こんにちは。Algomatic の宮脇(@catshun_)です。 本記事では文書検索において一部注目された BGE M3-Embedding について簡単に紹介します。
おことわり
- 本記事では精読レベルの 詳細な解説は含みません。
- 詳細については 参照元の論文をご確認ください。
- 不十分また不適切な言及内容がございましたらご指摘いただけますと幸いです。
- プロダクト等の利用時は 必ずライセンスや利用規約を参照して下さい。
- 本記事で紹介する 論文 は Work in progress とコメントされており今後内容が更新される可能性があります。
まずは動かしてみる
github.com/FlagOpen/FlagEmbedding の Usage を参考に Colab 上で動かしてみました。 なお可読性を上げるために小数点を一部切り上げて表示しています。
$ pip install FlagEmbedding==1.2.8
まずはモデルを定義します。今回は CPU 上での実行を想定しています。
from FlagEmbedding import BGEM3FlagModel model_name_or_path = "BAAI/bge-m3" bge_m3 = BGEM3FlagModel(model_name_or_path, use_fp16=False, device="cpu")
検索対象となる文書 (passages) とクエリ (query) を定義します。
passages = [
"生成AIに特化した受託開発・コンサルティングを行う新部門「Algomatic 生成AI Partner」を設立",
"Algomaticが東京都庁「文章生成AI活用事例集」に生成AIの知見を提供 ",
"法人・自治体向けChatGPT「シゴラクAI」が「AIsmiley PRODUCTS AWARD 2024 WINTER」受賞"
]
query = "生成AIパートナー"
query_passage_pairs = [[query, passage] for passage in corpus]
BGEM3FlagModel.compute_score を実行してスコアを算出します。
# 0.4 * dense_score + 0.2 * sparse_score + 0.4 * colbert_score weights_for_different_models = [0.4, 0.2, 0.4] scores = bge_m3.compute_score( query_passage_pairs, max_passage_length=128, weights_for_different_modes=weights_for_different_models )
>>> scores
{'colbert': [0.7729, 0.630, 0.5138],
'sparse': [0.1281, 0.0947, 0.0671],
'dense': [0.7108, 0.5818, 0.5128],
'sparse+dense': [0.5166, 0.4195, 0.3642],
'colbert+sparse+dense': [0.6191, 0.5039, 0.4241]}
argsort により類似度順にソートすることができます。
import numpy as np def sort_passages(functionality:str="colbert+sparse+dense", top_k:int=3): related_passages = [] for i, pix in enumerate(np.argsort(scores[functionality])[::-1][:top_k]): related_passages.append({"top_k": i, "passage": passages[pix], "score": scores[functionality][pix]}) return related_passages
>>> sort_passages(related_passages)
[{'top_k': 0,
'passage': '生成AIに特化した受託開発・コンサルティングを行う新部門「Algomatic 生成AI Partner」を設立',
'score': 0.6191},
{'top_k': 1,
'passage': 'Algomaticが東京都庁「文章生成AI活用事例集」に生成AIの知見を提供 ',
'score': 0.5039},
{'top_k': 2,
'passage': '法人・自治体向けChatGPT「シゴラクAI」が「AIsmiley PRODUCTS AWARD 2024 WINTER」受賞',
'score': 0.4241}]
文書集合のエンコード
ベクトル DB を用いたオフライン検索では、検索対象となる文書を事前にエンコードする必要があります。
passages_embeddings = bge_m3.encode(passages, return_dense=True, return_sparse=True, return_colbert_vecs=True)
BGEM3FlagModel.encode の戻り値は dense_vecs, lexical_weights, colbert_vecs のキーを持つ dict 形式のデータとなります。
>>> passages_embeddings.keys() dict_keys(['dense_vecs', 'lexical_weights', 'colbert_vecs'])
dense_vecs
dense_vecs は BGEM3Model.dense_embeddings から明らかであるように、CLS トークンの隠れ表現であり 1024 次元のベクトルとなります。
>>> type(passages_embeddings["dense_vecs"]) numpy.ndarray >>> passages_embeddings["dense_vecs"].shape (3, 1024) # passages 数 × 1024 次元
dense_vecs を用いた類似度の算出は BGEM3Model.dense_score で以下のように定義されます。
# 一部省略して表示しています class BGEM3Model(nn.Module): def compute_similarity(self, q_reps, p_reps): if len(p_reps.size()) == 2: return torch.matmul(q_reps, p_reps.transpose(0, 1)) return torch.matmul(q_reps, p_reps.transpose(-2, -1)) def dense_score(self, q_reps, p_reps): scores = self.compute_similarity(q_reps, p_reps) / self.temperature scores = scores.view(q_reps.size(0), -1) return scores
lexical_weights
後ほど簡単に紹介しますが、lexical_weights は各トークンにスカラ値を割り当てることで語彙数次元の疎なベクトル表現を構築します。実際にはエンコード時に文章中に出現したトークンのみを対象に、{トークンID: スカラ値} となる辞書型のデータを返します。
>>> type(passages_embeddings["lexical_weights"]) list >>> type(passages_embeddings["lexical_weights"][0]) collections.defaultdict >>> passage_embeddings["lexical_weights"][0] defaultdict(int, {'125389': 0.2412, '11388': 0.2426, '2657': 0.1286, '1988': 0.1044, '4467': 0.0621, '121086': 0.1474, '47479': 0.1097, '29714': 0.0345, '18078': 0.1369, '5283': 0.0319, '132129': 0.036, '1378': 0.0857, '52483': 0.2234, '6210': 0.0969, '519': 0.1296, '47148': 0.2508, '16424': 0.2486, '76628': 0.1445})
自然言語は計算機が扱えるように id に変換されるため、キーを元のトークンにマッピングして少し見やすくしてみます。
>>> passage = passages[0] >>> tokenizer = bge_m3.tokenizer >>> itos = dict(zip(tokenizer.encode(passage), tokenizer.tokenize(passage, add_special_tokens=True))) >>> {itos[int(i)]:w for i,w in passages_embeddings["lexical_weights"][0].items()} {'生成': 0.2412, 'AI': 0.2426, '特': 0.1286, '化': 0.1044, '受': 0.0621, '託': 0.1474, '開発': 0.1097, 'コン': 0.0345, 'サ': 0.1369, 'ル': 0.0319, 'ティング': 0.0364, '新': 0.0857, '部門': 0.2234, 'Al': 0.0969, 'go': 0.1296, 'matic': 0.2508, '▁Partner': 0.2486, '設立': 0.1445, '<s>': 0, '▁': 0, 'に': 0, 'した': 0, '・': 0, 'を行う': 0, '「': 0, '」': 0, 'を': 0, '</s>': 0}
lexical_weights を用いた類似度の算出は、(入力対象の次元数のみ異なるが) dense_vecs と同様に、 BGEM3Model.sparse_score で以下のように定義されます。
# 一部省略して表示しています class BGEM3Model(nn.Module): def compute_similarity(self, q_reps, p_reps): if len(p_reps.size()) == 2: return torch.matmul(q_reps, p_reps.transpose(0, 1)) return torch.matmul(q_reps, p_reps.transpose(-2, -1)) def sparse_score(self, q_reps, p_reps): scores = self.compute_similarity(q_reps, p_reps) / self.temperature scores = scores.view(q_reps.size(0), -1) return scores
colbert_vecs
colbert_vecs は BGEM3Model.colbert_embeddings より、CLS トークンを除く各トークンの隠れ表現の系列となります。
# passages >>> type(passages_embeddings["colbert_vecs"]) list >>> passages[0] 生成AIに特化した受託開発・コンサルティングを行う新部門「Algomatic 生成AI Partner」を設立 >>> type(passages_embeddings["colbert_vecs"][0]) numpy.ndarray >>> passages["colbert_vecs"][0].shape (30, 1024)
passages[0] のトークン数は 29+2 (CLS, SEP) であり、colbert_vecs のベクトル数は <s> (CLS) 分を除く 30 となります。
>>> tokens = bge_m3.tokenizer.tokenize(passages[0], add_special_tokens=True) >>> " ".join(tokens) <s> ▁ 生成 AI に 特 化 した 受 託 開発 ・ コン サ ル ティング を行う 新 部門 「 Al go matic ▁ 生成 AI ▁Partner 」 を 設立 </s> >>> len(tokens) 31
colbert_vecs を用いた類似度の算出は BGEM3FlagModel.colbert_score で以下のように定義されます。後ほど簡単に紹介しますが ColBERT の類似度の算出方法を採用します。
# 一部省略して表示しています class BGEM3FlagModel: def colbert_score(self, q_reps, p_reps): q_reps, p_reps = torch.from_numpy(q_reps), torch.from_numpy(p_reps) # MaxSim を計算 token_scores = torch.einsum('in,jn->ij', q_reps, p_reps) scores, _ = token_scores.max(-1) scores = torch.sum(scores) / q_reps.size(0) return scores
モデルについて
論文でも言及されていますが BGE M3 のモデルは XLMRoBERTa を使用しています。
# 一部省略して表示しています >>> bge_m3.model BGEM3ForInference( (model): XLMRobertaModel( (embeddings): XLMRobertaEmbeddings(...) (encoder): XLMRobertaEncoder(...) (pooler): XLMRobertaPooler( (dense): Linear(in_features=1024, out_features=1024, bias=True) ) ) (colbert_linear): Linear(in_features=1024, out_features=1024, bias=True) (sparse_linear): Linear(in_features=1024, out_features=1, bias=True) ... )
BGEM3ForInference.forward から明らかであるように、dense_vecs, sparse_vecs, colbert_vecs のそれぞれは XLMRoBERTa から出力される last_hidden_state の 1024 次元の隠れ表現に基づいています。
# 一部省略して表示しています class BGEM3ForInference(BGEM3Model): def forward(self, ...) last_hidden_state = self.model(**text_input, return_dict=True).last_hidden_state output = {} if return_dense: dense_vecs = self.dense_embedding(last_hidden_state, text_input['attention_mask']) output['dense_vecs'] = dense_vecs if return_sparse: sparse_vecs = self.sparse_embedding(last_hidden_state, text_input['input_ids'], return_embedding=return_sparse_embedding) output['sparse_vecs'] = sparse_vecs if return_colbert: colbert_vecs = self.colbert_embedding(last_hidden_state, text_input['attention_mask']) output['colbert_vecs'] = colbert_vecs ...
