こんにちは。Algomatic LLM STUDIO 機械学習エンジニアの宮脇です(@catshun_)。
本記事では LLM を用いたエージェントシステムの基盤となる「計画機能」について、LLM による観察を伴わない推論計画を行う ReWOO (Xu+'23) について紹介します。
Xu+'23 - ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models arxiv.org
また ReWOO を LangGraph で実装した例についても以下の記事で解説していますので同時に参照ください。
おことわり
- 本記事では説明のため論文中の事例を翻訳等によって改変している箇所があります。詳細については必ず論文を参照してください。
- 本記事は LLM 等の背景知識を持つ方向けの記事になります。
- 記事の誤り等がありましたらご指摘いただけますと幸いです。
1. 本研究の概要
- LLM の構成性を仮定した新しい計画手法 Reasoning WithOut Observation (ReWOO) を提案した。LLM による観察をツール実行から切り離すことで、特に HotpotQA において、5 倍のトークン効率 と 4 %の正解率向上を示した。

2. 先行研究と比べてどこがすごい?
- ReAct (Yao+'23, ICLR) のようなタスク実行と思考のフェーズを繰り返す推論手法 (interleaved 型推論) の手法と比較して、はじめに立案した計画に基づいて推論を進める手法 (decomposed-first 型推論) を採用することで同等以上の性能(問題に対する正解率)かつ高効率(低いトークン消費量)を示す。
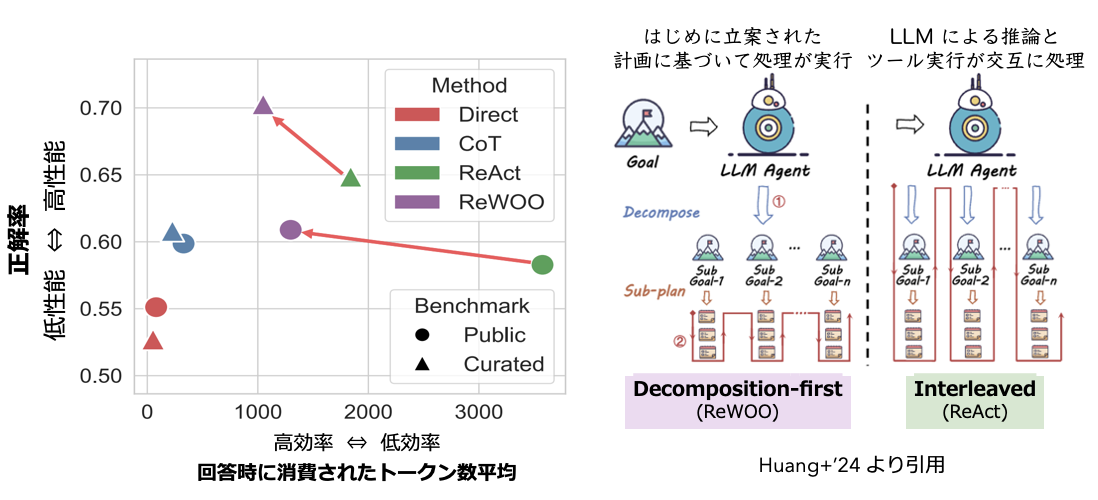
- トークン効率が良いため、ユーザによるアクセス頻度の高いシステムへのエージェント統合や、曖昧性を含む複雑なタスク(すなわち繰り返しの内省と自己改善を含む推論)においてスケールの観点からも効果的であると言える。
3. 技術や手法のキモはどこ?
アーキテクチャ
ReWOO は Planner, Worker, Solver の 3 つのモジュールで構成される。
Planner
LLM が入力文を実行可能なタスク系列として分解する(計画を立案する)。
タスクの具体的な構成要素は (Plan, #E) で記述され、Plan は現在のタスクの説明文を、#Es は時刻 s の行動(=ツール実行)によって取得した実行結果を格納する変数を示す。
変数 #Es は後段タスクの入力値として再利用可能であり、これによって多段階の複雑なタスクを事前に計画として構成することができる。
Worker
ツール実行によって外部の知識を検索し、問題解決の手がかりとなる記述を提供する。
Planner によって計画(タスク系列)が作成されると Worker が指定された入力で呼び出され、実行結果の記述が #Es に格納される。
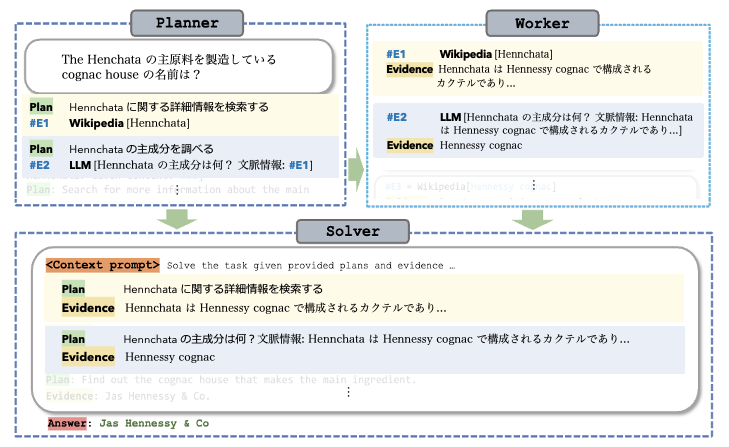
#E1 という変数が含まれており時刻=1 の行動結果が #E1 に格納される。
Solver
Planner による計画(タスク系列)と Worker によるツールの実行結果を統合して、最初のタスクに対する最終的な解答を生成する。
-- ReWOO におけるトークン消費の効率性はどれくらいか?
