こんにちは。Algomatic LLM STUDIO 機械学習エンジニアの宮脇です(@catshun_)。
本記事では LLM を用いたエージェントシステムの基盤となる「計画実行機能」について、ユーザ要求を構成的に分解して立案されたタスク系列(=計画)を並列実行する LLM Compiler (Kim+'23) について紹介します。
Kim+’23 - An LLM Compiler for Parallel Function Calling arxiv.org
また LLM Compiler を LangGraph で実装した例の解説を以下に記載していますので同時に参照ください。
おことわり
- 本記事では解説のため論文中の事例を翻訳等によって改変したり、論文内の記述を省いている場合があります。詳細については必ず論文を参照してください。
- 本記事は LLM 等の背景知識を持つ方向けの記事になります。
- 記事の誤り等がありましたらご指摘いただけますと幸いです。
1. 本研究の概要
- 複雑なユーザ要求に対して、構成性を仮定してタスク系列として計画的に推論を実行する際、複数のタスクを並列実行可能に編成する LLM Compiler を提案する。HotpotQA において、逐次的なタスク実行を伴う ReAct に対して LLMCompiler は 1.8 倍の高速な推論実行を達成した。
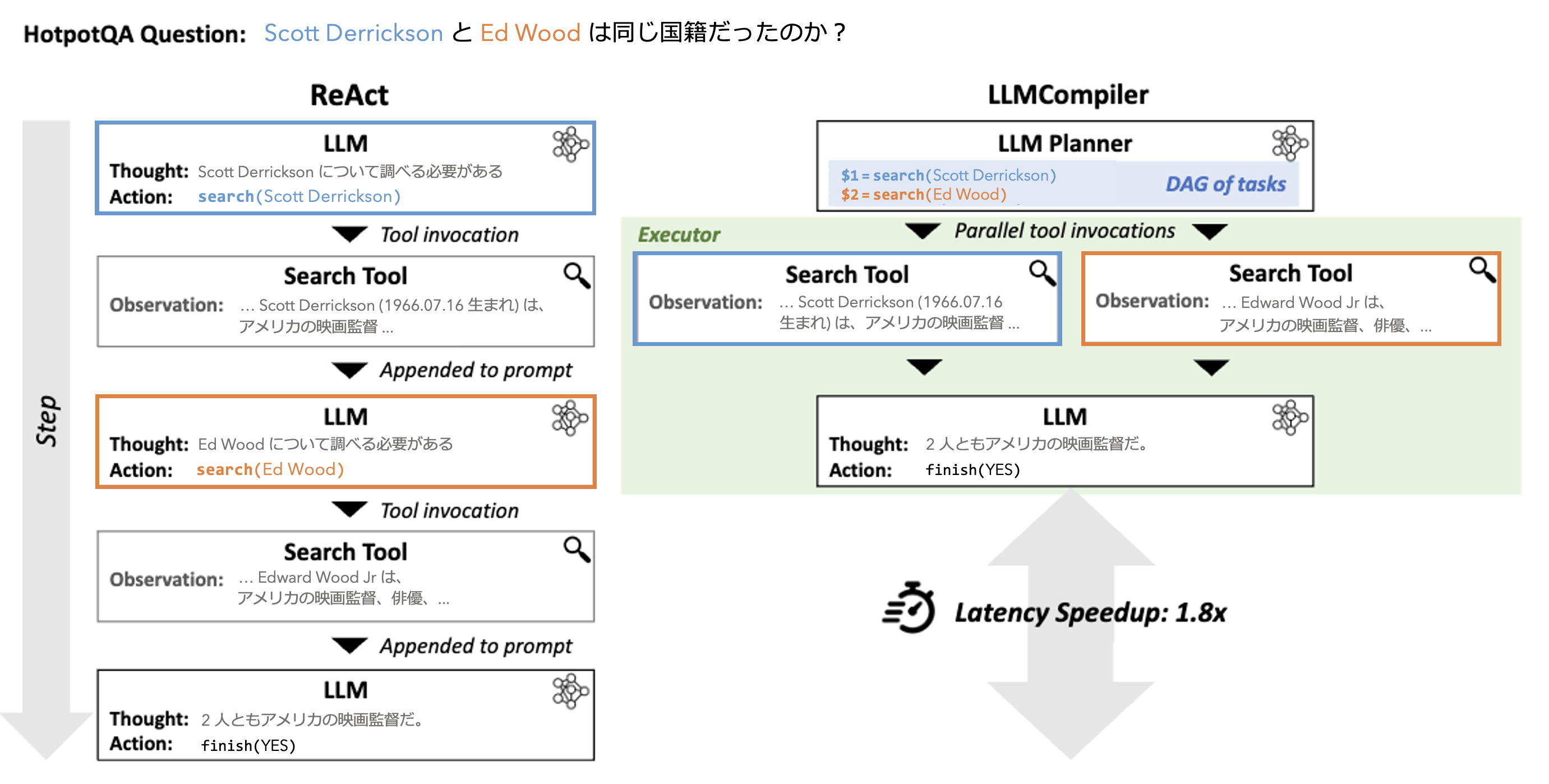
2. 先行研究と比べてどこがすごい?
