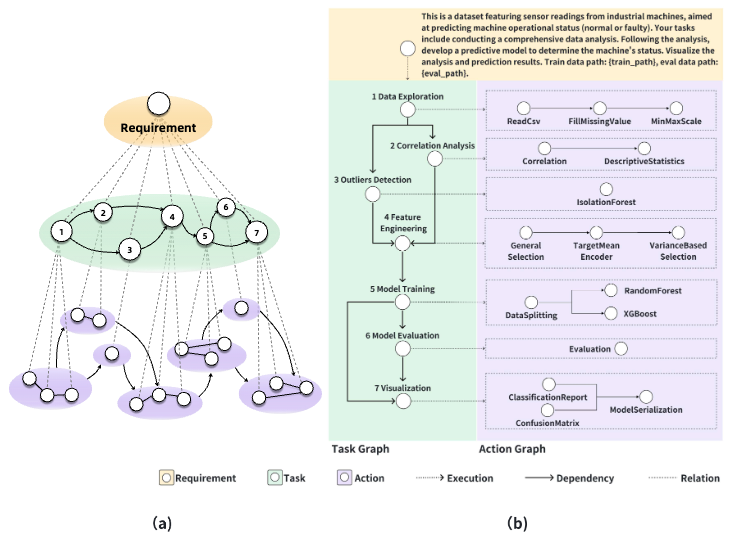
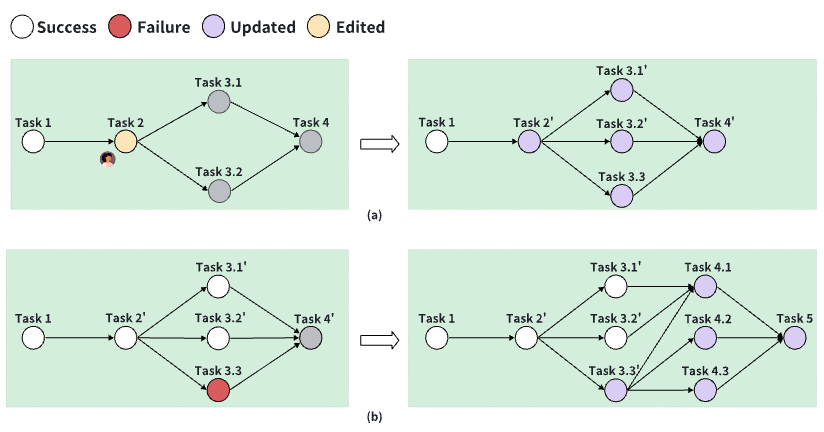
Data Interpreter (Hong+'24)
Data Interpreter は、データサイエンスの問題解決を目的としたコード生成を伴う LLM エージェントです。タスク要件を静的に分解する TaskWeaver, Code Interpreter, OpenInterpreter と異なり、よりデータ分析におけるワークフローに沿ったコーディング計画と計画の再定義を行います。
おわりに
Devin についてはデモ動画や SWE-Bench のテクニカルレポートが公開されているだけなので、その有効性については今後公開されたものを実際に触ってみたタイミングで判断したいと思います。また本文では言及しませんでしたが、Magic.dev, Code Repair, codium.ai なども関連するプロダクトになるかと思うので、引き続き注目しきたいと思います。
ここまで読んでいただきありがとうございました。Algomatic では LLM を活用したプロダクト開発等を行っています。 LLM を活用したプロダクト開発に興味がある方は、下記リンクからカジュアル面談の応募ができるのでぜひお話ししましょう!
参考
- Yang+'24 - If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
- Language Models: Surveying the landscape of diverse self-correction strategies
- PFN Blog - Large Language Models for Code (Code LLMs)と自然言語推論、ソースコードの関係について