論文紹介
ここからは論文紹介となります。 誤りや不十分な記述があると思いますので、必ず元論文を参照してください。本記事を読んでくれた方が「ここの議論足りないよね」「本当はこうじゃない?」といった議論を展開していただけると幸いです。
1. どんなもの?
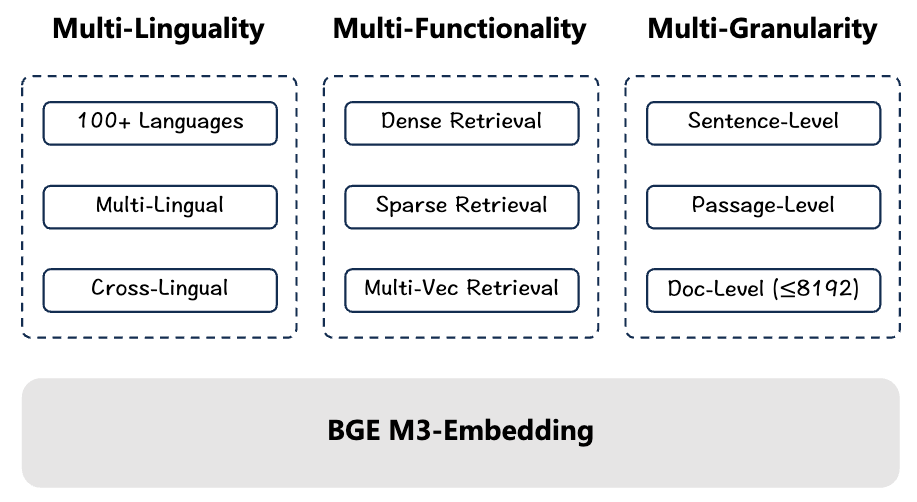
M3 という名前の通り、以下 3 つの特徴を持つ埋め込みモデルを提案しています。
また効果的な学習方法として以下を提案しています。
- Self-knowledge distillation: 異なる functionality からの関連スコアを学習に組み込むアプローチを提案する。
- Efficient batching: 埋め込み対象となる文書をトークン数でグループ化する。また gradient checkpointing を導入したバッチサイズ制限の軽減を実現する。
2. 先行研究と比べてどこがすごい?
一言で回答すると、self-knowledge distillation によって dense retrieval, sparse retrieval, multi-vector retrieval の 3 つの手法を統合した学習を行う点にあるかと思います。
著者曰く dense retrieval, sparse retrieval, multi-vector retrieval の 3 つの手法を統合した埋め込みモデルは (著者が知る限り) これまでになかったそうです。
Multi-linguality, multi-granularity の観点についても大変興味深いですが、ここでは M3-Embedding の嬉しい特徴である multi-functionality に焦点を置いて解説します。
2.1. Functionality に関する先行研究の紹介
一般にクエリから文書を検索する手法については、以下のような様々なものが提案されていますが、中でもベクトル表現を用いた類似度算出に基づく検索は sparse retrieval, dense retrieval, multi-vector retrieval に大別されます。M3-Embedding はベクトル表現を用いた検索におけるこれら 3 つの機能を有する高性能な埋め込みモデルとして提案されています。


2.1.1. Dense retrieval
Dense retrieval はクエリと文書を分散表現として表現したのち、2 つの表現間の関連度をスコアとして算出する検索方法です。
近年では OpenAI Embeddings のような埋め込みモデルを用いてクエリと文書を 1536 次元のベクトルとしてエンコードしたのち、コサイン類似度のような指標でクエリと文書の類似度を表現する方法が広く利用されていますが、このような手法は dense retrieval にあたります。
クエリと文書ベクトルを事前にエンコードすることでベクトル DB を用いたオフライン検索 *3 が可能となるため、大規模な検索に利用されます。
例えば、これらのモデルに代表される DPR (Karpukhin+'20) は以下のような対照学習の枠組みで学習されます。雑に説明すると、{質問, 正例文書, 負例文書} が入力として与えられ、質問と正例文書の類似度を高く、質問と負例文書の類似度を低くするように学習されます。

Dense retrieval は DPR, E5 など広く利用される枠組みの 1 つですが、複数の意味表現を含む文章を 1 つのベクトルとして表現することで contrastive conflicts (Wu+'22) が生じたり、固有表現等の特定のエンティティの考慮が困難であったり (Sciavolino+'21, Ram+'23)、異なるドメインにおける汎化が困難 (Ni+'21, Wang+'22) であることが知られています。
2.1.2. Late-Interaction を伴う Multi-Vector Retrieval
※ 論文中では multi-vector retrieval と表現されているが、本ブログでは複数のベクトルを用いた検索と、late-interaction を伴う複数のベクトルを用いた検索を切り分けて紹介します。
Dense retrieval における問題の 1 つは、各文章に対して [CLS] トークン等の 1 つのベクトルを用いる点にあるとされており、文章中に複数の意味表現が含まれる SQuAD のようなタスクの場合に検索性能が低くなることが知られています (Wu+'22)。これに対して multi-vector retrieval は検索時に複数のベクトル表現を用いることで、より単語や文単位等の細かな粒度で関連度を算出することを目的としています。
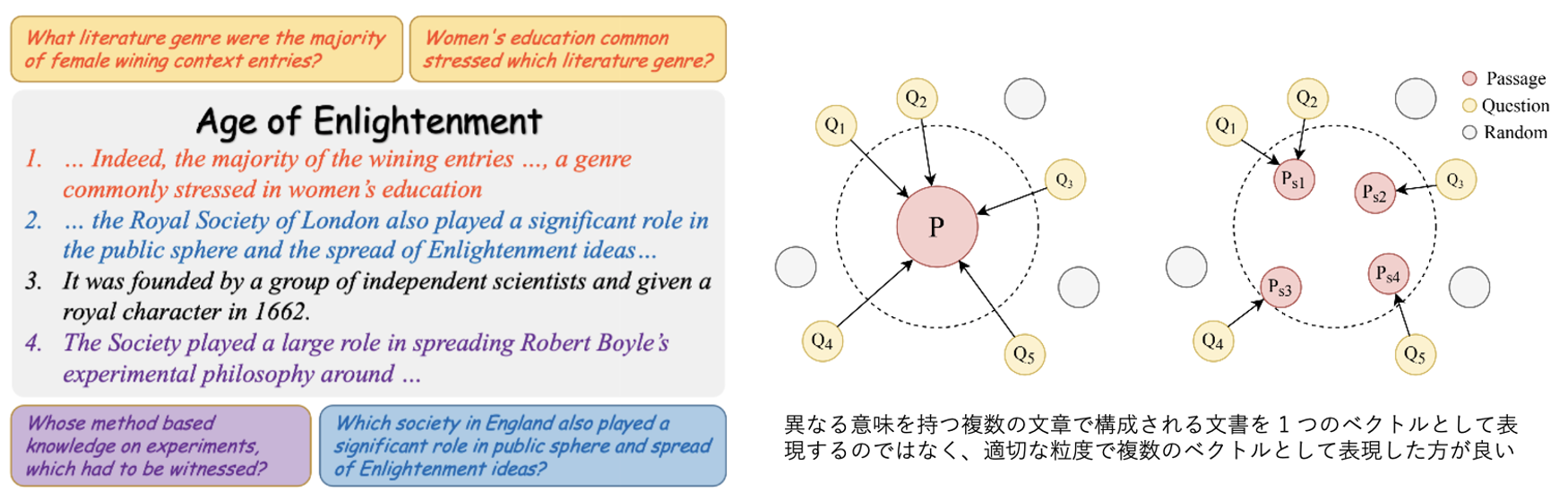