ReAct (Yao+'23) との比較
ReAct のようなタスク実行と思考のフェーズを繰り返す推論手法 (interleaved 型推論) は以下のような欠点が存在する。
Repetitive Function Calls: LLM の推論能力が不十分である場合や中間タスクの実行結果の連結に不備である場合に、関数の重複呼び出しや無限ループが発生する。
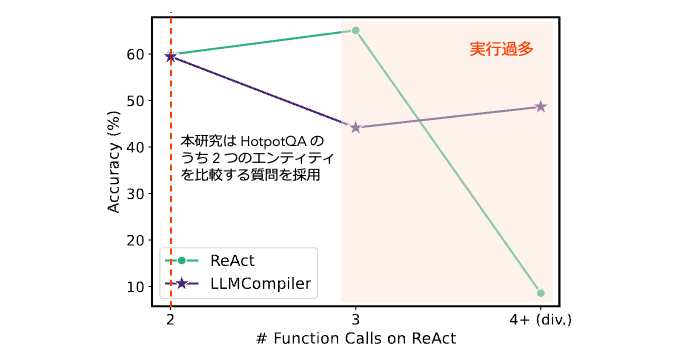
図A.4. HotpotQA における ReAct, LLMCompiler の呼び出し回数と正解率の関係。ReAct において 4 回以上の関数呼び出しが発生する場合に正解率低下を伴うことから、発散的動作が発生していることが分かる。 Premature Early Stopping: 目的に対してボトムアップに推論を行うことから中間推論過程が複雑になることで早期停止や不完全な情報に基づく意思決定が発生する。
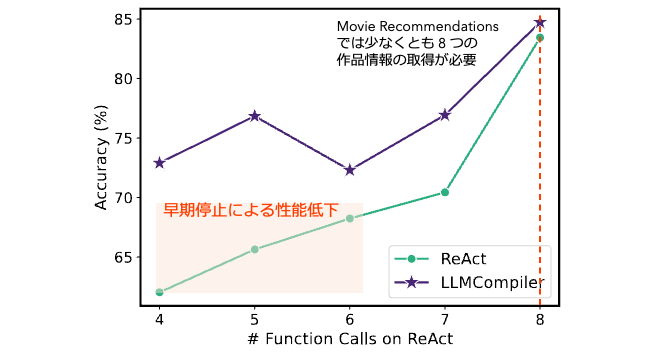
図A.2. Movie Recommendation における ReAct, LLMCompiler の関数呼び出し回数と正解率の関係。ReAct の早期停止が正解率低下に影響していることが分かる。 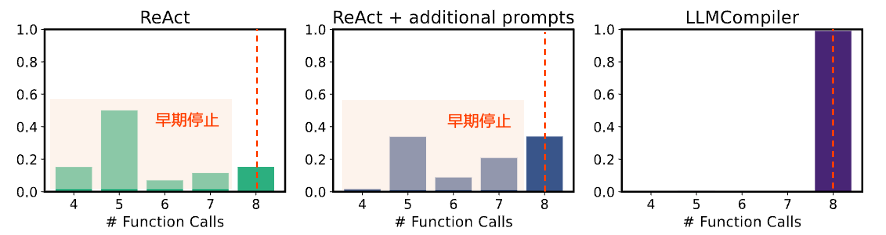
図A.1. Movie Recommendation における ReAct, ReAct+, LLMCompiler の関数呼び出し回数の比較。LLMCompiler が 8 回の関数呼び出しを行うが、ReAct では 85% の例で早期停止する。これは 精度にも影響しており、それぞれ 68.60, 72.47, 77.13 の正解率となっている。
