こんにちは。NEO(x) 機械学習エンジニアの宮脇(@catshun_)です。
RAG システムの開発、いざ業務に統合するとなると結構大変ですよね。
構築してみたがユーザ数が伸びず、、なんてことはよくあると思います。
実際こんな記事も話題になりましたね。
本記事では、コラムとして RAG システムの設計で考慮したい点を自戒を込めて記述したいと思います。 誤っている記述等もあると思いますが、本記事を読んだ方の議論のネタになってくれれば幸いです。
また Retrieval-based LM の技術的な話は、以下で触れておりますので併せてご覧ください。
RAG とは
RAG (Retrieval-Augmented Generation) とは、社内文書・長期記憶に該当する対話履歴・API 仕様書などの 外部知識資源 を、言語モデルが扱えるよう入力系列に挿入する手法です。もともと Lewis+'20 (NeurIPS) では『モデル名』として提案されましたが、その後 LLM の普及とともに『手法名』を指すことが一般的です。最近では『社内文書QAシステム』を RAG と呼称するケースも散見されますが、本記事では RAG を『手法名』として言及します。
顧客の潜在的なニーズはどこにあるか?
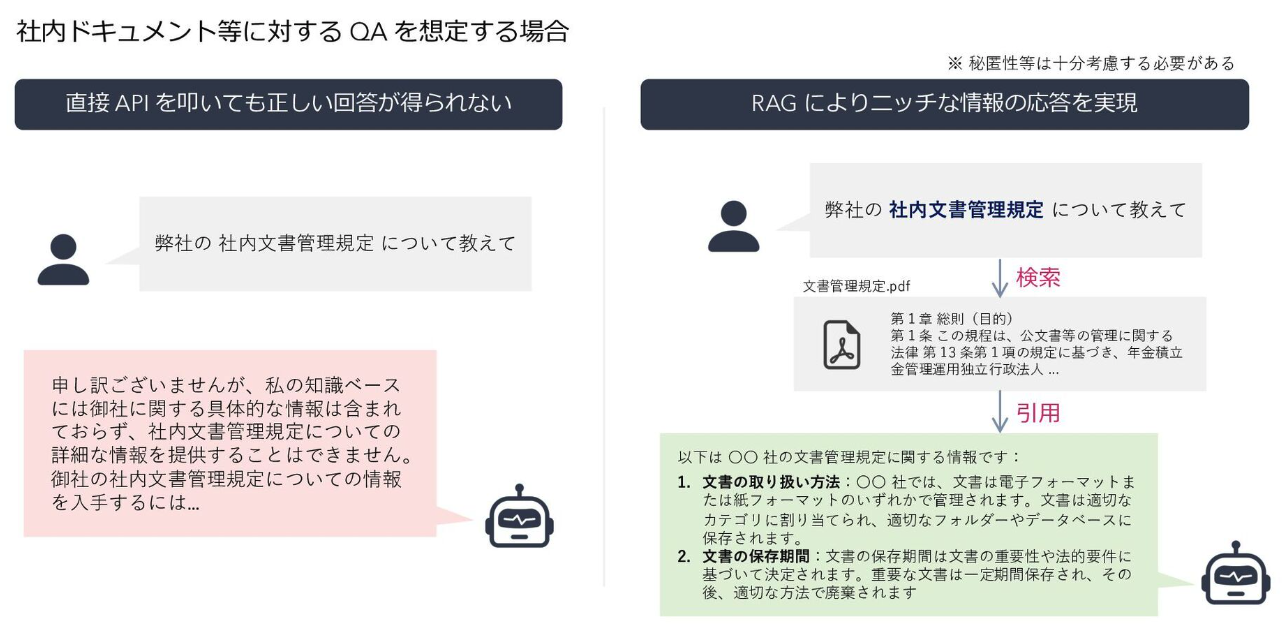
社内文書に対する質問応答システムの導入は確かに業務効率を改善してくれる気がします。
ですが、現在の業務効率の改善と導入の必要性には、まだギャップがあります。導入余地は現在の業務効率に何かしら課題感を抱えているためであることは分かりましたが、その真因は何でしょうか。社内文書に対する質問応答システムの導入は、顧客にとって本当の解決策になりうるのでしょうか。

RAG システムを導入するだけでは 手段の目的化 にすぎません。
課題感については当然ですが顧客に依存するところであり、必ずしも顕在している訳ではありません。AXを提案する開発者がその課題感を明らかにして、どんなシステムを作れば真因を解決する策になりうるのか、解決策を実現するための要求項目はどのようなものが考えられるのか 1 つずつ整理する必要があります。

RAG に限らず AI導入における事前検死 的な視点については、Algomatic の Dory 氏 (@dory111111) が以下の [note] で記述していますので、こちらもご覧ください。

どのユーザの何をカイゼンしたいのか?