複数の項目を考慮した検索手法にはいくつか種類が存在しており、文単位のベクトルを用いる検索 (Wu+'22, Zhang+'22) や、(multi-vector とは少し異なりますが) 付随する属性情報を考慮した学習事例を構築する検索 (Yang+'22)、またモデルから出力されたトークン単位のベクトル集合を用いる late-interaction を伴う検索 (Khattab+'20, Gao+'20, Santhanam+'22, Yao+'22) など様々です。
Late-interaction を伴う multi-vector retrieval として一般的に知られる ColBERT (Khattab+'20) は、BERT から出力されたクエリと文書のベクトル表現に対してトークン単位に算出した類似度に基づいて最終的な関連度を出力します。具体的には下図の通り、クエリ中の各トークンにおいて文書中の全トークン間の類似度の最大値を取得し、クエリトークンが持つ類似度の最大値を全クエリトークンで合計することで関連スコアを算出します。
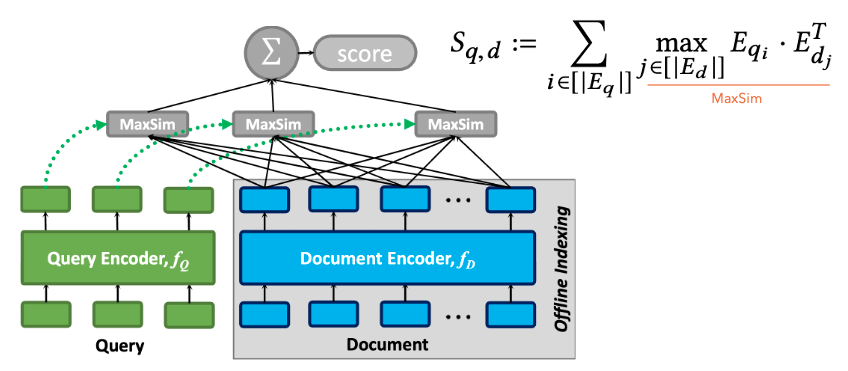
2.1.3. Sparse retrieval
Sparse retrieval では高次元の疎なベクトル表現を用いてクエリと文書の関連スコアを算出します。
UHD (Jang+'21), DSRs (Lin+'21) のような検索手法も提案されていますが、ここでは Azure AI Search や Elasticsearch でも利用される BM25 をはじめとする語彙数次元の疎なベクトルを用いた検索について紹介します。
語彙数次元の疎なベクトルを用いた検索には Bag-of-Words, TF-IDF, BM25 のような lexical match に基づく検索が挙げられます。BM25 については解説記事が多く公開されているため本記事での詳細な説明は避けますが、単語の出現頻度に基づく TF-IDF をベースとしています。TF-IDF は文章中に出現した単語に着目しており、文章中の出現頻度と他の文章に出現しないレア度の高い単語に高い値を割り当てることで語彙数次元の疎なベクトルを生成します。
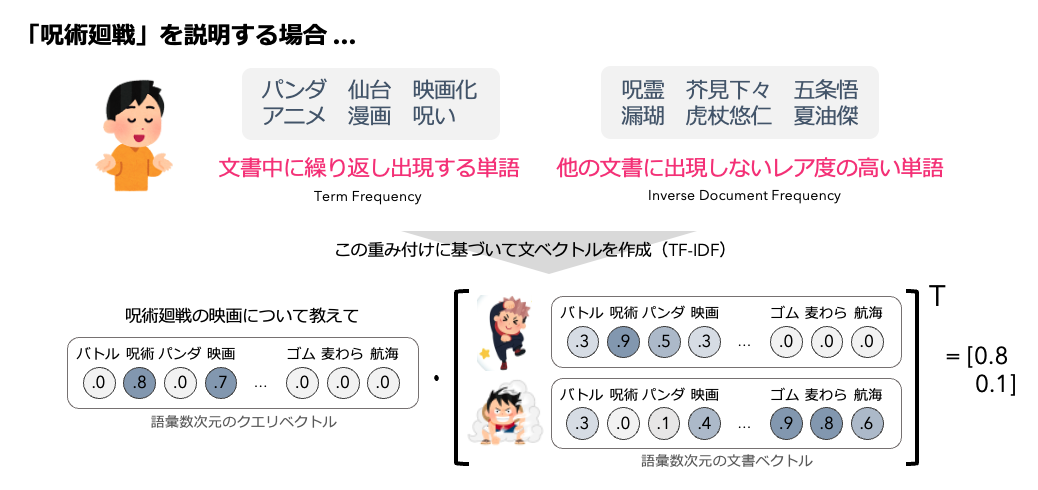
しかし単語に割り当てられる値は表層的な出現頻度に基づいて算出されるため、事前にステミング等の前処理が必要である場合があります。また同義語のような意味的に類似する単語を考慮することが出来ないため、通常リランキングや長文の検索等に利用されることが多いです。
単語の出現に基づいた TF-IDF, BM25 に対して、BERT のような言語モデルを用いて文脈を考慮しつつ類似する意味表現を適切にスコアづけすることを目的とした learned sparse retrieval (LSR) と呼ばれる検索手法もいくつか提案されています (DeepCT (Dai+'19), SparTerm (Bai+'20))。また単語の出現によって単語に割り当てられる値に {0,1} をかけるゲート機構を用いる (SparTerm の) 代わりに対数関数を用いる SPLADE (Formal+'21) や、各トークンに対してベクトル表現をインデックス対象としたインデックスを構築しクエリと文書の共通単語同士の類似度を用いて関連度を算出する COIL (Gao+'21) なども提案されています。
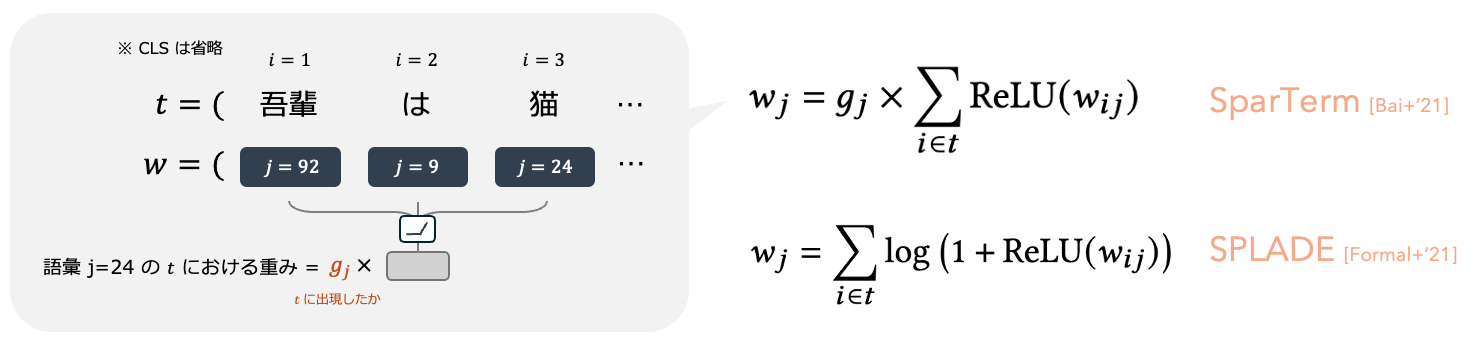
BGEM3Model.sparse_embedding では
class BGEM3Model(nn.Module): def __init__(self, ...): self.sparse_linear = torch.nn.Linear(in_features=self.model.config.hidden_size, out_features=1) ... def sparse_embedding(self, hidden_state, input_ids): token_weights = torch.relu(self.sparse_linear(hidden_state)) sparse_embedding = torch.zeros(input_ids.size(0), input_ids.size(1), self.vocab_size, ...) sparse_embedding = torch.scatter(sparse_embedding, dim=-1, index=input_ids.unsqueeze(-1), src=token_weights) unused_tokens = [self.tokenizer.cls_token_id, self.tokenizer.eos_token_id, self.tokenizer.pad_token_id, self.tokenizer.unk_token_id] sparse_embedding = torch.max(sparse_embedding, dim=1).values sparse_embedding[:, unused_tokens] *= 0. return sparse_embedding