LLM Compiler は、ユーザ要求を構成的に分解する推論手法 (decomposed-first 型推論) を採用することで、トップダウンに立案された推論計画に基づいて中間推論過程が形成されるため上記のようなエラーが緩和される。またタスク実行後に思考フェーズを含まないため、ReAct に比べて中間推論過程が複雑になりにくい。
ReWOO (Xu+'23) との比較
ReWOO は decomposed-first な計画立案を伴う推論手法であるが、立案されたタスク系列は上から逐次的に実行される。一方で LLM Compiler は 並列実行可能なタスク集合を LLM が決定する ことでより高速な実行が可能となる。
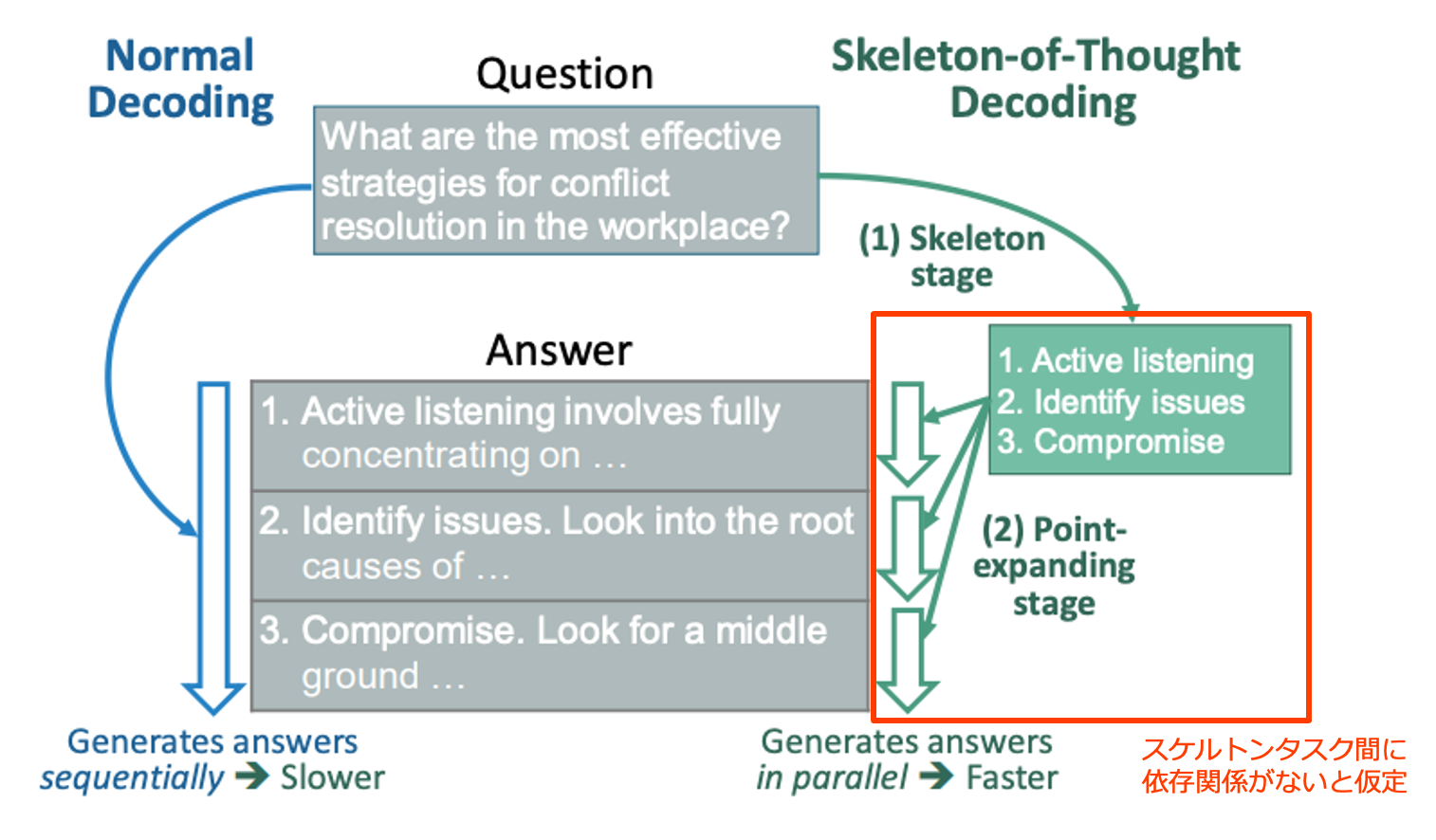
Skelton-of-Thought (Ning+'24) との比較
Skelton-of-Thought (SoT) は、骨子生成 (Skelton stage) と肉付け (Point-expanding stage) の 2 段階による言語生成手法で、生成された複数の骨子点に対して肉付けを並列に行うことで生成速度を向上させる。しかし SoT ではスケルトンタスク間に依存性がないことを前提としている。LLM Compiler は、SoT で対象としない相互依存性を持つ一連のタスクを Planner がプレースホルダ変数を用いて表現することでこの問題に対処する。