どんなプロダクトでも共通してますが、実際の ユーザストーリーを考慮する ことは非常に有効です。

上記の例では、要求事項の誤りリスクが高い事例として『金額に関する質問』を対象としています。生成内容が誤った際の被害が大きいほど、生成された内容が信頼できるものであるかチェックする必要があり、チェックのための情報源へのアクセスという手戻りが発生してしまいます。
そのため、社内文書 QA システムにおいても、誰が使うのか、どのタイミングで必要となるのか、誰にとってどんな機能があると良いか、開発優先度・実現可能性はどれくらいか、などを設計段階から考慮する必要があります。
どのような内容の問い合わせが多いのか?
社内文書検索や質問応答システムは、想定されるユーザや利用用途 によって設計項目も変わってきます。どのようなクエリで入力されることが多いのかについては、運用のタイミングで初めて分かる場合もあるためログを監視しながら段階的に機能更新することも重要です。

また一般的に多くの RAG システムはハイブリッド検索+リランキングを採用しているかと思いますが、alpha-tuning や Adaptive RAG が提案されているように、BM25 のような表層検索あるいは OpenAI Embeddings のような意味検索の どちらが効果的な検索手法であるについても『クエリの形式』によって異なる ため、問い合わせ内容は開発者本人も把握することが大切です。
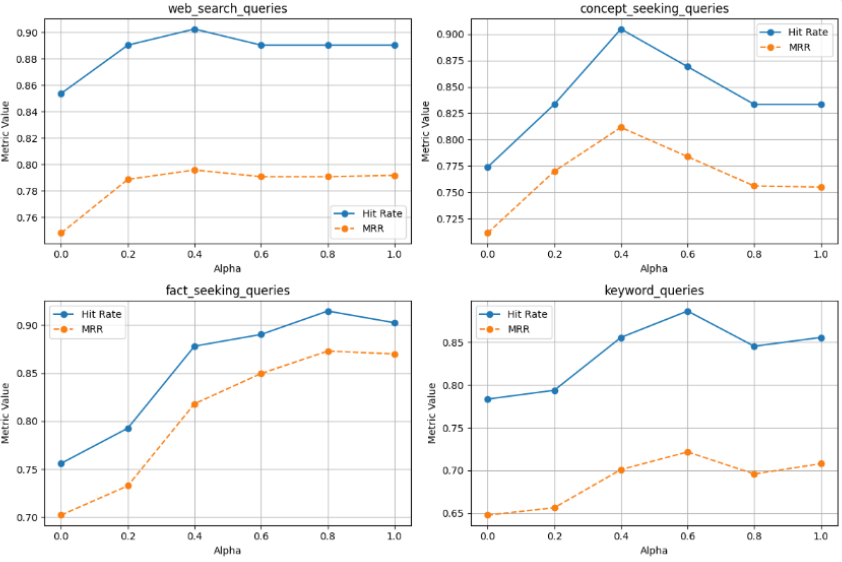
α*意味検索+(1-α)*表層検索 であり、クエリの形式によって適切な α の値が異なることを示している.