2.1.4. Multi-functionality
ここまで各 functionality ごとの検索について述べましたが、ハイブリッド検索や蒸留等の異なる functionality を統合したアプローチもいくつか提案されています。
例えば Xu+'22 では推論時に dense retrieval による類似度に BM25 のスコアを組み込む Lexicon-Enhanced Dense Retrieval を提案しています。また SPAR (Chen+'22) では dense retriever に BM25 の出力を模倣させるように学習する手法を提案しています。
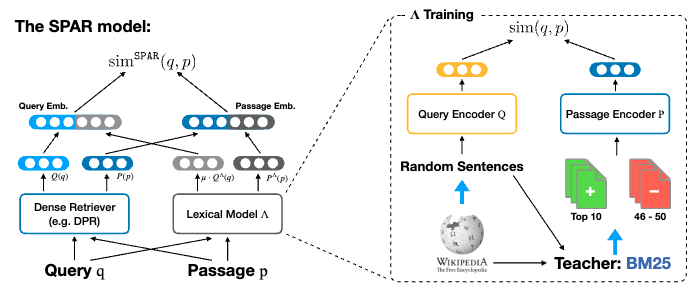
しかしこのようなモデルはあるものの 1 つの埋め込みモデルの枠組みで dense, multi-vector, sparse の 3 つの functionality を統合したものは著者曰くこれまでになく、M3 Embedding はこの点で新規性があるといえます。
2.2. バッチ戦略
Dual Encoder 型の dense retrieval におけるミニバッチの選択方法にはいくつか存在し、① バッチ内負例数、すなわちバッチサイズをどのように増やすか ② より効果的なミニバッチをどのように選択するか、などの観点で構築方法が提案されています。
① バッチ内の負例数を増やすという点では、複数 GPUs 間でバッチ内負例を共有する cross-batch negatives (Qu+'21)、またミニバッチごとに動的な負例選択を行う手法 (Xu+'22, Liu+'21) などが提案されています。
また ② より効果的なミニバッチをどのように選択するかという観点では、負例中の false negative となる文書の影響を軽減したり (Qu+'21, Wu+'22)、正例文書と負例文書の類似度も考慮する学習方法 (Ren+'21) が提案されています。
後述しますが、本研究ではトークン長ごとにグループ化した文書集合からミニバッチを選択するメモリ効率の良いバッチ戦略を提案しています。
3. 技術や手法のキモはどこ?
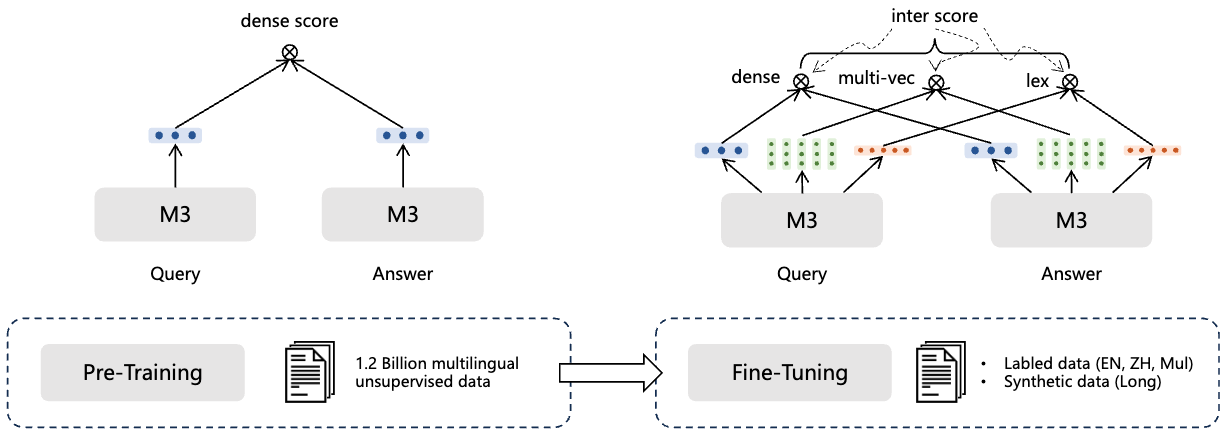
M3 Embedding では RetroMAE (Xiao+'22) によって事前学習済みの XLM-RoBERTa (Conneau+'20) を使用しており、以下の手順によって検索モデルが学習されます。
- 大規模なラベルなしデータセットを用いてテキストエンコーダを学習する。この際の学習目的は Ldense のみ採用する。
- ラベル付きデータおよび GPT-3.5 によって生成された合成データを用いてファインチューニングを行う。この際 self-distillation を導入する。
3.1. 学習データ
ラベルなしデータセット
| 情報源 | 言語 | テキストペア数 |
|---|---|---|
| MTP (Xiao+'23) | 中国語, 英語 | 291.1M |
| S2ORC (Lo+'20) Wikipedia |
英語 | 48.3M |
| xP3 (xP3 Muennighoff+'22) m4C (Raffel+'19) CC-News (Hamborg+'17) |
multi-lingual | 488.4M |
| NLLB (NLLB Team+'22) CCMatrix (Schwenk+'21) |
cross-lingual | 391.3M |
| CodeSearchNet (Husain+'19) | text-code | 344.1K |
| 合計 |
194 言語 2,655 cross-lingual ペア |
1.2B |
ラベル付きデータセット
| 情報源 | 言語 | テキストペア数 |
|---|---|---|
|
MS MARCO (Nguyen+'17) HotpotQA (Yang+'18) TriviaQA (Joshi+'17) NQ (Kwiatkowski+'19) COLIEE (Kim+'22) PubMedQA (Jin+'19) SQuAD (Rajpurkar+'16) NLI data collected by SimCSE (Gao+'21) |
英語 | 1.1M |
|
DuReader (He+'17) mMARCO-ZH (Bonifacia+'21) T2-Ranking (Xie+'23) LawGPT (Liu+'23) CMedQAv2 (Zhang+'18) NLI-zh (shibing624/nli-zh-all) LeCaRDv2 (Li+'23) |