3. 技術や手法のキモはどこ?
アーキテクチャ
LLM Compiler は LLM Planner, Task Fetching Unit, Executor の 3 つのモジュールによって、複雑なユーザ要求を構成的かつ効率的にタスク系列に分解し並列関数呼び出しを可能にする。
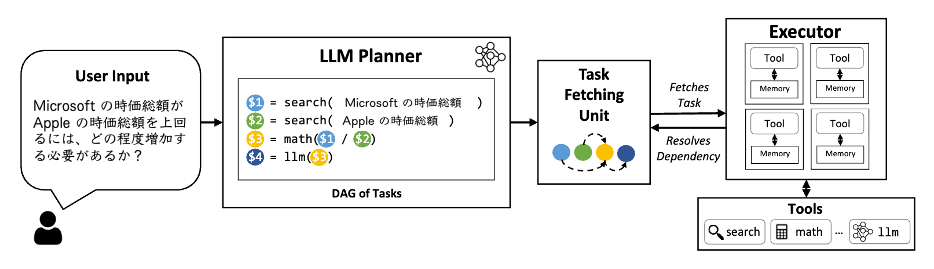
$1, $2 が並列実行される。
LLM Planner
LLM の優れた構成性や推論能力を活用して、ユーザのクエリ要求から、実行すべきタスク系列をその依存関係とともに生成する。 具体的には、ユーザからのクエリ、ツール定義書、文脈内計画例題を入力として受け取り、タスク系列を出力する。

Task Fetching Unit
Planner が立案したタスク系列おいて並列処理を含む実行準備が完了次第、Executor にタスクの実行要求を送信する。単純な fetch, queue のメカニズムで実装される。依存関係を持つタスクの出力結果はプレースホルダ型変数 $k, $k+1, .. を設定し、先行する依存タスク $k が終了次第、プレースホルダ変数$k にタスクの実行結果が格納される。
Executor
Task Fetching Unit から受理したタスクは全て独立に実行可能であると仮定されるため、受理したタスクを非同期に実行する。Executor では特定のタスクごとに事前に指定されたツールを呼び出すことが可能である。
4. どうやって有効だと検証した?
