こんにちは。Algomatic NEO(x) カンパニー機械学習エンジニアの宮脇(@catshun_)です。
本記事ではブラウザやモバイル画面を操作する LLM エージェントとその周辺技術について超ざっくりと紹介します。
社内に向けたキャッチアップ資料として作成しており、加筆修正する可能性がありますが、本記事を読んだ方の議論のネタ程度になってくれれば幸いです。
以前 AI ソフトウェアエンジニアについて紹介しているので、こちらもご覧いただけたら幸いです。
おことわり
- 本記事では対象とする研究棟の 詳細な解説は含みません。詳細は元の論文を参照ください。
- 不十分また不適切な言及内容がありましたらご指摘いただけますと幸いです。
- プロダクト等の利用時は 必ずライセンスや利用規約を参照して下さい。
本記事の目次
Google I/O '24 での Gemini Nano × Android の発表
はじめに先日の Google I/O '24 のセクションで話題となった Gemini を Android に組み込むという話について簡単に紹介します。以下のリンクに引用先を添付しますが、紹介された内容は大きく 3 つありました。
1. Circle to Search により AI を活用した検索が手軽に実行可能に
Circle to Search では、アプリ起動中にユーザが指で囲った対象を素早く検索する機能になります。画像検索だけでなく言語の翻訳や検索も可能であり、Google I/O ではタブレット上で学校のテストの解き方を指導してくれるデモが紹介されました。今後は記号や図・グラフにも対応するそうで、より複雑な問題に対応することが期待されます。
2. Android の新しいアシスタントとして Gemini がユーザを支援
新しいユーザ体験として、Gemini が Android に組み込まれ、ユーザが意図する動作を予期しながらプロアクティブに提案してくれるようになるそうです。Google I/O のデモでは、SNS のチャット時に画像生成を行ったり、Youtube の動画や PDF に対して質問する使い方を紹介しています。また SNS 上のピックルボールというスポーツの会話から、近くでピックルボールができる施設をプロアクティブに提案する機能も紹介されています。
3. オンデバイスで動作可能な Gemini Nano の紹介
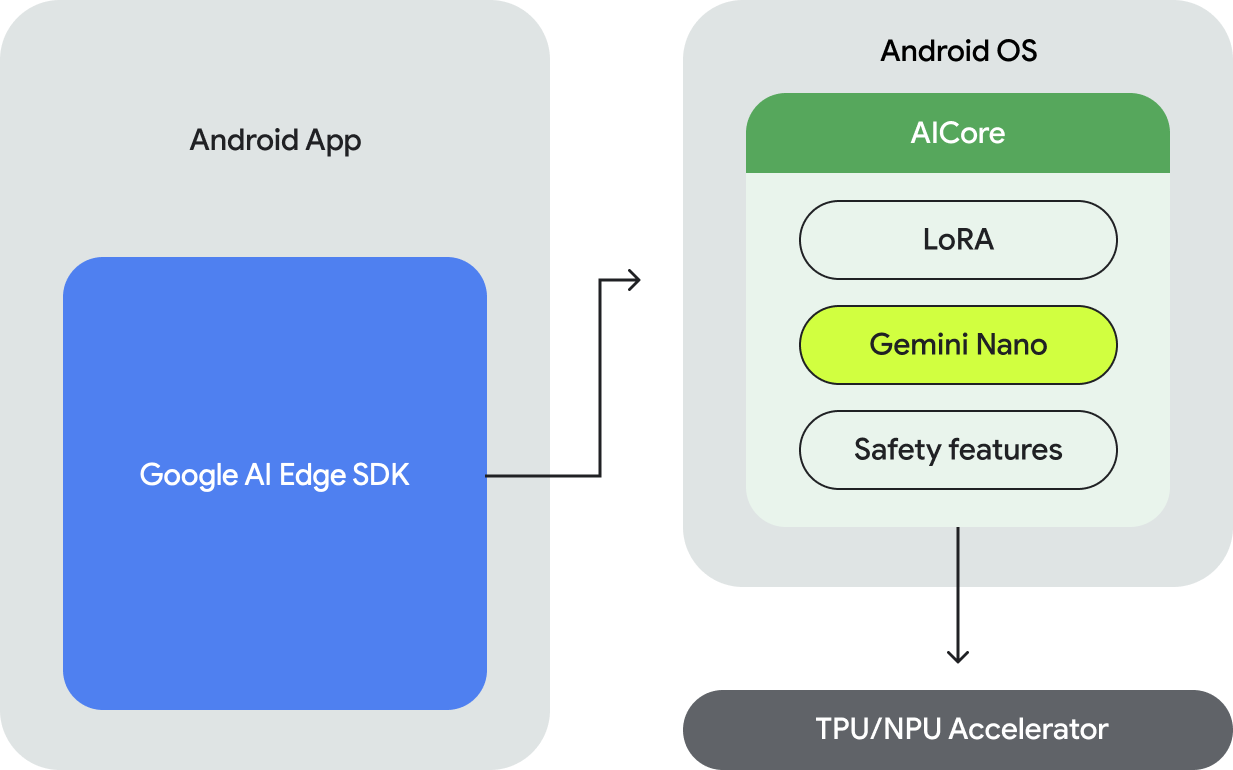
最後にオンデバイスで動作可能な Gemini Nano の発表についても紹介されました。スマホがネット環境下にない状態でも動作可能で、視覚・話し言葉・音声入力が可能で、Gemini Nano と AICore は現在、Google Pixel 8 Pro および Samsung S24 シリーズのデバイスでのみ利用可能で、近日中にさらに多くのデバイスのサポートが開始される予定だそうです。
HTML × LLM
HTLM (Aghajanyan+'21)
HTLM (Hyper Text Language Model) は、Common Crawl から抽出された HTML で学習された BART ベースのモデルです。
以下の解説記事が参考になりますので、詳細はこちらを参照して下さい:
MarkupLM (Li+'22, ACL)
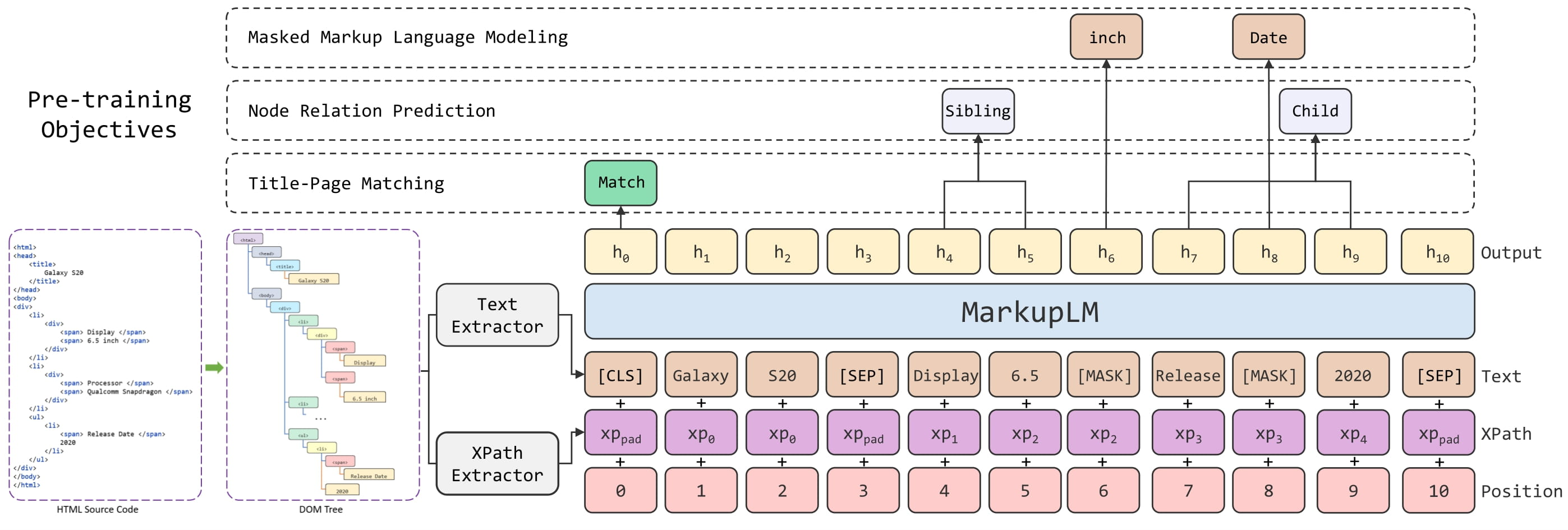