中国語 | 386.6K |
|
Mr.Tydi (Zhang+'21) MIIRACL (Zhang+'23) |
multi-lingual | 88.9K |
合成データ (MLDR)
- Wikipedia, MC4 データセットからトークン数の多い記事を抽出し、その中から無作為に段落を選択する
- GPT-3.5 を使用し、これらの段落に基づく質問を生成する
- 生成された質問と抽出された記事のペアを微調整に使用する
You are a curious AI assistant, please generate one specific and valuable question based on the following text. The generated question should revolve around the core content of this text, and avoid using pronouns (e.g., ”this”). Note that you should generate only one question, without including additional content: # あなたは好奇心旺盛なAIアシスタントです。以下の文章をもとに具体的で価値ある質問を1つ考えてください。 # 生成された質問は、このテキストの核となる内容を中心に展開し、代名詞の使用は避けてください (例: "this")。 # 付加的な内容を含めず、1つの質問のみを生成することに注意してください:
3.2. Self-knowledge distillation
M3 Embedding のロス関数には InfoNCE が採用されます。類似度算出関数 s は dense, sparse, multi-vector retrieval それぞれで定義されます。
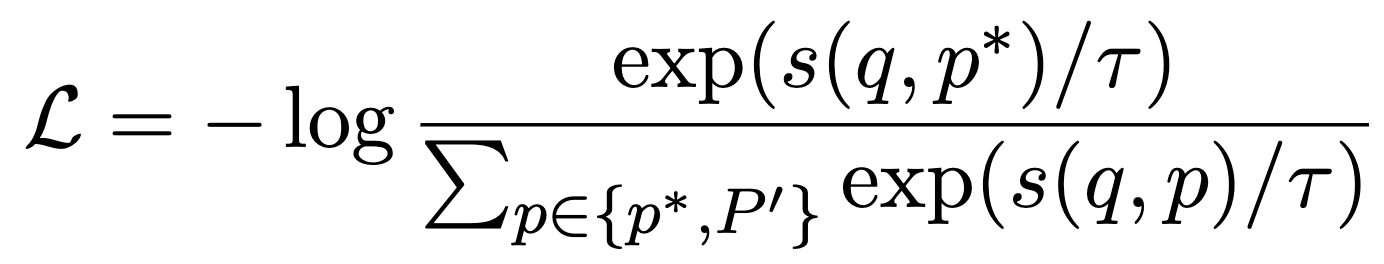
Self-knowledge distillation では最終的なロス関数は以下のように定義されます。L' は sparse, dense, multi-vector の各検索手法において新たに定義されたロス関数 L'* を統合したものとなります。
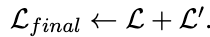
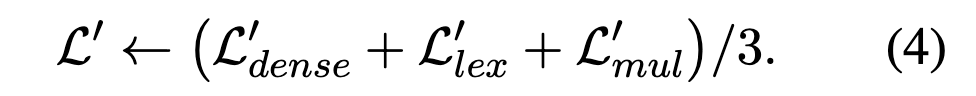
L'* は以下のように定義され、sinter は sparse, dense, multi-vector の異なる検索手法で算出された関連度スコアの和として定義されます。
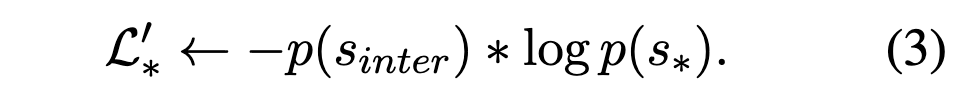
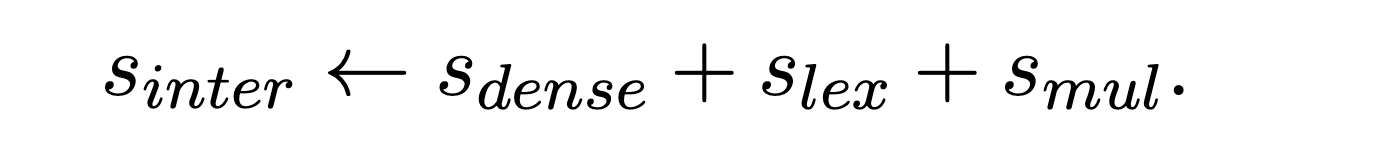
3.3. バッチ戦略
M3 Embedding では ① バッチサイズをどのように増やすか ② より効果的なミニバッチをどのように選択するか、という 2 つの観点からバッチ戦略を提案しています。
① バッチサイズを増やす
M3 Embedding では学習時に gradient checkpoint を利用しミニバッチ内のクエリと文書のペアの集合を分割してエンコードすることで、バッチサイズを増やしています (メモリエラーによるバッチサイズの制限を軽減しています) 。

② 効果的なミニバッチを選択する
M3 Embedding が対象とする文書には、トークン数の少ない文章から 8192 トークンからなる文章まで様々であり、これらを同一ミニバッチ内で同時に処理するとトークン数の差分がパディング (下図. 赤い箇所) されてモデルへ入力されます。
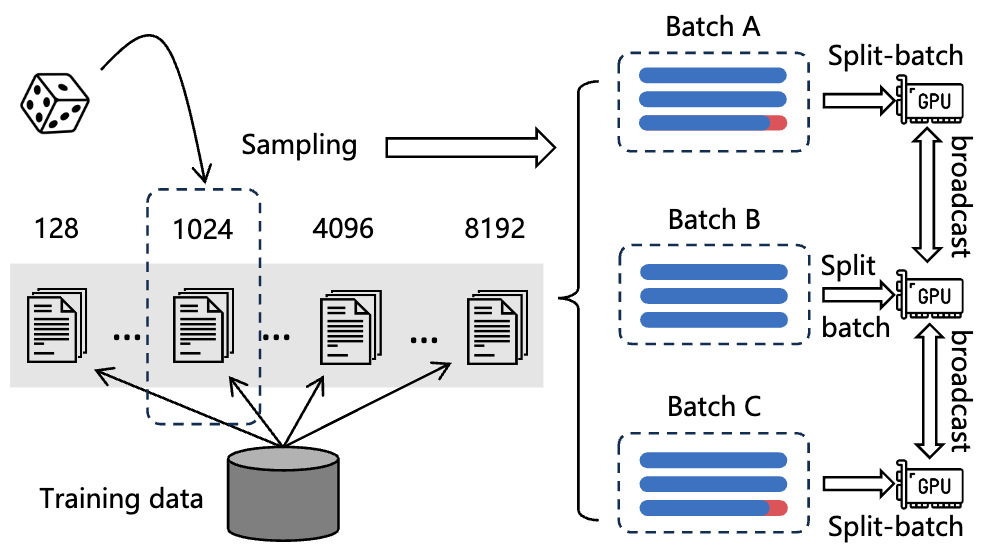
そこで M3 Embedding の学習時には、学習データに含まれる文書をトークン数別にグループ化し、学習時には同一グループに属する文書集合を同一ミニバッチに含めることで、ミニバッチ内に含まれる "[PAD]" トークンの総数を大幅に削減します。
MCLS Method
Zhang+'22, Wu+'22 では、異なる意味を持つ複数の文から構成される文章·文章に対して、In-Passage Negative や "[VIEW]" クラスを導入することで効果的な学習方法を提案しました。
これに対して M3 Embedding では、(学習を必要としない) 推論時に 256 (等の固定値) トークンごとに "[CLS]" を挿入する multi-cls method (MCLS) を提案しています。最終的に、挿入された全ての [CLS] 表現を平均することで文書のベクトル表現とします。
4. どうやって有効だと検証した?