評価方法
GPT-{3,4} と LLaMA-2 を使用して、中間推論の実行タイプ別に以下の評価セットを用いて正解率、レイテンシ、トークン消費コストで評価。
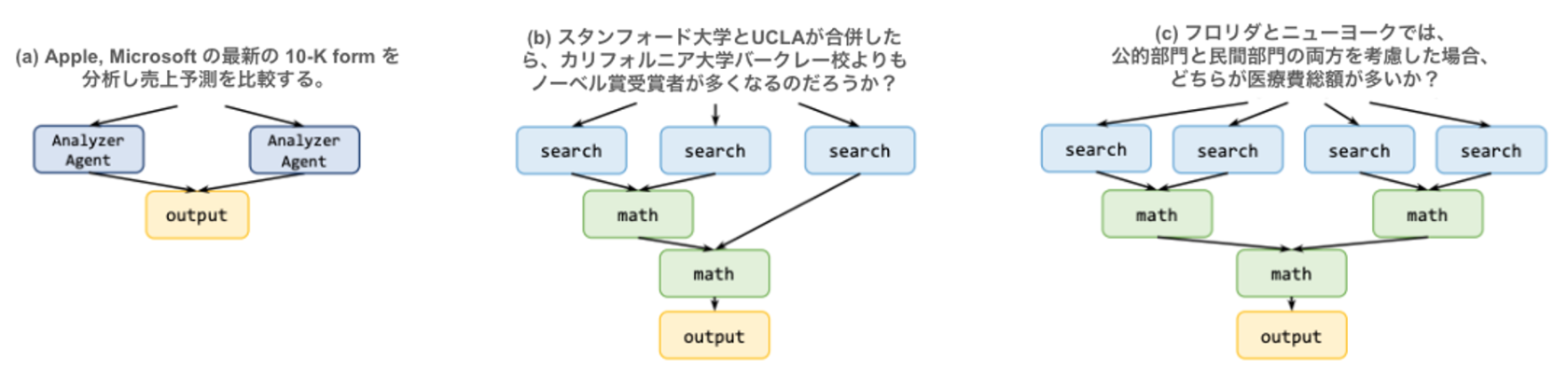
HotpotQA (Yang+'18): マルチホップ推論の評価セットで本研究では検証セットを使用。図3.(a) のような 2 つのエンティティを比較する質問 1500 件で評価。
Movie Recommendation (Srivastava+'23): 4 つの選択肢から別の 4 つの映画集合と類似する映画を特定する問題。500 件の評価セットで評価。図3.(a) のような推論パスで 8 並列の検索が必要。

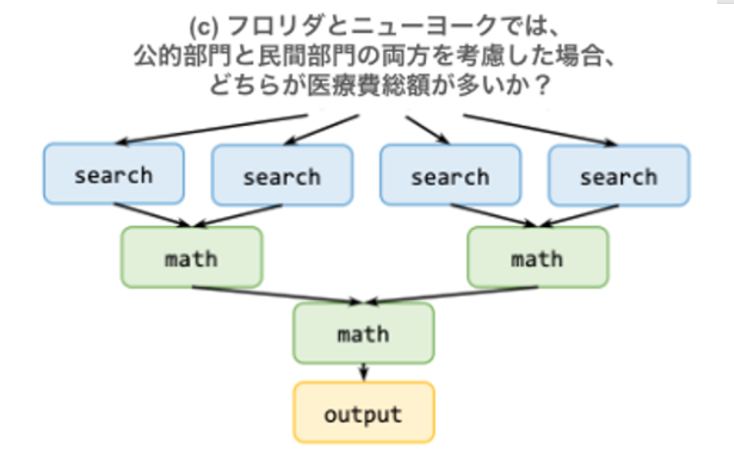
Movie Recommendation の質問と解答の例。 ParallelQA: 異なるエンティティの事実詳細に関する 113 件の数学的質問の評価セット。IfQA (Yu+'23) を踏襲して著者らが構築。図3. (b,c) のような推論パスの構築が必要。
e.g. If Texas and Florida were to merge and become one state, as well as California and Michigan, what would be the largest population density among these 2 new states?