MarkupLM は BERT をベースモデルとして XPath の情報を入力可能にしたモデルです。事前学習時に ① マスクしたテキスト情報を周辺マークアップ情報から予測する Masked Markup Language Modeling ② 2 つのノードに対して事前に定義されたノード間の関係性を予測する Node Relation Extraction ③ タイトルとページがマッチしているかの二値判定を行う Title-Page Matching の 3 つの学習目的を導入しています。
BERT をベースとした文書画像読解モデルである LayoutLM の 2D Positional Embeddings, MarkupLM の XPath Embeddings を用いてテキスト, 文書画像, マークアップ言語の 3 種類の入力を可能にする XDoc なども後続タスクとして提案されています。
Pix2Struct (Lee+'22, ICML)
Pix2Struct はマスクされた WEB ページのスクリーンショットから HTML ベースのテキストを出力する Screenshot Parsing タスクで事前学習を行った ViT ベースの視覚言語モデルです。AI2D, ChartQA, Screen2Word, DocVQA などの後続タスクで有効性を示しています。また後続の研究として Pix2Struct をベースモデルとしてグラフから matplotlib, seaborn 等のプログラムを生成する MatCha なども提案されており、視覚情報をマークアップ言語やプログラムに変換することの有効性が示されています。

Dual-VCR (Kil+'24, CVPR)
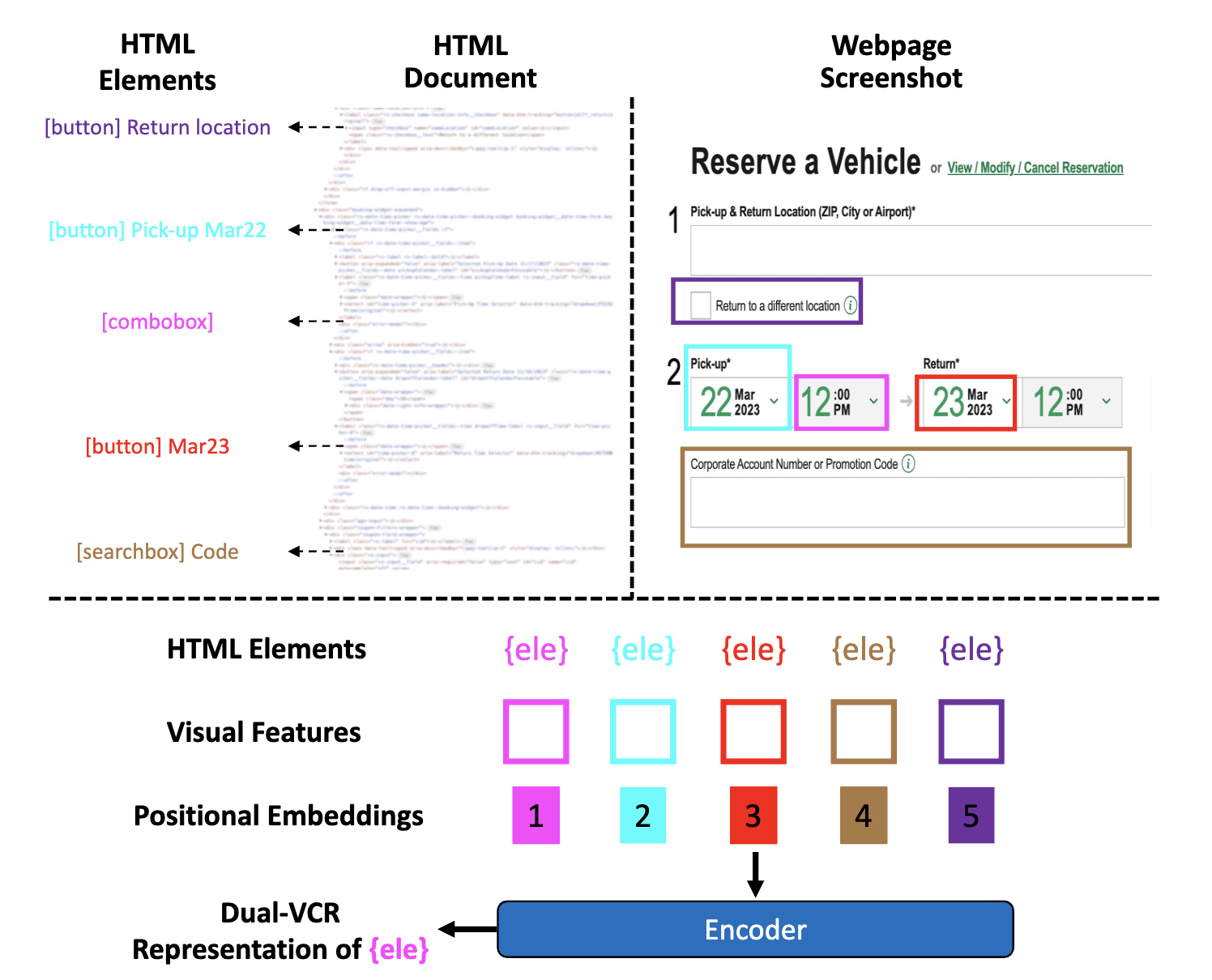
Dual-VCR は HTML 要素をエンコーディングする際に、空間的に隣接する HTML 要素を含む言語情報とスクリーンショットからの視覚的な情報を紐付けてエンコーディングする手法で、エージェントに一連の行動のコンテキストを提供します。WEB ページのスクリーンショットは Playwright を使用して、各 HTML 要素のバウンディングボックスを特定し、バウンディングボックスの中心点に基づいて要素間の距離を測定します。各要素の視覚的特徴は WEB ページのスクリーンショットで事前学習された Pix2Struct を用いてスクリーンショット全体から ROI Align を適用して、各要素のバウンディングボックスに対応する特徴ベクトルを取得します。HTML は、MindAct によって各要素に対応するテキストが抽出されます。
CogAgent (Hong+'24, CVPR)
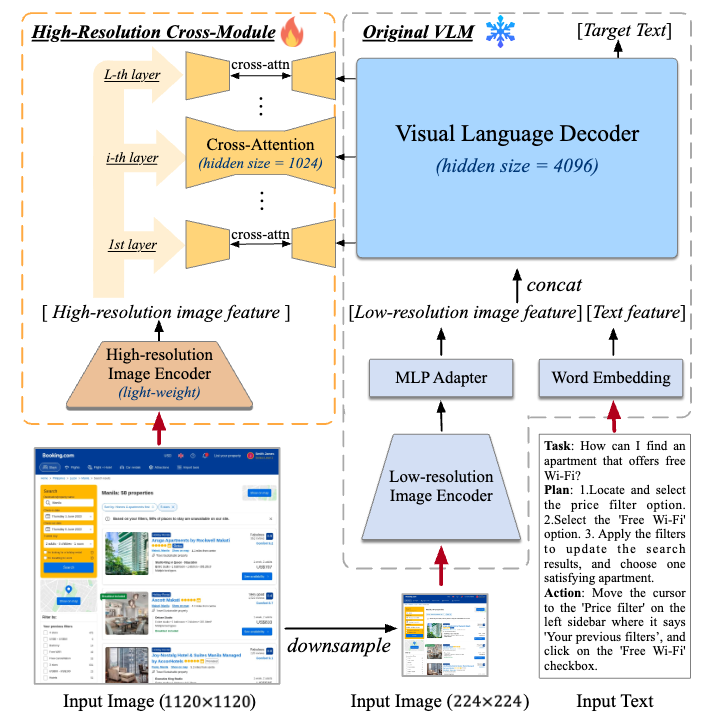
CogAgent は、GUI 理解およびナビゲーションに特化した CogVLM-17B ベースの 18B 視覚言語モデルです。224×224 および 1120×1120 の画像を入力可能な 2 つの画像エンコーダを保持しています。
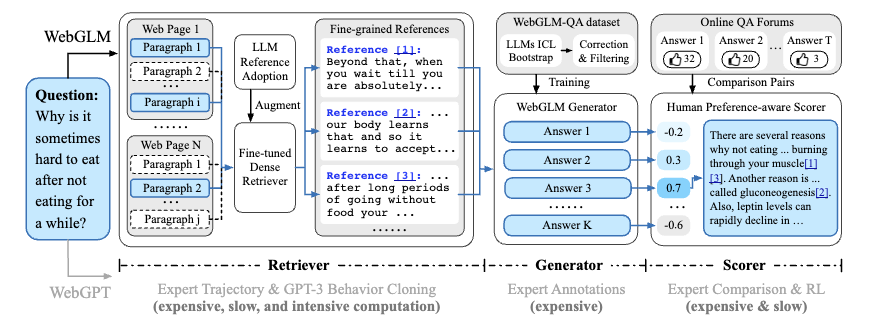
WebGLM (Liu+'23, KDD)