検索対象となる社内文書はどのような形式か?
ここが一番のボトルネックになることが多いですよね。Excel 文書はどのように書き起こせばよいのか、pptx のようなテキスト·画像·オブジェクト·図表·空間情報をどう言語化すればよいか、scaned or printed PDF か、など…。
「どのように言語情報に変換するか」はさておき、まずは 検索対象となるファイル構造にはどのような形式が支配的であるか を把握する必要があります。
これらを把握したうえで、次のようなインデクシングのための検索フィールドを定義します。
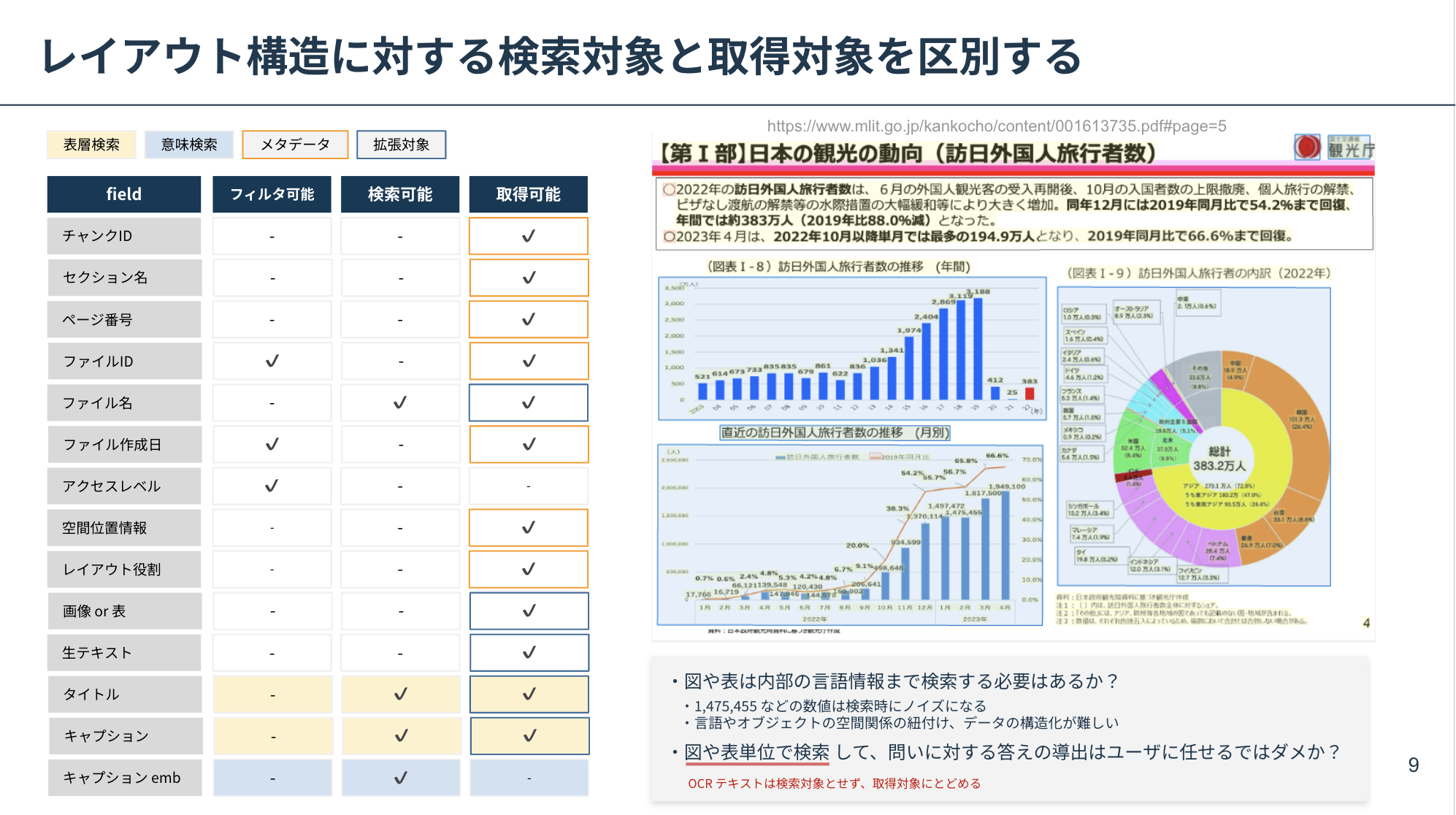
上記の例は、スライド資料に対する Azure AI Search での検索フィールドの例であり、1 つのチャンクに対して複数の属性値を SQL Table のカラムのように定義します。
ファイルからテキストを抽出するライブラリはいくつかありますが、重要なのは 抽出したチャンクの属性値に対してどんな機能を持たせるか になると思います。
例えば、抽出したテキストは検索するために適切な粒度なのか(e.g. OCR テキストは検索に含めるべきなのか)、検索対象と取得対象はどう区別されるか、メタデータによるフィルタは可能か、ID 情報から親チャンクや隣接チャンクが取得可能か、ローカライズ結果を PDF 上にプロットするための空間位置情報は必要か、など検索対象から見えてくる検討事項は様々です。