Game of 24 (Yao+'23): 4 つの数と基本的な算術演算を用いて 24 を生成するタスク。例えば {2,4,4,7} が入力された場合
4 × (7 − 4) × 2 = 24という計算過程を導く。100 件の異なる問題で評価。中間試行結果に基づく計画の再編成 が必要。WebShop (Yao+'23): 商品購入指示が与えられ、ウェブショップ環境からアイテムを検索して購入アイテムを決定するタスク。500 件の指示で評価。LLM Compiler は ① 10 個のアイテムのリストを出力する検索機能 ② 見つかった各アイテムのリンクをクリックし、オプション、価格、属性、および利用可能な機能に関する情報を取得するエクスプローラ機能をツールとして採用。最後に収集された情報に基づいて入力指示に最も一致するアイテムを決定する。本記事では解説の対象外とする。
先行研究との比較
-- LLM Compiler は並列可能なパターンを特定することができるか?
タスク系列は互いに独立しており並列実行可能である HotpotQA, Movie Recommendation を用いて LLM Compiler が並列可能なパターンを特定することができるかを検証した。 ReAct の設定と同様にウィキペディア検索ツールを採用した(Lookup Tool はタスク解決に不要であるため採用しない)。
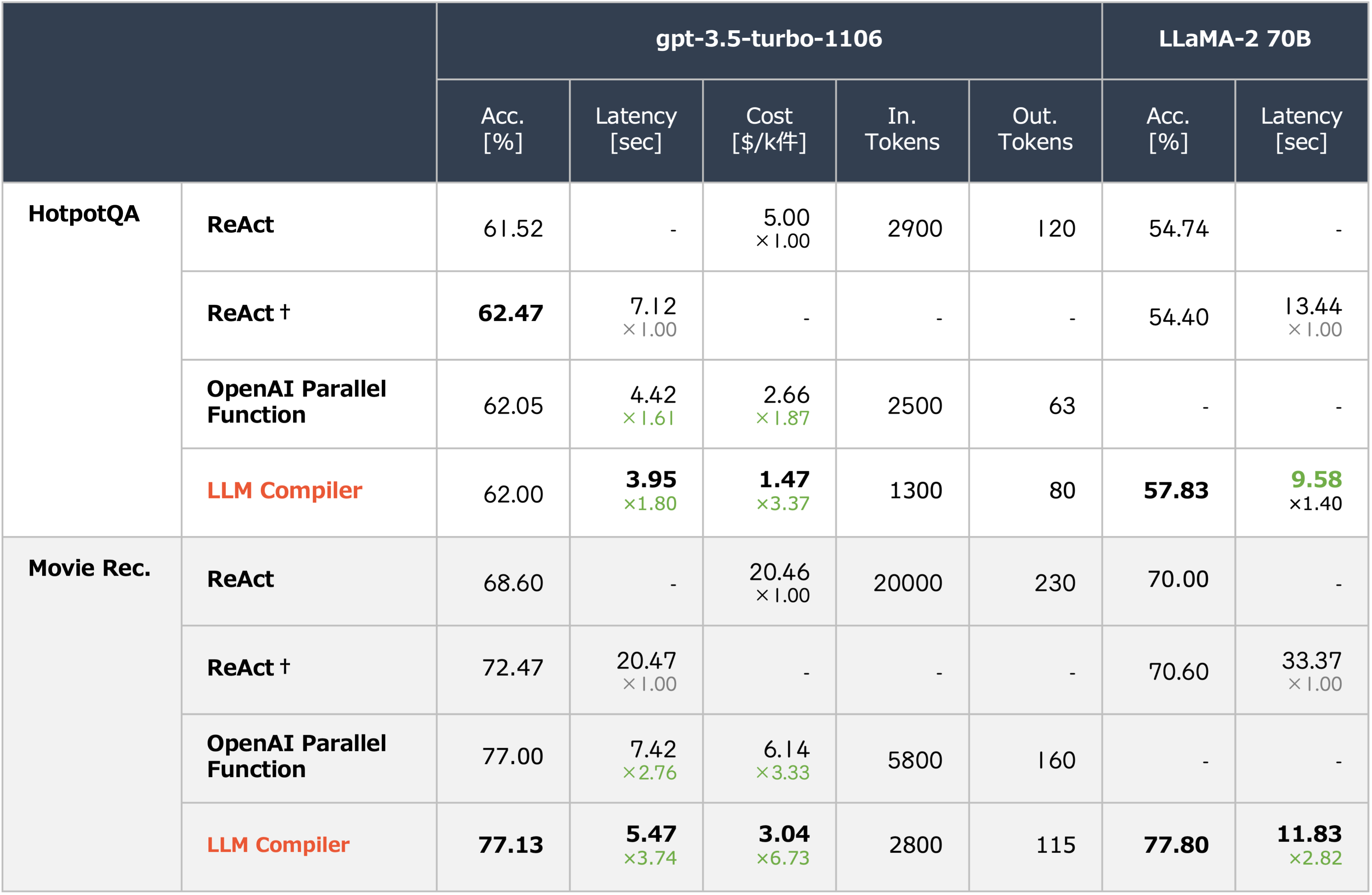
上の表 1-2 から、LLM Compiler は ReAct† に比べて同等またそれ以上の正解率を保持しつつ高速化を実現した。並列実行に加えてトークン効率の良さが高速化の要因であることが分かる(並列実行のみの影響は不明)。 ReAct が OpenAI Parallel Function Calling や LLM Compiler と比較して正解率が低いのは、前述した図 A.1,2 から早期停止が原因の一つであると考えられる。
-- LLM Compiler は複雑な推論計画でも同様に高性能な推論が可能か?
複雑なタスク依存関係を含むシナリオで LLM Compiler の計画能力を体系的に評価するため、図3 (b,c) のような推論パスの構築が必要となる ParallelQA を構築して評価を行った。 ツールは ① 検索ツール ② 数学的問題を解く LLM エージェント(入力クエリを解釈し、適切な数式で numexpr 関数を呼び出す)を採用した。