WebGLM は、WEB にアクセス可能な言語モデルベースの QA システムで、WEB 検索および LLM による coarse-to-fine な2 段階検索によって関連する文書を取得する Retriever、長文 QA データで学習された解答生成器 (Generator)、人間の選好性を教師として学習された Scorer で構成されます。
視覚的プロンプト
Google I/O '24 で発表された Circle to Search では、円でなぞることで明示的に検索対象を指定していました。
このようなプロンプトは視覚的プロンプトと呼ばれます。なお以降ではタスク指示に関連する視覚的プロンプトを対象としており、単に視覚情報に追加の情報を付与する Visual Prompt (Bahng+'22) とは区別しています。
Set-of-Mark (Yang+'23)
Set-of-Mark は GPT-4V における視覚読解タスクにおいて、入力画像を Segment-Anything (Kirillov+'23) で事前にセグメンテーションする手法です。セグメント結果に番号を割り当てることで GPT-4V の各オブジェクトによる位置関係の認識を補助します。

ViP-LLaVA (Cai+'24, CVPR)
ViP-LLaVA は、RGB 画像に視覚的マーカを直接オーバーレイした任意の視覚的プロンプトを考慮可能なマルチモーダルモデルです。ユーザは直感的に画像をマークすることで、「赤いバウンディングボックス」や「尖った矢印」のような自然な手がかりを用いてモデルと対話することができます。また本論文では視覚的プロンプトの理解を評価するための ViP-Bench ベンチマークも発表されています。

LLM × WEB ナビゲーション
自律エージェントとは、環境の中に位置し、環境の一部であるシステムであり、環境を感知し、時間をかけて、自らの課題を追求し、将来、感知したことに影響を及ぼすように行動するものである。 —— Franklin and Graesser (1997)
LLM エージェントの明確な定義があるか分かりませんが、LLM エージェントが指す一般的な共通認識は LLM を搭載した自律駆動型のシステム という認識が 1 つあるかと思います。
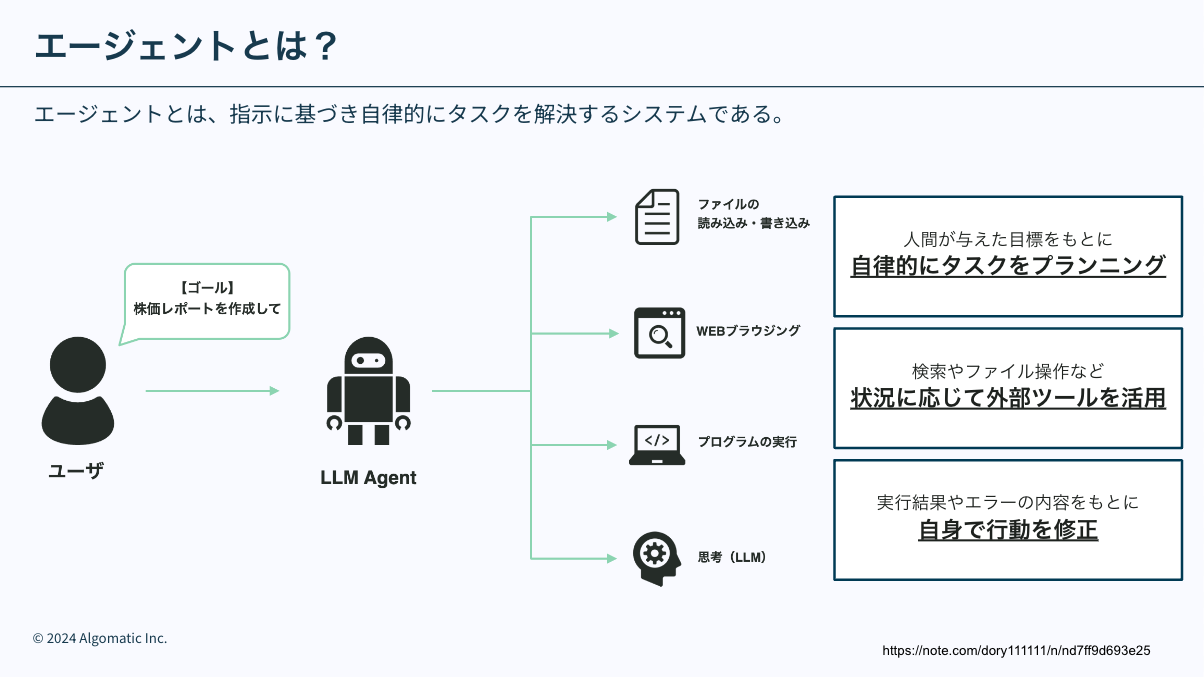
LLM を用いてブラウザ操作を行うエージェント(本記事では WEB エージェントとする)は、WEB サイトやコンピュータのインターフェースを対象の環境とし、UI・HTML理解、計画立案、推論、操作の決定などのスキルを駆使することで、ユーザからのクエリ要求に応えます。
以下の記事を参照するとより理解が深まると思いますので、ぜひ参照してみてください。
- 古田拓毅氏 (東京大), 第58回 NLPコロキウム - Webナビゲーションにおける言語モデルエージェントの展望と課題, 2024 [概要]
- 西田氏 and 壹岐氏 (NTT人間情報研究所), 第13回 Language and Robotics研究会 招待講演資料 - Collaborative AI: 視覚・言語・行動の融合, 2023 [speakerdeck]
- 萩原正人氏, ステート・オブ・AIガイド - 2023 年注目トレンドの一つ!ツール拡張言語モデルの最前線, 2023 [記事]
MM-Navigator (Yan+'23)
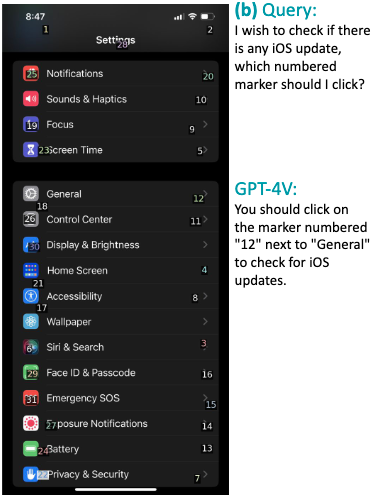