4.1. Multi-lingual retrieval
MIRACL (Zhang+'23)
Multi-lingual な設定における検索性能の評価として MIRACL 開発セットを使用します。MIRACL は多様な累計を持つ 18 言語の Wikipedia から収集され、母国語話者によって評価された高品質なデータセットであり、クエリと文書が同一の言語で構成されます。本研究では Pyserini を用いて nDCG@10 で評価しています。
Sparse retrieval におけるベースラインは BM25 (トークナイザは M3 Embedding と同一の XLM-Roberta を使用) を採用し、また dense retrieval のベースラインには mDPR, mContriever, mE5large, E5mistral-7b, OpenA-3 (text-embedding-3-large) を採用する(モデル詳細は各論文を参照されたい)。
MIRACL による評価結果は以下の通りです。なお ColBERT における Multi-vec では (オンライン検索となるため) M3-Embedding (Dense) の上位 200 件に対してリランキングを行った精度を示しています。
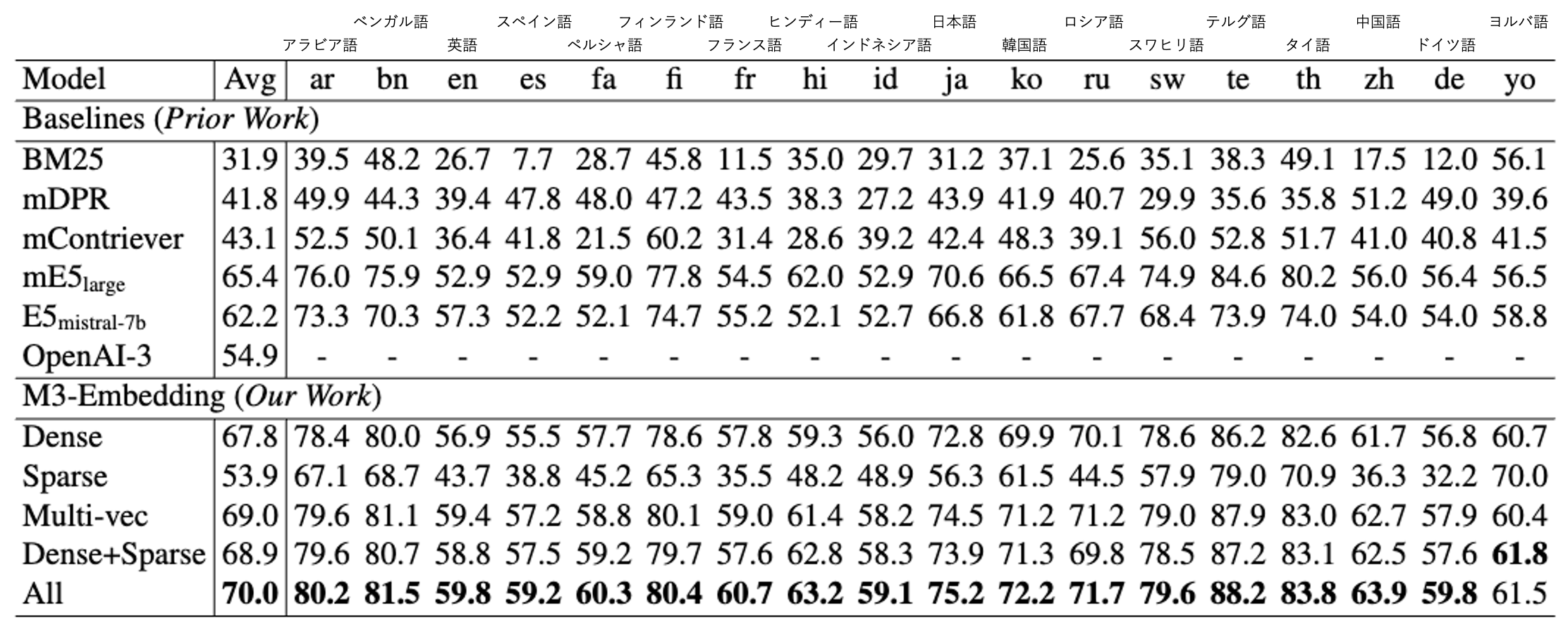
- 英語文章を多く含むデータセットで学習された E5mistral-7b に対して、M3-Embedding (Dense) は英語で -2.5pt と競争力のある nDCG@10 精度を示しています。また、その他の言語においては E5mistral-7b よりも一貫して高い精度を示しています。
- また M3-Embedding (Sparse) は BM25 に対して全ての言語において高い nDCG@10 精度を示しています。
- それぞれの検索手法を組み合わせたハイブリッド検索により、更なる改善を実現可能であることを示しています。
4.2. Cross-lingual retrieval
MKQA (Longpre+'21, TACL)
Multi-lingual な設定における検索性能の評価として MKQA 評価セットを使用します。MKQA は Natural Questions (Kwiatkowski+'19) から人手で翻訳された 26 言語 × 10K QCA ペアで構成されるオープンドメイン質問応答データセットです。
検索評価の設定には、英語を除く 25 の言語で記述されたクエリから英語の Wikipedia コーパス中の対象文書を検索するタスク設定を採用し、Recall@100 を算出しています。

MKQA による評価結果は以下の通りです。
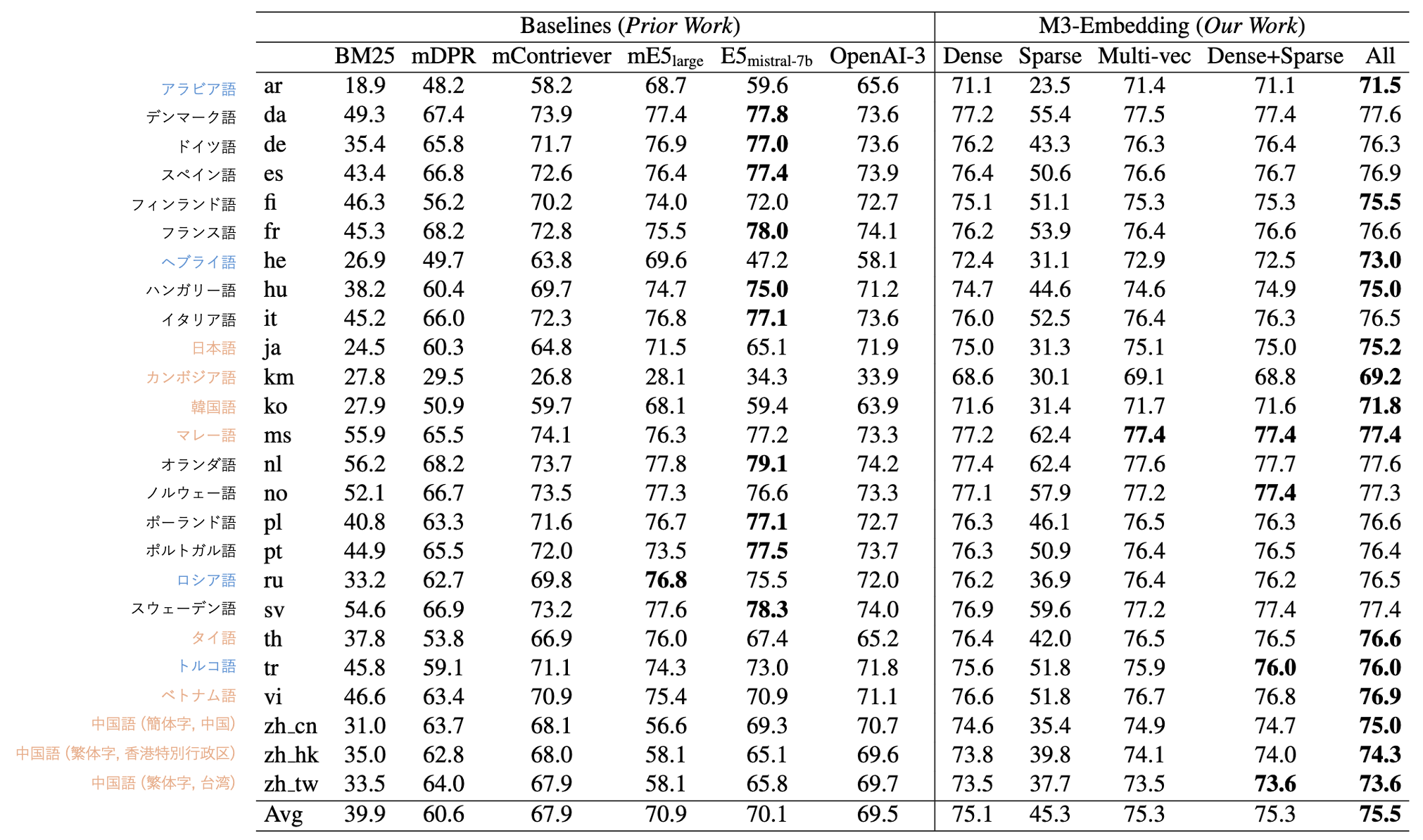
- 全ての言語の平均 Recall@100 において、M3-Embedding (Dense) は 75.1 とBaselines を凌駕する精度を達成しています。E5mistral-7b はラテン語から派生された言語において M3-Embedding (Dense) と同等以上の性能を示しているものの、東アジアや西アジア圏で使われる言語では M3-Embedding (Dense) よりも低い性能を示しており、多様な言語による教師なしデータセットを用いた事前学習が要因であると考えられます。
- M3-Embedding (Sparse) では BM25 に対して一貫して高い性能を示していますが、異なる言語によるクエリと文書間で共通して出現する単語が少ないため表層情報に基づく M3-Embedding (Sparse) は M3-Embedding (Dense) に対して大幅に低い Recall@100 となっています。
4.3. Multilingual long-document retrieval (MLDR)
MLDR
MLDR (Multilingal Long-Document Retrieval) は本研究にて GPT-3.5 より作成されたデータセットで、Wikipedia, Wudao, mC4 から収集した多言語の記事をもとに作成されています。
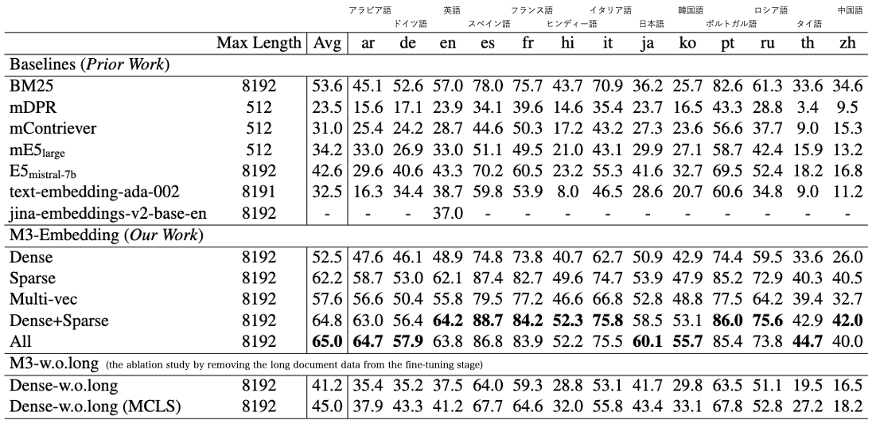
- トークン数の多い文書の検索において M3-Embedding (Sparse) が M3-Embedding (Dense, Multi-vec) に対して高い nDCG@10 を示しており、ハイブリッド検索によって更なる改善を実現します。
- 微調整段階において長文の学習事例 *4 を除去した M3-w.o.long (Dense-w.o.long) において、多くの Baselines の nDCG@10 を上回る結果となっています。これは多様かつ大規模な事前学習による影響が関係すると考えられます。