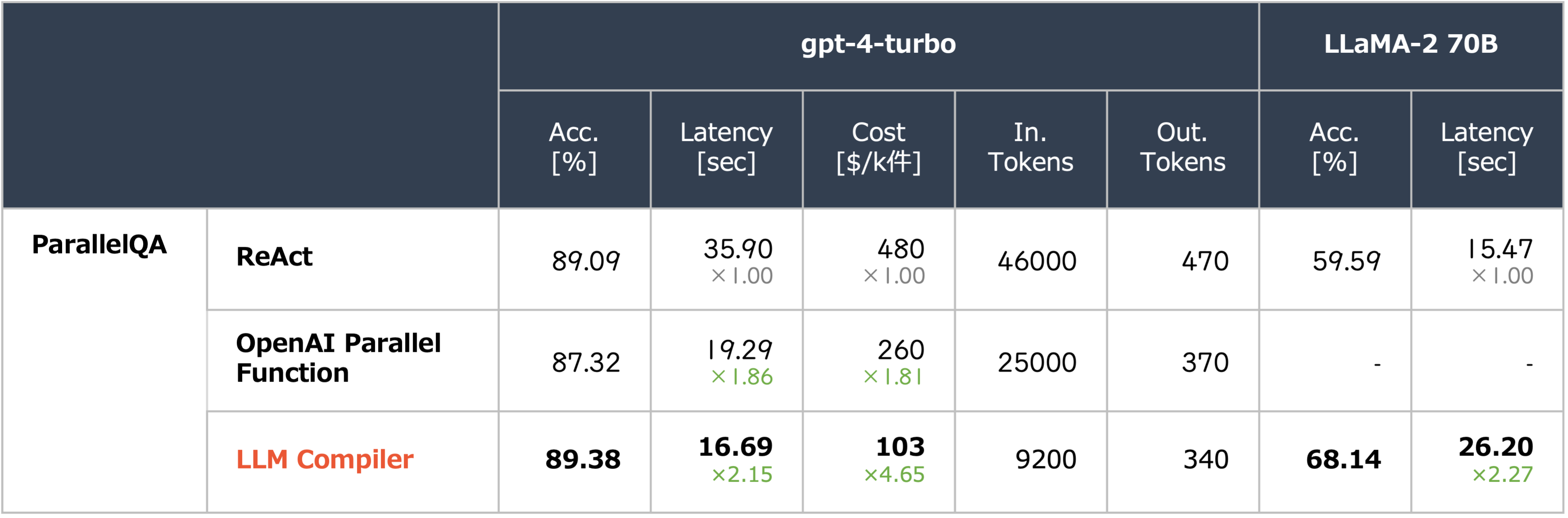
上の表 1-2 から、LLMCompiler が ReAct に対して同程度の正解率を示しつつ 2.15~2.27 倍の高速化を実現した。特に LLaMA-2 では LLMCompiler が +8.55% の正解率向上を示している。
Appendix.2 のエラー分析では、Parallel QA 113 件のうち 3 件のみが計画誤りであることが示されたが、これは複雑な問題を複数のタスクの依存関係に分解する LLMCompiler の有効性が強調された。
また LLM Compiler が ReAct, OpenAI Parallel Function に対して 大幅なコスト削減 を実現した。これは LLMCompiler が LLM の呼び出し頻度を減らしていることに起因している。例えば図 3.c において、OpenAI Parallel Function では、①検索タスク ②計算タスク ③最後の計算タスク の 3 回 LLM 呼び出し が必要であるが、LLM Compiler は計画に基づく推論実行により 1 回の LLM 呼び出し でこれを実現する。
-- LLM Compiler は中間的な観察によって動的な再計画が求められる場合でも推論実行が可能か?
Executor からの中間実行結果を LLM Planner に送り、LLM Planner が関連する依存関係を持つ新しいタスク系列を再生成することで LLM Compiler における再計画機能を実装し、Game of 24 で評価した。ここで使用するツールは Tree-of-Thoughts ら適応された ① thought proposer ② state evaluator ③ state evaluator の評価に基づいて thought proposer から上位 k 個の候補を選択する top k select の 3 つを用いる。これらのツールがすべて実行された後、どの提案も 24 とならない場合に再計画を実施する。

上の表 1 から Tree-of-Thought と比較して、LLM Compiler は正解率をわずかに改善しつつ、×2.01~2.89 倍の実行速度を達成した。
ストリーム実行による更なる高速化
Planner によるタスク系列の生成をストリーム実行にすることで、各タスクの依存関係がすべて解決されるとすぐに Executor が処理できるようになり、更なる高速化が期待できる。