曖昧なクエリを入力させないための UI になっているか?
よくある問題点ですが ユーザのクエリが曖昧である 問題が挙げられます。「社員就業規則から育休制度の申請方法を抽出し取得可能な期間を教えて」のような、ドキュメントフォルダやファイル構造を把握した上でのクエリが入力されることは稀で、「育休 期間」のような検索ライクなクエリが入力されることは多々あります。
検索時のクエリの曖昧性を回避するためには クエリ拡張 などのバックエンドでの工夫が考えられますが、UI によって曖昧なクエリを入力させない フロントエンドの工夫も考えられます。
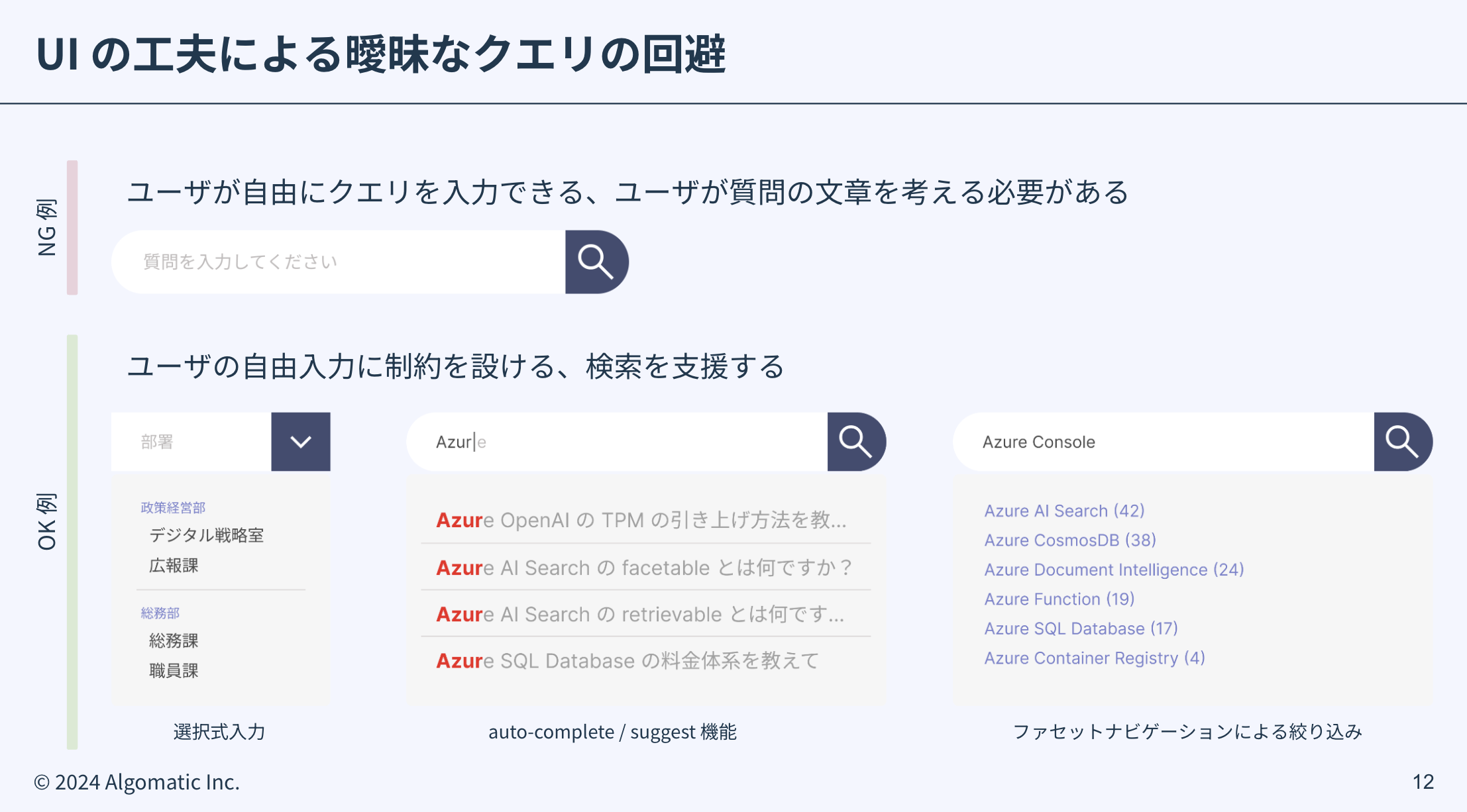
上記 NG 例では「質問を入力してください」というプレースホルダが設置されているだけで、クエリの具体例がなくユーザがクエリを考える必要がある、また 入力の制約がなく、ユーザが自由にクエリを記述することができる といった問題があります。textarea も検索ボックスの見た目であり「育休 期間」といった検索ライクなクエリを誘発する原因となります。
これに対して OK 例では左から、select を用いた質問領域の絞り込み、提案機能による FAQ の提示、ファセットナビゲーションによる検索後の絞り込みなどを挙げており、ユーザに質問をなるべく考えさせない、欲しい情報に素早くアクセスできる 工夫となっています。