- また複数の "[CLS]" トークンを固定次元ごとに挿入する MCLS では、学習を必要としない工夫にもかかわらず、トークン数の多い文書の検索性能を大幅に改善します。
NarrativeQA (Kočiský+'18, TACL)
NarrativeQA は、回答者が本や映画の台本を読んで物語に関する質問に答えるタスクです。質問と解答は英語で記述されます。 Jina 評価パイプラインで評価を行っています。
ここでは Attention with Linear Bias (ALiBi) を BERT のフレームワークに組み込むことでトークン数の多い文章をエンコード可能にする Jina Embeddings v2 が新しいベースラインとして追加されています。
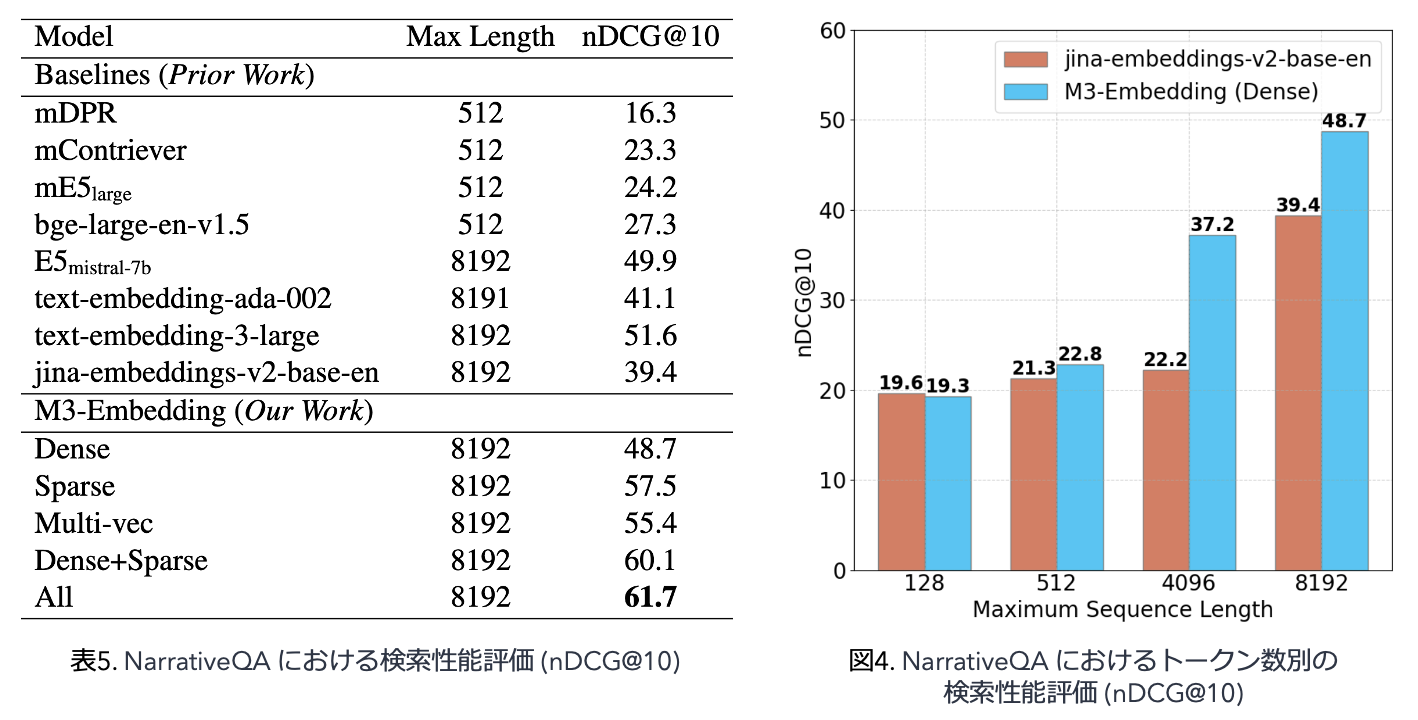
- 表 5 から、M3-Embedding (Sparse) および M3-Embedding (Multi-vec) は M3-Embedding (Dense) と比べて、トークン数の多い文書検索において有効であり、さらにこれらをハイブリッドに組み合わせることでより高い nDCG@10 を得ることを示しています。
- また図 4 では、Jina Embeddings v2 に対して M3-Embedding が広範なトークン数対して高い nDCG@10 を示しています。
4.4. アブレーション
Self-knowledge distillation の有効性検証
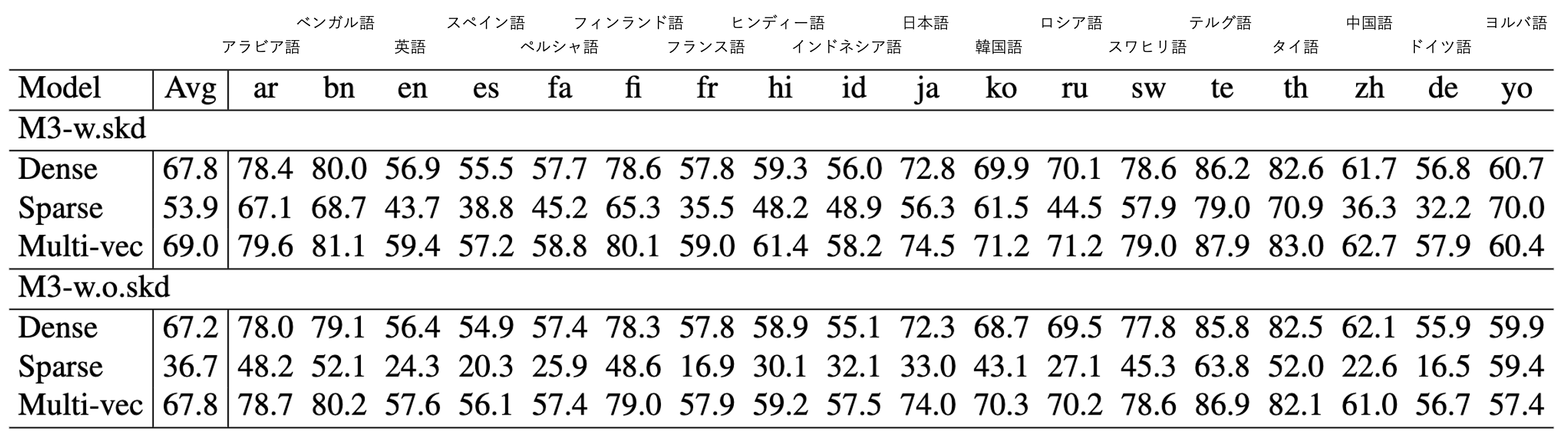
MIRACL の nDCG@10 評価において self-knowledge distillation を採用せず各検索手法を独立に学習させたモデル M3-w.o.skd と M3 Embedding との性能比較を行っています。

- Self-knowledge distillation を伴う M3-Embedding (M3 w.skd) では、dense, sparse, multi-vec の全ての設定において、M3-w.o.skd よりも高い nDCG@10 値を示すことから、self-knowledge distillation が有効であることを示唆しています。
多段階による学習の影響
本研究では RetroMAE で事前学習された XLMRoBERTa を (1) 大規模なラベルなしデータで Ldense の学習目的で学習し (2) ラベル付きデータを用いてファインチューニングしました。表 7 ではこの多段階による学習の影響を調査しています。
- 結果についてはそれほど驚くべきではありませんが、RetroMAE, ラベルなしデータセットによる事前学習による検索性能の向上が示されています。
5. 議論はある?
知見
- これまで dense, sparse, multi-vector retrieval は異なるモデルを用いる必要があったが、M3 Embedding で統一されたのは開発者としてもありがたく、また self-knowledge distillation による統合が有効であることは知見です。
- トークン数の多い文書 (特に異なる意味の文章が複数含まれる文書) において multi-vector, sparse retrieval が有効であること、また固定トークン数ごとに CLS トークンを挿入する MCLS が有効であること、は文書検索の実応用でも参考になりそうです。
議論の余地
他の質問に対する正例文書を負例文書とみなす負例サンプリングを採用しており、バッチ内に false negative が含まれてしまう可能性があるかもしれません (Multiple References in Large Batch Size (Wu+'22))。そのため False negative 文書のフィルタリング (Qu+'20) や文書間類似度を考慮した学習 (Ren+'21) のような手法によって更なる検索性能の改善が見込める可能性があります。
日本語における検索性能については、multi-vector retrieval の1つである JaColBERTv2 (Clavié+'24) が JSQuAD (Kurihara+'22) や JQuRA (Tateno+'24) で mE5 や M3 Embedding を上回る検索性能を示しています。また sparse retrieval として splade-japanese-v3 (aken12) といったモデルも公開されており、実応用においてはドメインや文書の性質等に応じて適切な埋め込みモデルの選択が必要になるかと思います。