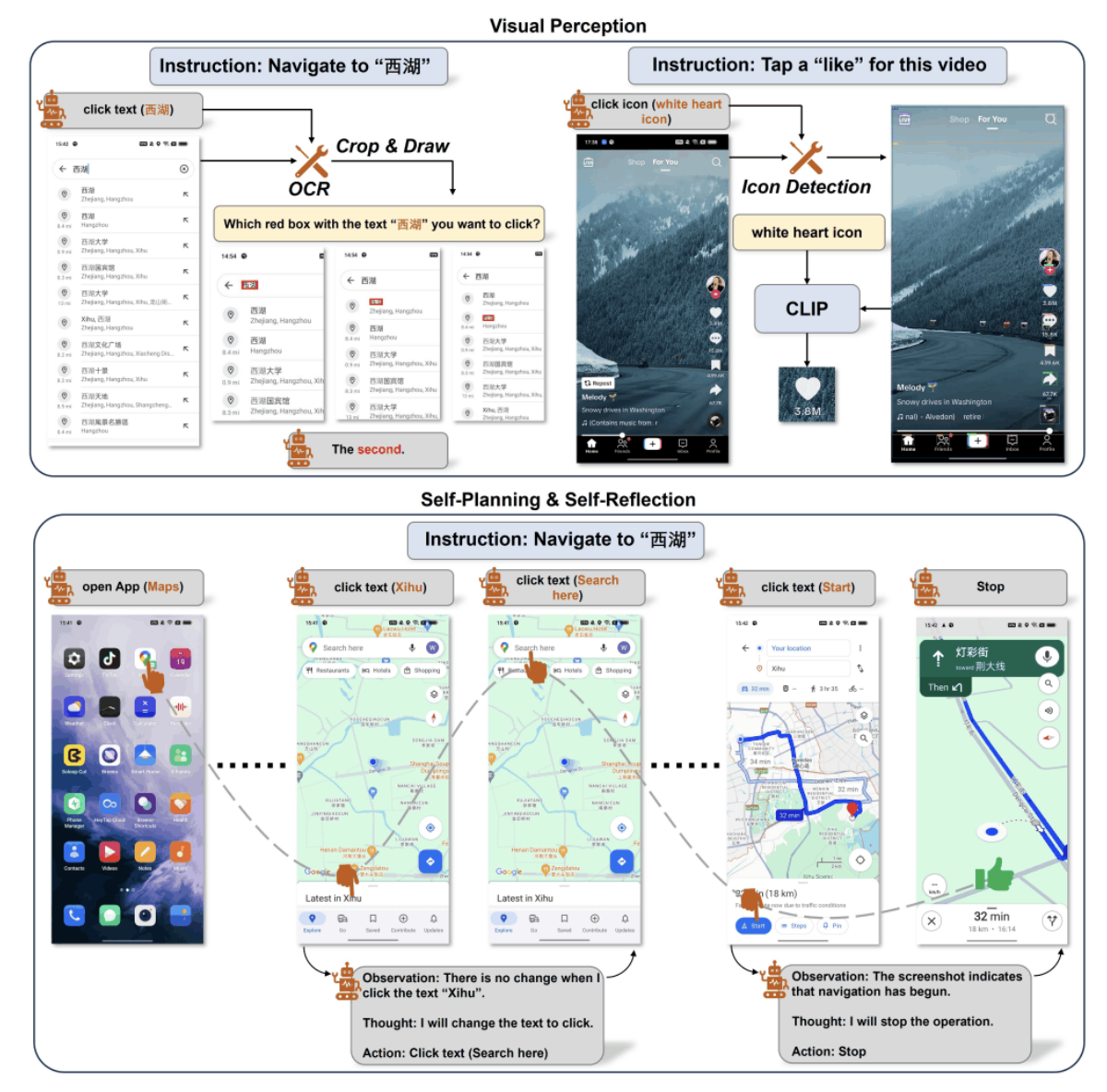
MM-Navigator は GPT-4V と Set-of-Mark を用いてスマホ操作を行う GUI エージェントです。スクリーンショットとクエリ要求を入力し、① GPT-4V が意図された行動を記述、②Set-of-Mark 付きの画像から記述された行動を遂行するコンポーネント番号を指摘することで操作を行います。
WebGPT (Nakano+'21)
WebGPT は、BingAPI を用いてブラウザ操作を可能にした言語モデルで、強化学習を含む 3 段階の学習を行うことでブラウザの操作方法を学習します。長文質問応答タスクにおける一般的である、情報検索と解答文生成による 2 段階のアーキテクチャにおいて、情報検索をブラウザ操作に置換しています。

以下の記事でも紹介されているため、詳細はこちらをご覧ください:
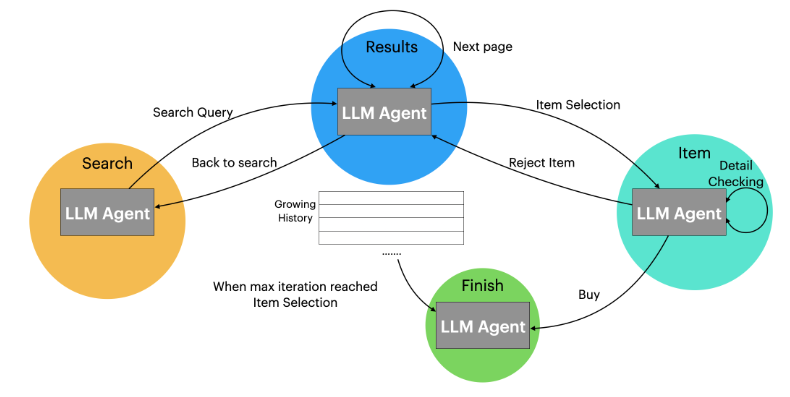
LASER (Ma+'23, NeurIPS)
LASER は、LangGraph のように、対話タスクを状態遷移の探索タスクとみなす手法です。タスク実行中に LLM エージェントが遭遇する可能性のある状態を事前に定義し、各状態で可能な行動空間とその行動結果の状態を特定します。WebShop タスクを対象に以下のような状態遷移図を定義することで、Amazon で特定のアイテムとそれに対応する対象アイテムを購入する要求に取り組んでいます。
AppAgent (Zhang+'23)
AppAgent は、タップやスワイプなどの基本操作でスマホアプリを人間のように操作するマルチモーダルエージェントです。GUI 上で操作を行うため、システムに統合する必要がなく多くのアプリで利用可能な点が特徴です。①ヒトによるデモンストレーションから行動と行動結果のペアがドキュメントに書き起こす探索段階、② エージェントがドキュメントを参照してアプリを効果的に操作・ナビゲートする展開段階、の 2 段階の推論アプローチを採用しています。
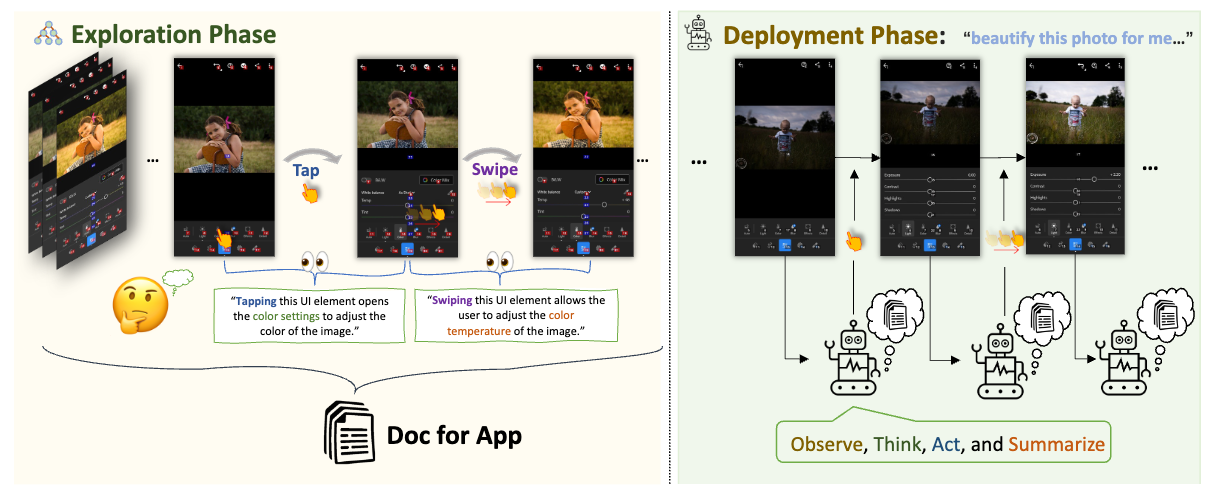

MobileAgent (Wang+'24)
MobileAgent では、スクリーンショット・クエリ要求・操作履歴から、反復的に観測・思考・行動を繰り返す LLM エージェントです。各ステップではモバイル画面のスクリーンショットをキャプチャする知覚機能が伴っており、終了プロセスを出力まで実行を繰り返します。
以下の記事でも紹介されているため、詳細はこちらをご覧ください:
SeeAct (Zheng+'24)
SeeAct は、GPT-4V を活用して WEB サイトを視覚的に認識しテキスト形式で計画を生成する行動生成を行う WEB エージェントです。クエリ要求・ウェブページ・過去の行動から各ステップにおける行動 (e.g. iPhoneカテゴリに移動する) を記述し、記述された計画を HTML 要素 (e.g. [button] iPhone) や WEB サイト上で動作する操作 (e.g. CLICK, TYPE, SELECT, etc..) に紐付けることで各ステップにおける行動を実行します。

WebAgent (Gur+'24, ICLR)
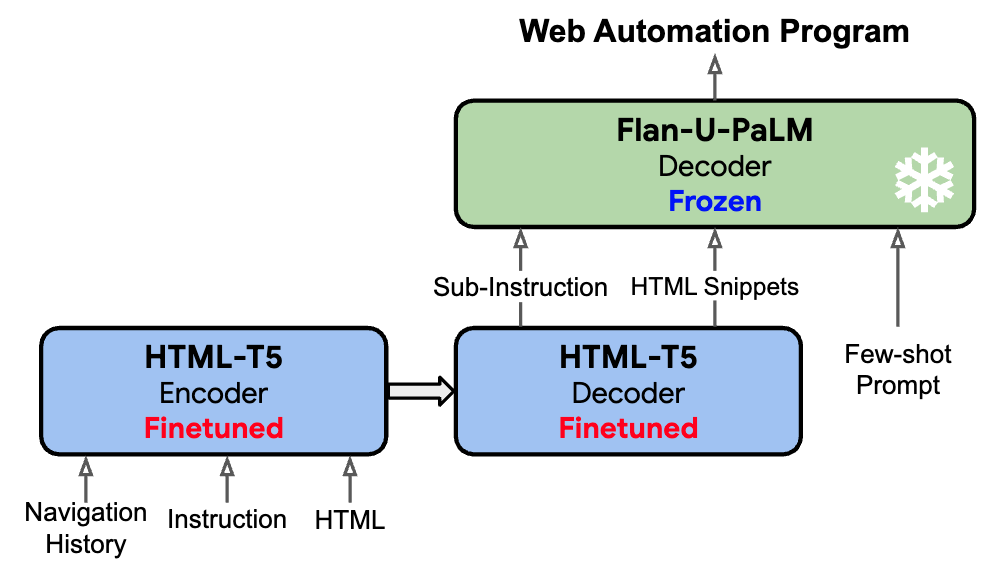