入力時の候補提案については Google 検索やユニクロの商品検索など多くのサービスで導入されていますが、顧客QA対応では Helpfeel の FAQサポート などが挙げられます。
生成誤りに対する導線や改善策はあるか?
LLM が『次の単語を予測するモデル』である以上、ハルシネーションや指示追従誤りが発生するのは仕方ありません。
重要なのは 生成誤りを認めた上で、どのような予防や対策、導線を張るか を考慮した設計を行うことです。 以下は一例ですが、生成誤りに対して考慮すべき点をまとめています。

また以下の記事も併せてご覧ください。
おわりに
ここまで読んでいただきありがとうございました!
Algomatic では、LLM を活用したプロダクト開発や技術顧問等を行っています。
詳細が気になる方は、ぜひお気軽にお問い合わせください。
AX for Enterprise
Algomatic では AI を戦略的に活用することで、業務プロセスを抜本的に見直し、業務を変革するコンサルティングサービスを提供しています。
- 投資対効果の高いAI活用領域の特定に向けたコンサルティング
- AI活用を伴う業務改革支援(BPR)
- AI導入に必要なデータ整備・分析などデータアナリティクス支援
- AI活用に向けた人材育成・内製化支援
生成AI Partner
生成AIを活用した業務効率の改善や事業検証まで、一気通貫で支援します。 生成AI特化の事業会社として培ったノウハウで、生成AIに特化した受託開発や壁打ち、技術顧問まで幅広く対応しています。