多言語向けに最適化された XLMRoBERTa Tokenizer ではトークンの過分割等により BM25 の性能が過小評価されてしまっている可能性も考えられます。これに対する回答は表 11 で示されており、Lucene Analyzer を用いた検索性能の比較が行われています。Lucene Analyzer を用いた BM25 に対して M3 Embedding (sparse) が MKQA, MIRACL において高い nDCG@10 を示し、MLDR では若干劣るも同程度の性能を示していることから、M3 Embedding の有効性を示しています。
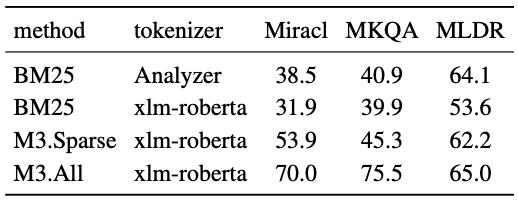
表11. 異なるトークナイザを使用した BM25 メソッドとの比較. MIRACL, MLDR は nDCG@10, MKQA は Recall@100 の値を示す. 評価セットである MKQA, MIRACL, MLDR の一部が Wikipedia から構築されているのに対して、TriviaQA, SQuAD, Mr.Tydi といった学習セットも一部 Wikipedia から構築されています。注意深く構築されているかとは思いますが、データセットのリーク問題については注意する必要があるかもしれません。
- また Horváth+'24 - VectorHub Article | An evaluation of RAG Retrieval Chunking Methods や Zhu+'24 - LongEmbed では、M3 Embedding に対して他モデルの方が良い性能であることが報告されており、実応用における技術選定においてはより横断的な評価が必要になるかもしれません。
6. 次に読むべき論文は?
- Wang+'23 - Improving Text Embeddings with Large Language Models
- Khattab+'20 - ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT (SIGIR)
- Santhanam+'22 - ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction (NAACL)
おわりに
本記事では BGE M3-Embedding について紹介しました。繰り返しになりますが、誤りや不十分な記述があると思いますので、必ず元論文を参照してください。本記事を読んでくれた方が「ここの議論足りないよね」「本当はこうじゃない?」といった議論を展開していただけると幸いです。
長くなりましたが、ここまで読んでいただきありがとうございました。Algomatic では LLM を活用したプロダクト開発等を行っています。 LLM を活用したプロダクト開発に興味がある方は、下記リンクからカジュアル面談の応募ができるのでぜひお話ししましょう!
参考
- 早野氏+'24 - Embeddingモデルを使ったベクトル化のしくみ、fine-tuning手法を解説
- Morris氏+'22 - A Brief Survey of Text Retrieval in 2022
- Kamata氏+'20 - 自然言語処理と情報検索について(NLP AND IR)
- 浅井氏+'22 - より多くの言語での情報検索・質問応答実現のために(招待公演:AI王 ~ クイズAI日本一決定戦 第三回最終報告会)
- Asai+'22 - MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
- ACL2020 Tutorial: Open-Domain Question Answering
- 森羅 2023 最終報告会
- AI王 ~ クイズAI日本一決定戦
- github.com/oshizo/JapaneseEmbeddingEval
- huggingface.co/bclavie/JaColBERTv2
- huggingface.co/aken12/splade-japanese-v3

*1:multi-lingual retrieval: 複数の言語が同時に含まれたデータセットにおいて、クエリと同一言語の関連文書を検索するタスク
*2:cross-lingual retrieval: 複数の言語が同時に含まれたデータセットにおいて、クエリと異なる言語を持つ関連文書を検索するタスク
*3:オフライン検索: クエリと文書の類似度の算出をエンコーディングとは独立して算出する検索方法。リランカでよく利用される cross-encoders などは、類似度の算出がエンコーディングと同時に行われるためオンライン検索と呼ばれる。一般的にオンライン検索は高精度だが低速度であるため、リランカとして上位 k 件に絞った候補に対して行われる。
*4:おそらく MLDR のことだが明記されていない