WebAgent は、実世界の複雑なHTML・行動環境で動作するエージェントで、Flan-U-PaLM (ジェネラリストLLM) と微調整済の HTML-T5 (スペシャリスト LLM)を組み合わせたアーキテクチャを採用しています。① タスク指示・HTMLを入力、② HTML-T5 が次のステップのサブ指示と関連する要素 ID を予測、③ サブ指示と要素 ID をプロンプトとして入力し Flan-U-PaLM が WEB 画面を操作するための Python selenium プログラムを生成する。HTML-T5 は、HTML のコンテキスト長かつ階層構造を考慮すべく LongT5 で使用されている Local and Global Attention を採用し、CommonCrawl から構築した HTML コーパスで事前学習を行う。
以下の記事でも紹介されているため、詳細はこちらをご覧ください:
WebGUM (Furuta+'24, ICLR)
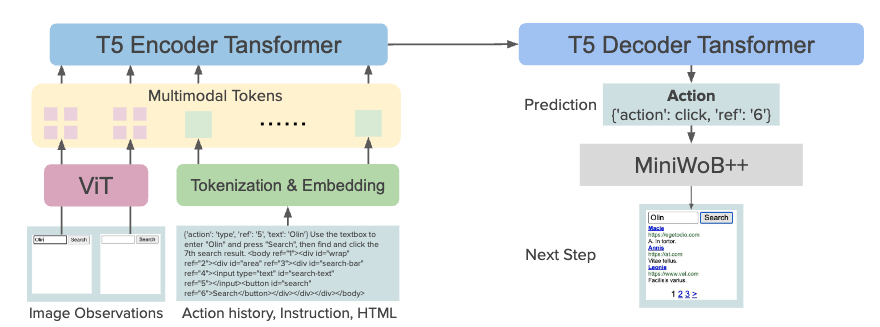
WebGUM は、WEB ページのスクリーンショットから ViT を用いて取得した視覚表現と HTML の両者をエンコードすべく、ViT による画像エンコーダをできるようにの両方から、{'action': click, 'ref': '6'} といった行動を出力するマルチモーダルモデルです。視覚エンコーダである ViT と指示学習された Flan-T5 を共同で微調整しています。 自律型エージェントの過去の成功を活用することで、新しいデータセットの構築コスト削減する finetunedLLM policy を活用することで、段階的に HTML とスクリーンショットを含む大規模なマルチモーダル行動セットを収集しています。
AutoUI (Zhang+'24, ICLR)
Auto-UI は、インターフェースと直接対話するマルチモーダルモデルです。エージェントのアクション予測性能を向上させるために、一連の中間的なアクション履歴と将来のアクション計画を利用する Chain-of-Actions を提案しています。
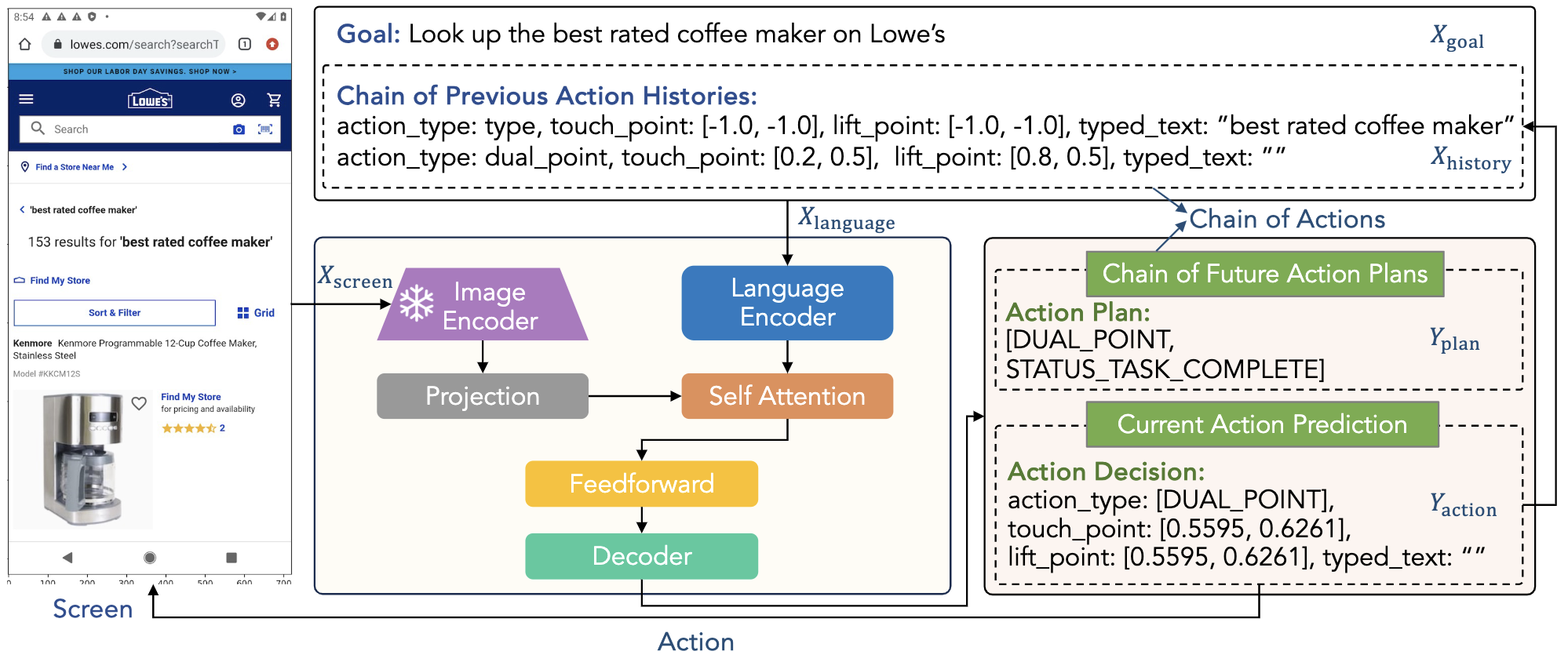
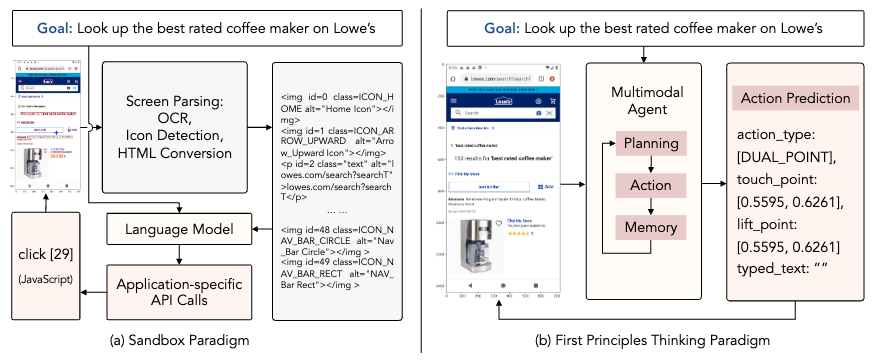
Sandbox 設定下で開発される既存のパラダイムでは、UI を OCR やアイコン検出器などの外部 API を用いて記述するため推論の非効率性やエラー伝播がしばしば問題視されてきたが、AutoUI では環境の解析やアプリケーション依存の API に頼ることなく、直接インターフェースと対話するパラダイムを提案する。
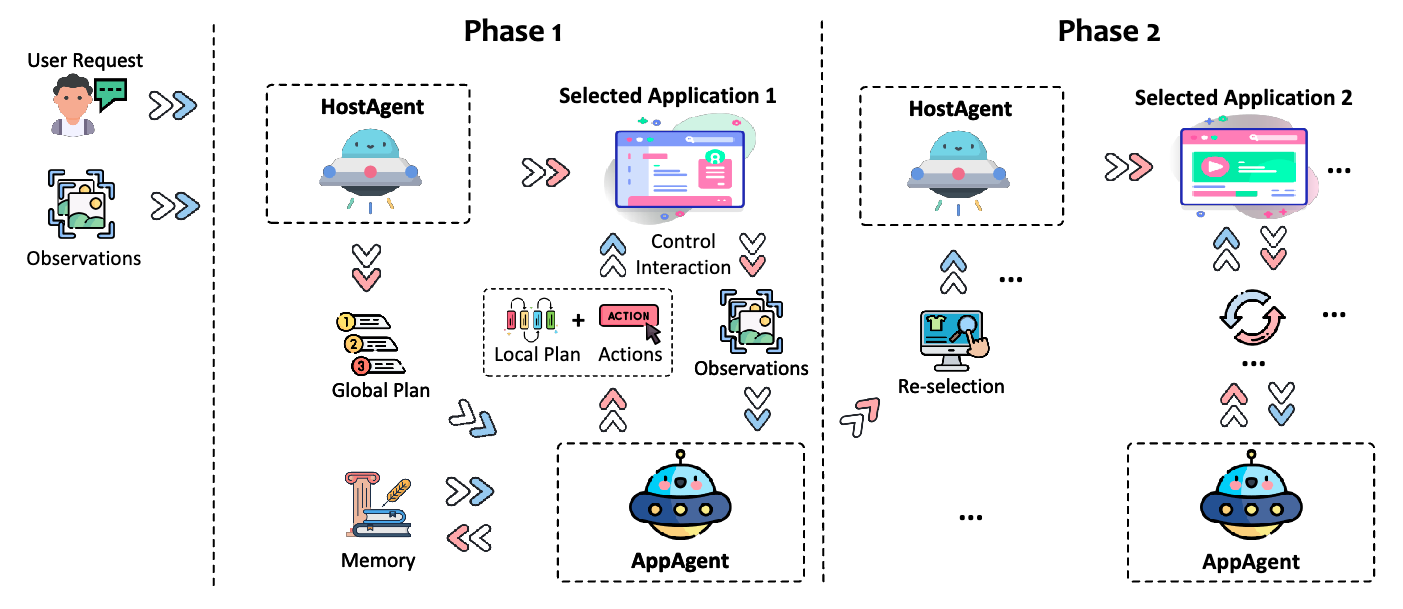
UFO (Zhang+'24)
UFO は Windows OS 上で動作する GUI Agent です。ユーザからのクエリ要求と画面が入力されると、タスクを完了させるためのアプリケーション選択を含む計画を立案し (Phase 1)、立案された計画を選択してアプリ上での操作・観測・計画修正を行います (Phase 2)。
以下の記事でも紹介されているため、詳細はこちらをご覧ください:
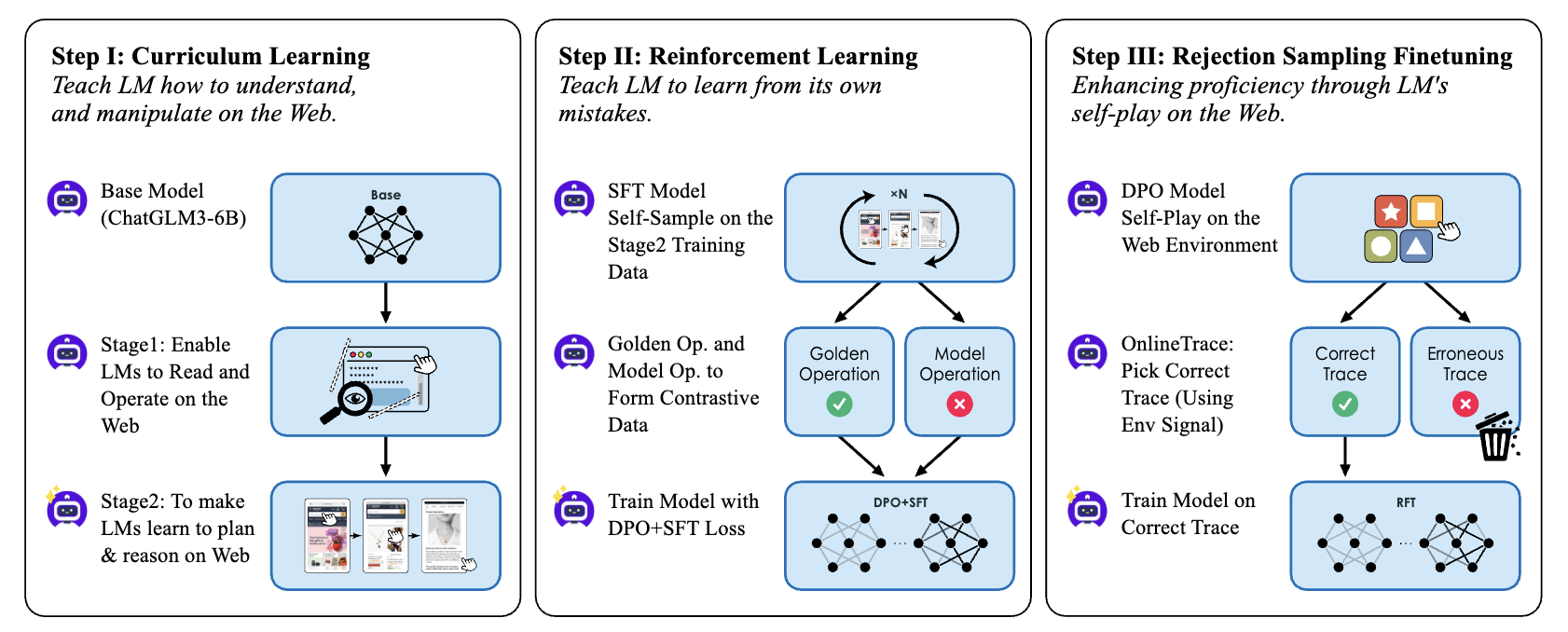
AutoWebGLM (Lai+'24)