表 A.1 ではストリーミングを使用することで、特に複雑な推論パスが要求される ParallelQA において ×1.30 倍の高速化が実現可能であることを示した。HotpotQA, Movie Recommendations においては Planner から生成されたタスク系列に依存関係がほとんど存在しないために高速化の向上幅がわずかであると考えられる。
5. 議論はある?
知見
- Task Fetching Unit の並列実行・ストリーミングは実応用においても重要な手法。
- ReAct に対して正解率だけでなく、実行速度・コストの面で効果的な性能を示している点が良い。
議論・改善の余地
- 高速化の要因がトークン効率と並列実行による 2 つであり、並列化のみによる高速化の影響が分からないため、ReWOO や対照実験による比較があっても良い。
- もう少し抽象化されたシナリオでのユーザ要求(e.g. 昨年度の売り上げと売り上げに寄与した項目についてレポートして)における議論があっても良い。例えば、必要とされるツール数が膨大となる場合の推論への影響、ユーザ要求が曖昧である場合の推論の影響など。
- 計画および自己改善については様々な手法が提案されているので、実応用上でどれを採用するかについては悩ましいところ。
6. 次に読むべき論文は?
- Yao+’23 - ReAct: Synergizing Reasoning and Acting in Language Models
- Xu+’23 - ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
- Zhou+’24 - Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
- Ma+’23 - LASER: LLM Agent with State-Space Exploration for Web Navigation
おわりに
本記事では、LLM Compiler について解説しました。 今後も LLM エージェントやマルチエージェントシステム等についての技術発信をしていこうと思うので、ぜひよろしくお願いします。
LLM を活用したプロダクトの開発に興味をお持ちの方は、ぜひご連絡ください! 下記のリンクからカジュアル面談の応募ができます。