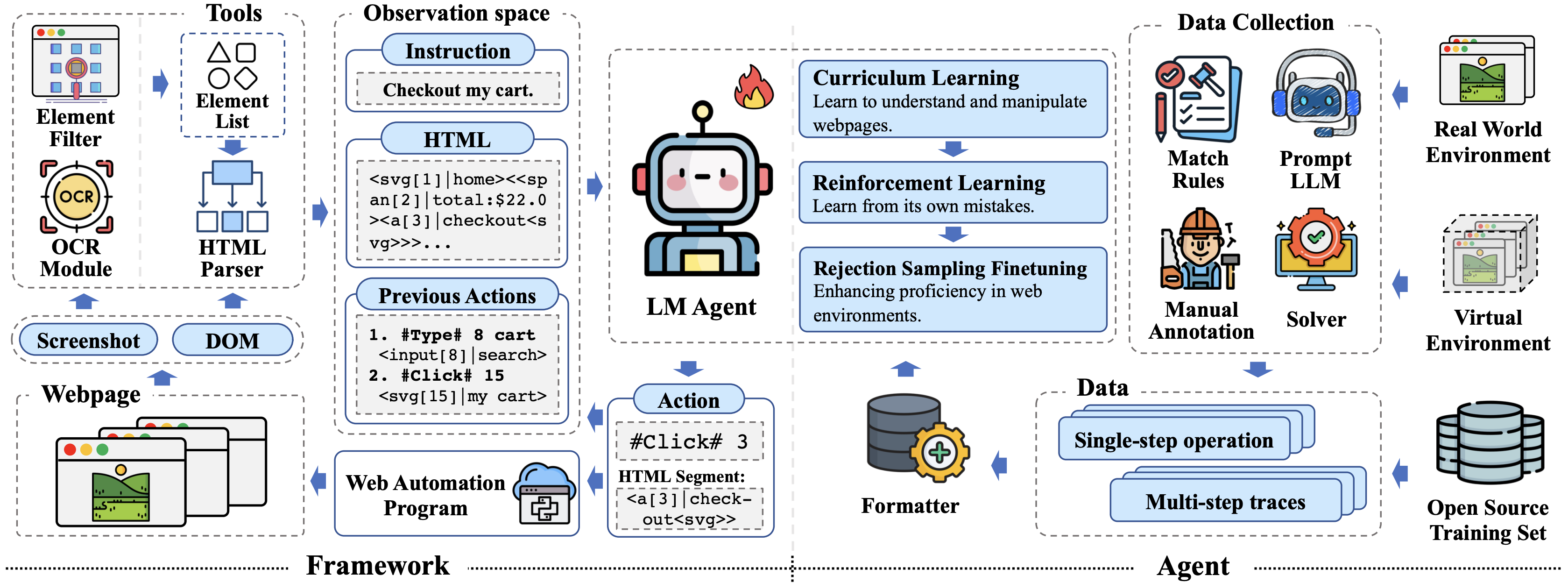
AutoWebGLM は、実際の WEB ブラウザを人間のように操作し、複雑な実世界のタスク要求自律的に達成することを目的とした ChatGLM3 ベースの WEB エージェントです。HTML を簡略化するアルゴリズムを設計し、タスク指示・簡略化された HTML・現在地・過去の操作履歴から、重要な情報を簡潔に保持しながら実行可能な行動を出力します。
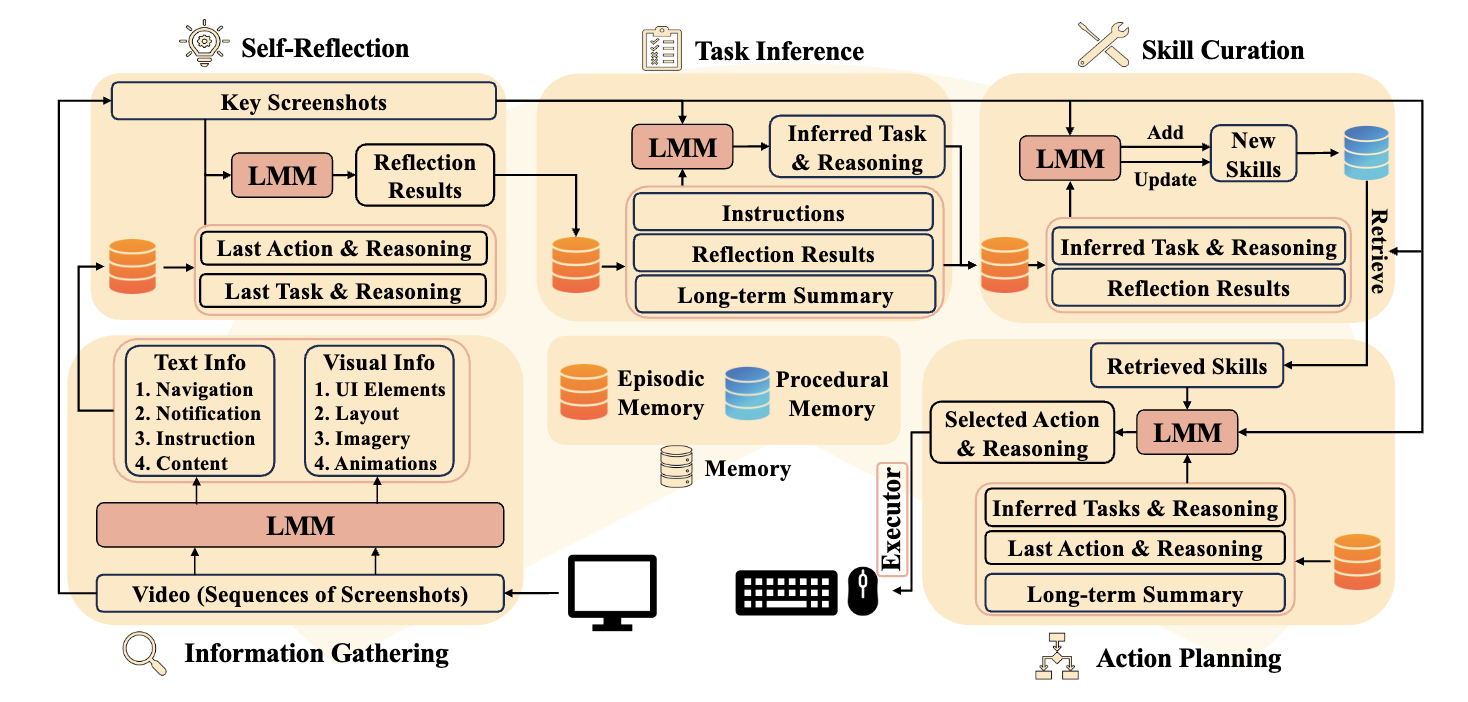
CRADLE (Tan+'24)
CRADLE は、スクリーン画像やオーディオを入力として、キーボードやマウス操作を出力するエージェントフレームワークです。内省や計画、スキルキュレーションなどの推論能力を備えることで、多様なコンピュータタスクを実行可能にすることを目的としています。
ベンチマーク
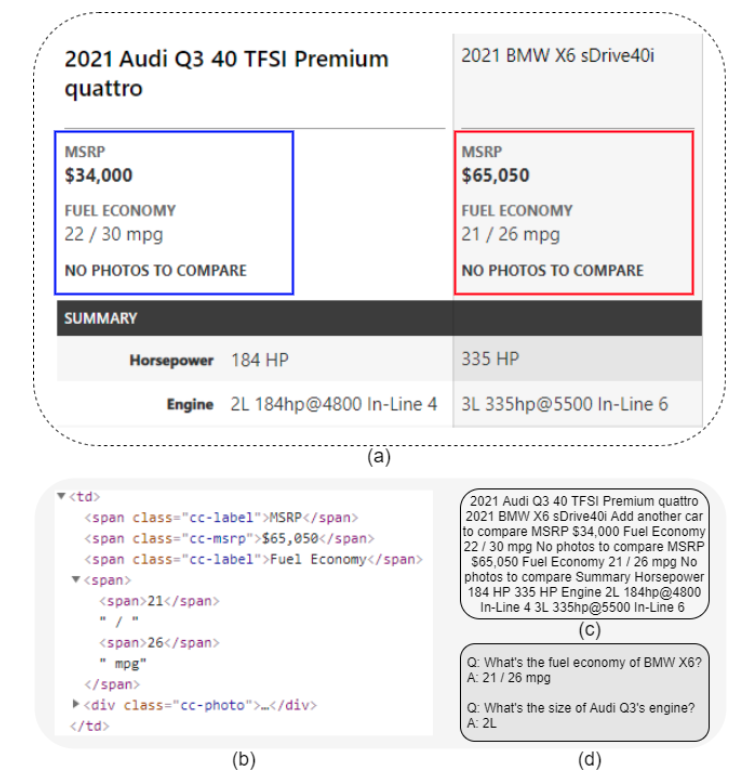
WebSRC (Chen+'21, EMNLP)
WebSRC はウェブページから収集された機械読解データセットで、質問・HTML・スクリーンショット・メタデータが含まれています。質問に回答するためにはウェブページの構造を理解する必要があり、解答は WEB ページ上のテキストスパン、または "Yes/No" の形式で定義されます。
VisualMRC (Tanaka+'21, AAAI)
VisualMRC は 35 ドメインの WEB ページから文書画像を収集した機械読解タスクのデータセットで、ベースとなる自然言語理解・解答文生成に加えて、文書レイアウトの理解やテキスト認識など様々な能力が要求されます。
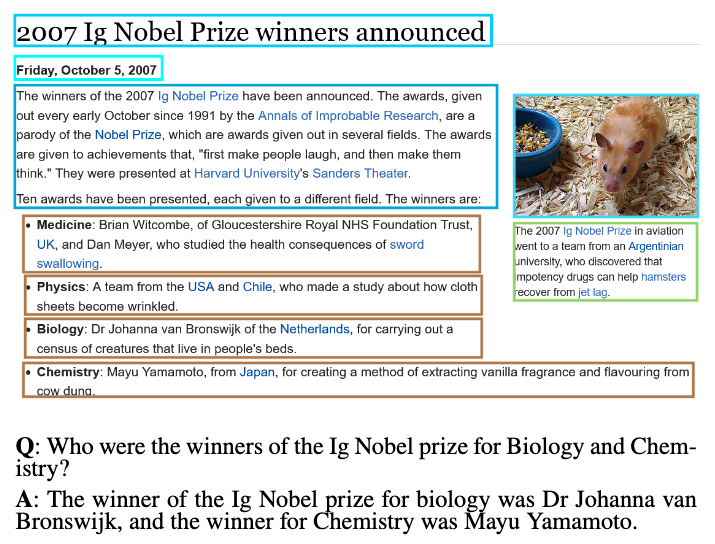
WebQA (Chang+'22, CVPR)
WebQA は視覚読解におけるマルチホップ推論のためのデータセットで、質問・HTML/スクリーンショットのリストが含まれています。質問に回答するためには、どの HTML/スクリーンショットが質問に関連しているかを識別し、質問に正しく回答する必要があります。

Design2Code (Si+'24)
Design2Code は、スクリーンショットから、対象となるウェブページに直接レンダリングするためのコードを生成するタスクです。先行研究である WebSight では合成されたページを用いるのに対して、Desing2Code はより現実世界の多様な WEB ページを使用しています。
WebShop (Yao+'22, NeurIPS)
WebShop は、amazon.com を対象としたオンラインショッピングのシミュレーションタスクで、エージェントはこの環境上で言語情報に従ってブラウザを操作をし、所望の商品の購入します。WebShop の環境は、現在のページ状態、検索やクリックといった行動、HTML ベースの観測、言語によるタスク指示、見つけた商品に応じた報酬で構成されます。
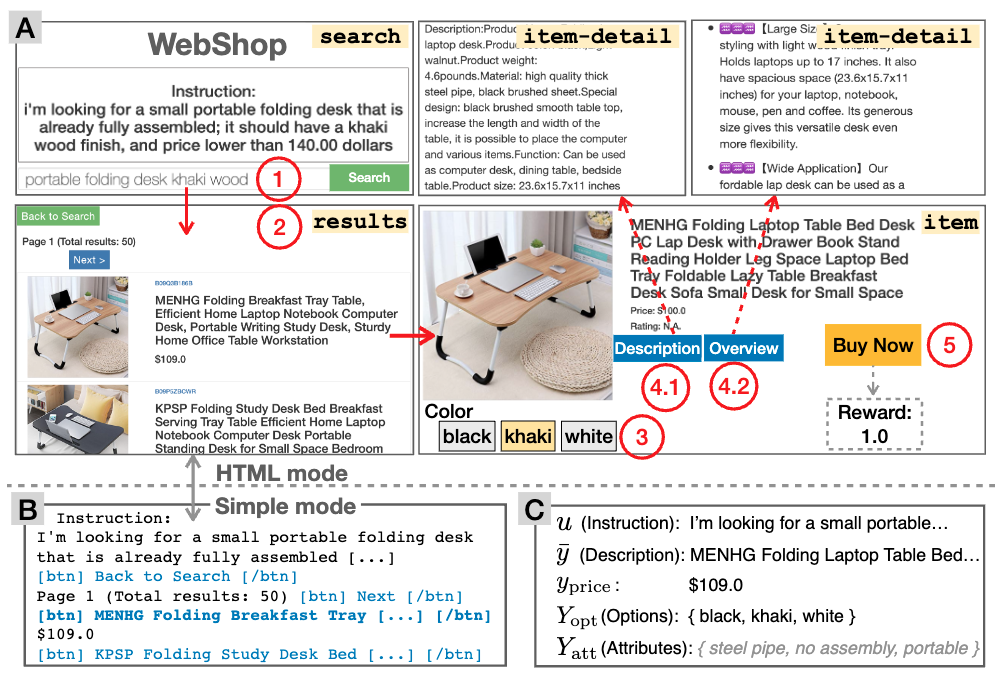
以下の記事でも紹介されているため、詳細はこちらをご覧ください:
MiniWob++ (Shi+'17; Li+'18)
MiniWoB++ は 100 以上の WEB インタラクティブ環境からなるベンチマークで、単純な操作や計算、移動する物体への追従など多様なタスクで構成されます。
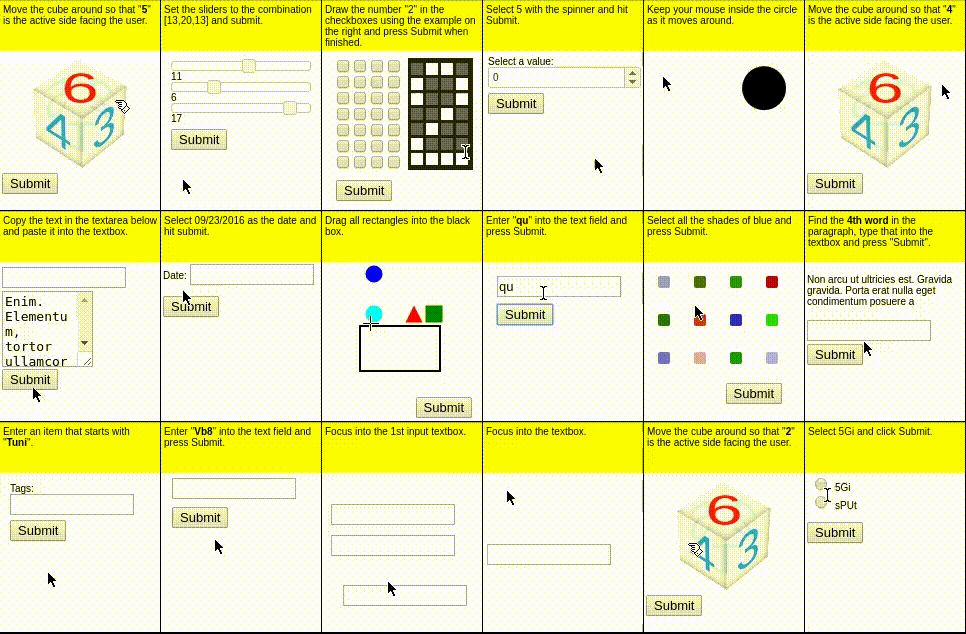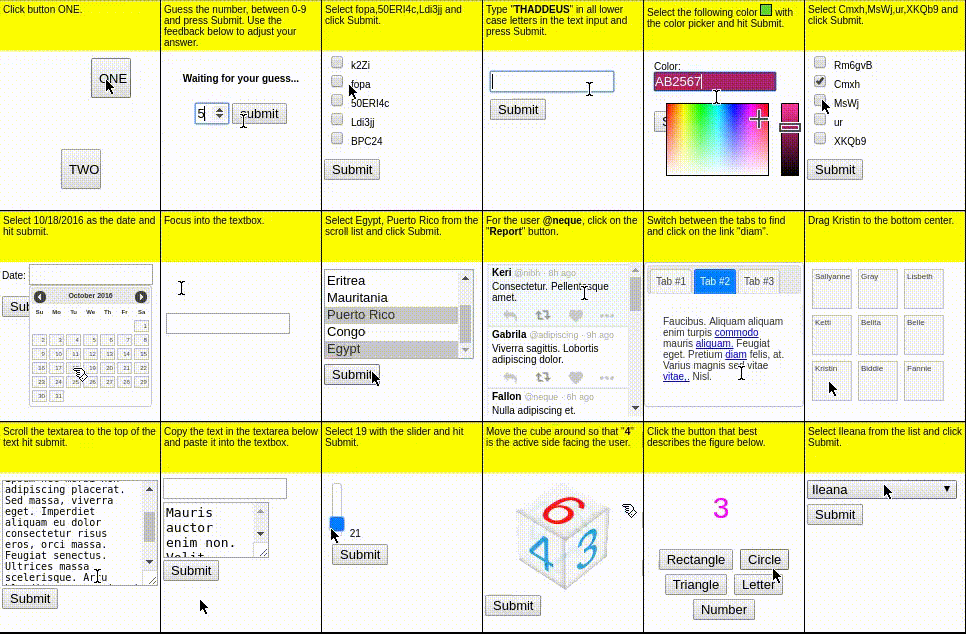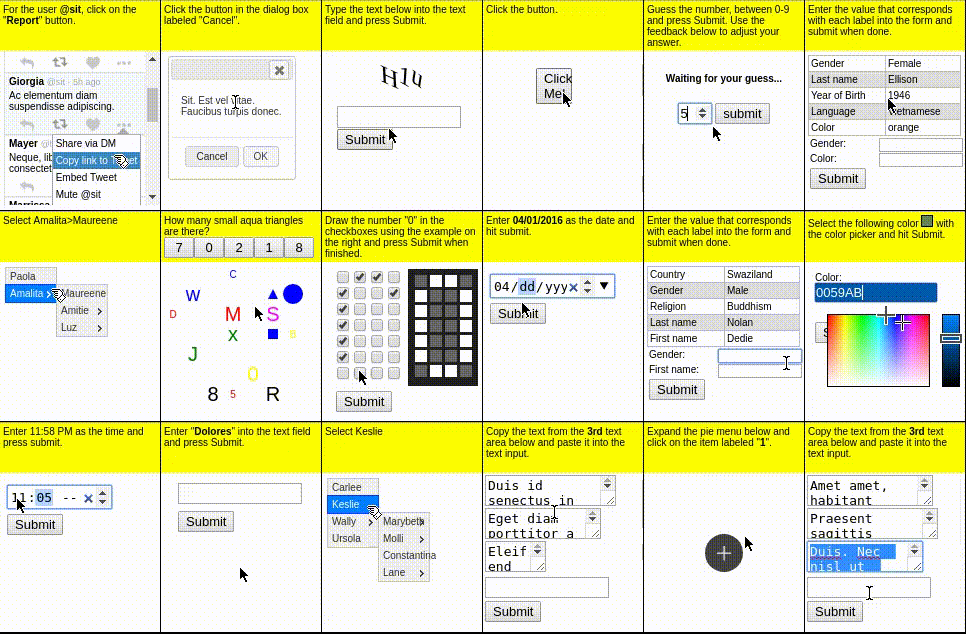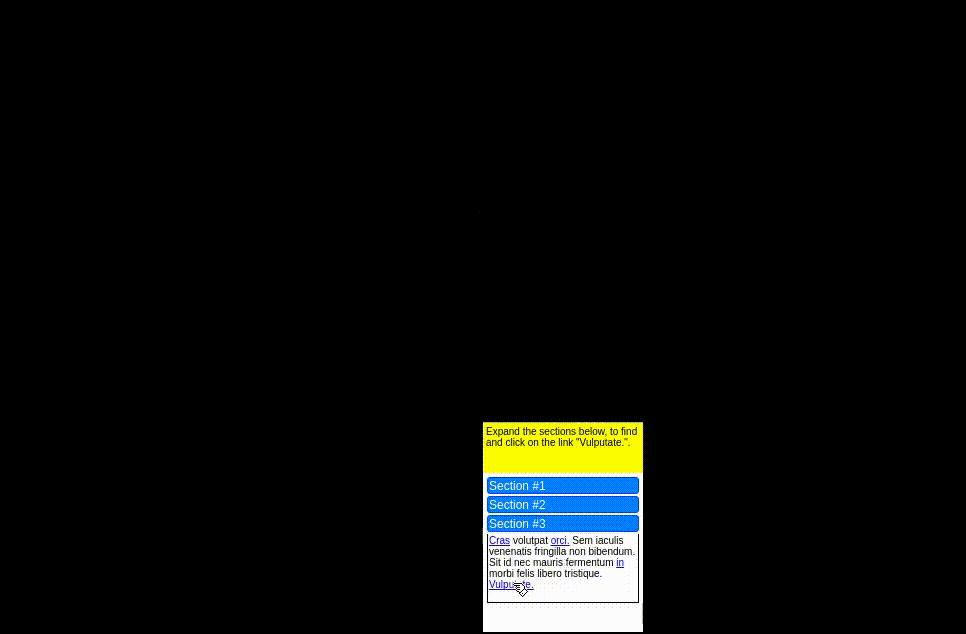
CompWoB (Furuta+'24)
単純化された問題設定である MiniWoB++ に対して、CompWoB では、LLM エージェントが未知のページに遭遇した際にどの程度操作能力が汎化可能であるか調査すべく、MiniWoB から抽出した「チェックボックスを選択する、パスワードを入力する、ダイアログをクリックして消す」といった各操作を、1 つの WEB サイトに組み合わせたタスクを提案しています。
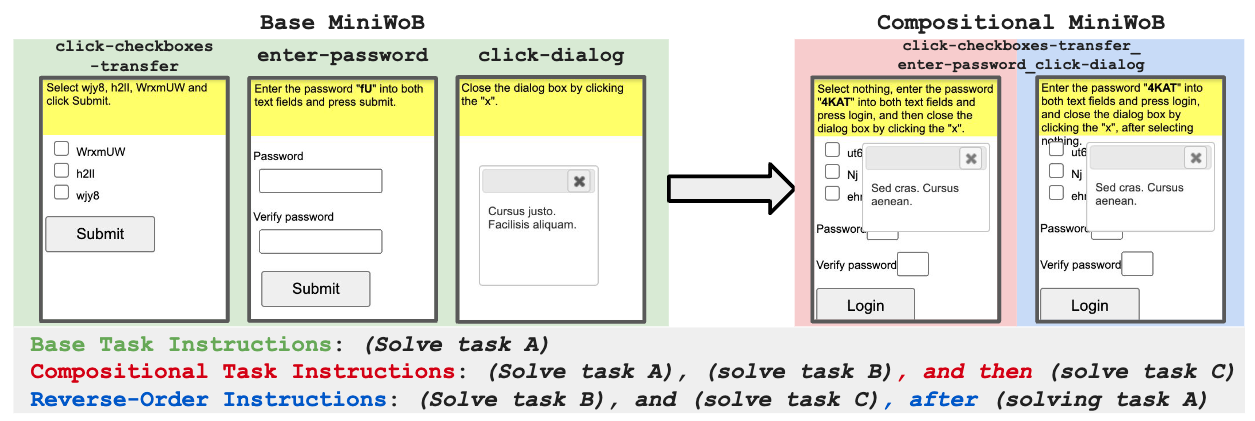
以下の記事でも紹介されているため、詳細はこちらをご覧ください:
Mind2Web (Deng+'23, NeurIPS)
Mind2Web は、任意の WEB サイト上で複雑なタスクを言語指示に従って完了する LLM エージェントのための評価セットで、31 ドメイン 137 WEB サイトから収集された 2,000 以上のタスクで構成されており、クエリ要求・一連の行動(ユーザーが対話するために選択したウェブページの要素、要素に対して実行される操作 ∈ {click, hover, type, select} のペア)、Web ページのスナップショット(HTML, DOM Snapshot, Image, HAR, Trace)が与えられ、クエリ要求を満たす操作を特定します。
WebLINX (Lù+'24)
WebLINX は、対話型ウェブナビゲーションにおける 2300 のデモンストレーションを対象としたベンチマークで、150 以上の実世界の Web サイト上で幅広いパターンをカバーしており、多様なシナリオでエージェントを訓練および評価することができます。エージェントはユーザの指示に従って Web ブラウザを操作し、マルチターンの対話形式で実世界のタスクを解決します。
WebArena (Zhou+'24, ICLR)
WebArena は、自律エージェントを構築するための自己ホスト型 WEB 環境で、オンラインショッピング、ディスカッションフォーラム、共同ソフトウェア開発、ビジネスコンテンツ管理を含む 4 つのカテゴリの WEB アプリケーションで構成されています。さらに、地図、計算機、スクラッチパッドなどのツールが組み込まれており、人間のようなタスクの実行をサポートします。また英語版 Wikipedia から特定のリファレンスマニュアルまで、多様なドキュメントや知識ベースも提供しています。
WorkArena (Drouin+'24)
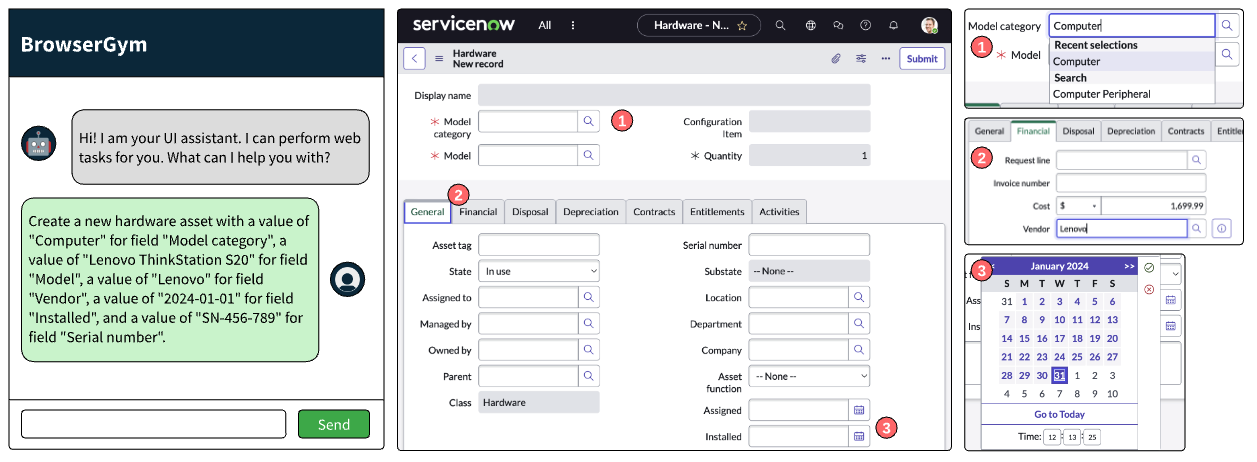
WorkArena は、ITサービス管理・人事・顧客サービス・セキュリティ運用など、様々な企業向け機能にわたるデジタルワークフローの自動化と管理のためのクラウドプラットフォーム ServiceNow における 29 の WEB タスクを対象としたベンチマークで、WEB エージェントのタスクの成功率を評価するベンチマークです。WEB エージェントが動作するための BrowserGym という構築環境も同時に提案しており、マルチモーダルな観測や行動リストを提供しています。
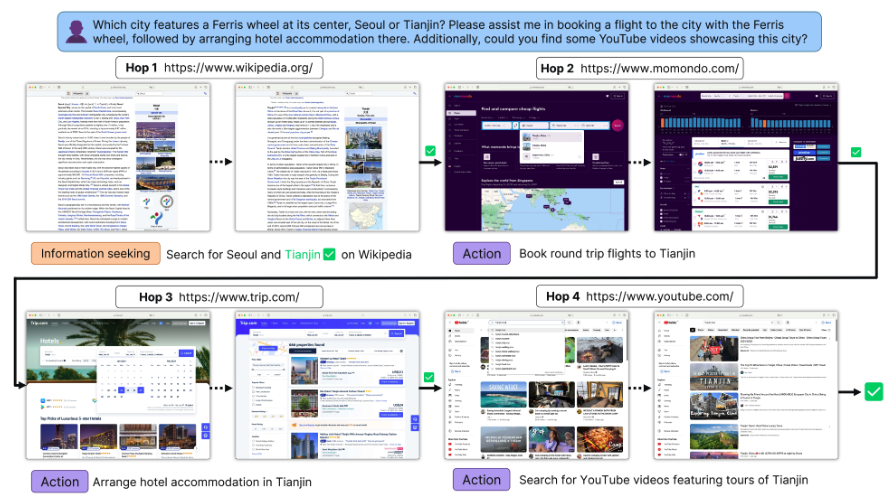
MMInA (Zhang+'24)
MMInA はヒトによって作成された 1,050 件 のマルチモーダルなベンチマークで、様々なウェブサイトからの情報や収集や行動実行を必要とするベンチマークです。各タスクは、ウェブサイト間の移動が平均 2.85 回発生し、タスク遂行までに平均 12.9 回の行動を必要とします。
おわりに
ここまで読んでいただきありがとうございました!
AIエージェントに関する論文等の一覧はこちらにまとめていますので、こちらもご活用ください。
Algomatic では LLM を活用したプロダクト開発等を行っています。 LLM を活用したプロダクト開発に興味がある方は、下記リンクからカジュアル面談の応募ができるのでぜひお話ししましょう!
参考
- 古田拓毅氏 (東京大), 第58回 NLPコロキウム - Webナビゲーションにおける言語モデルエージェントの展望と課題, 2024 [概要]
- 西田氏 and 壹岐氏 (NTT人間情報研究所), 第13回 Language and Robotics研究会 招待講演資料 - Collaborative AI: 視覚・言語・行動の融合, 2023 [speakerdeck]
- 萩原正人氏, ステート・オブ・AIガイド - 2023 年注目トレンドの一つ!ツール拡張言語モデルの最前線, 2023 [記事]
- Su氏, IJCAI 2023 Symposium on Large Language Models - Language agents: a critical evolutionary step of artificial intelligence, 2023 [スライド]
- AI-SCHOLAR - HTMLデータでも言語モデルの事前学習が可能!?, 2022 [記事]
- Takumu氏, AI-SCHOLAR - LLMを応用した高性能ウェブアシスタントの開発に重要な要素とは?, 2023 [記事]
- Takumu氏, AI-SCHOLAR - Mobile-Agent:スクリーンショット解析によるモバイルアプリ操作の自動化, 2024 [記事]
- Tomohiro Yamashita氏 (東京大), DL輪読会 - UFO: A UI-Focused Agent for Windows OS Interaction, 2024 [スライド]
- r-kaga氏,
WebArena: A Realistic Web Environment for Building Autonomous Agentsを読んだ, 2024 [ブログ]
関連
- LangChain - PlayWright Browser [Toolkit]
- LangChain - Automating Web Research [Blog]
- Adept Team, Introducing Adept Experiments, 2023 [Announcements]
- LaVague [GitHub]
- Windrecorder [GitHub]
- Basepilot
- PowerToys