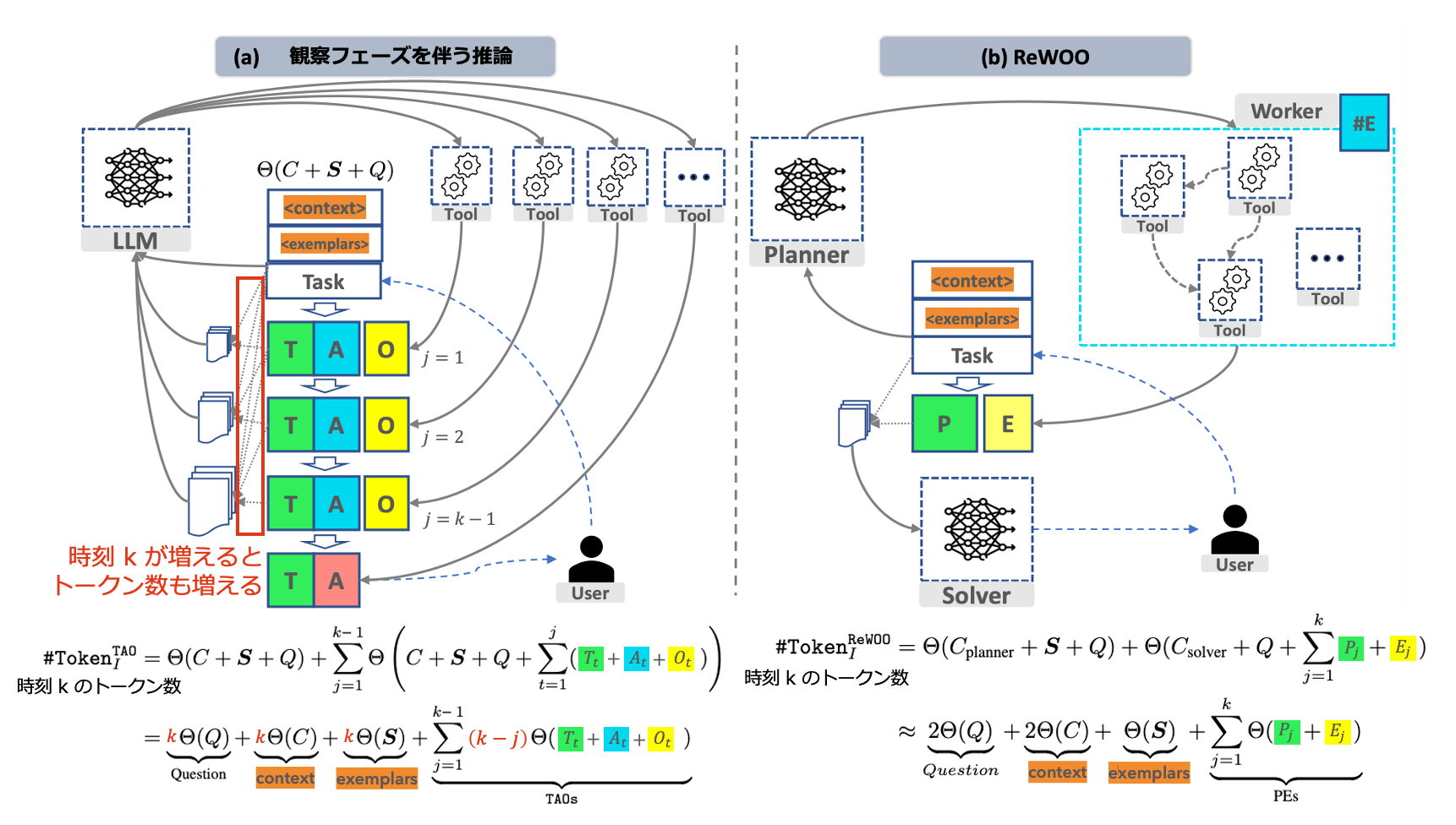
下の図 2 は (a) ReAct のような観察フェーズを伴う推論と (b) ReWOO のそれぞれについて、反復的な実行概要と消費されるトークン数合計を示す。 (a) 観察フェーズを伴う推論は、各ステップで質問 (Q), 文脈 (C), 例題 (S) が入力され、また各ステップで前回の思考 (T), 実行結果 (A), 観察 (O) の結果も入力される。 そのためステップ数 k に伴い (Q,C,S) では線形に、(T,A,O) では二次関数的にトークン数が増加する。
一方 ReWOO では、計画とツール実行の段階が分離されている。そのためステップ数 k に伴うトークン数の増加分は思考にあたる計画 (P) と実行結果 (E) のみとなる。
Parameter Efficiency by Specialization
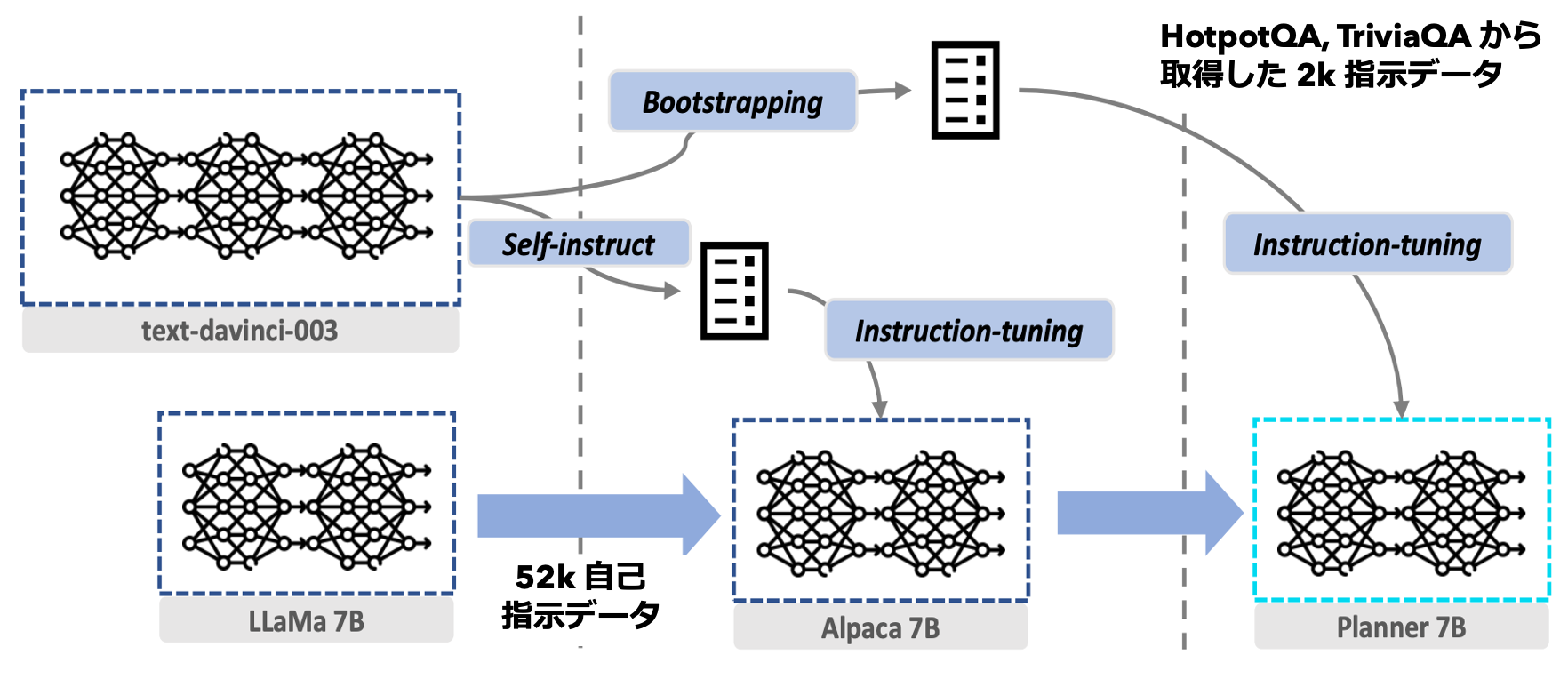
ReWOO では計画時にツール実行の結果を含めず計画段階においてツール呼び出しを伴わない。そのため計画能力をさらに加速させる Planner を学習可能である。本研究では GPT-3.5 から生成された指示データで LLaMA 7B を LoRA による微調整を行うことで、汎用的な計画能力を保持する Planner が獲得可能であるか調査している。
4. どうやって有効だと検証した?
評価設定
評価セットは以下の通りである。各タスクごとに利用可能なツールを事前に準備する。また {HotpotQA, TriviaQA, GSM8K} ではそれぞれ {6, 1, 1}-shot として例題を用意する。{PhysicsQuestions, SportsU., StrategyQA} では 1-shot の例題を採用するが、対象となる評価タスクとは異なる評価セットから 1 つの例題を用いる。例題の推論過程数は 2~3 である。また解答生成器には GPT-3.5 を用いる。
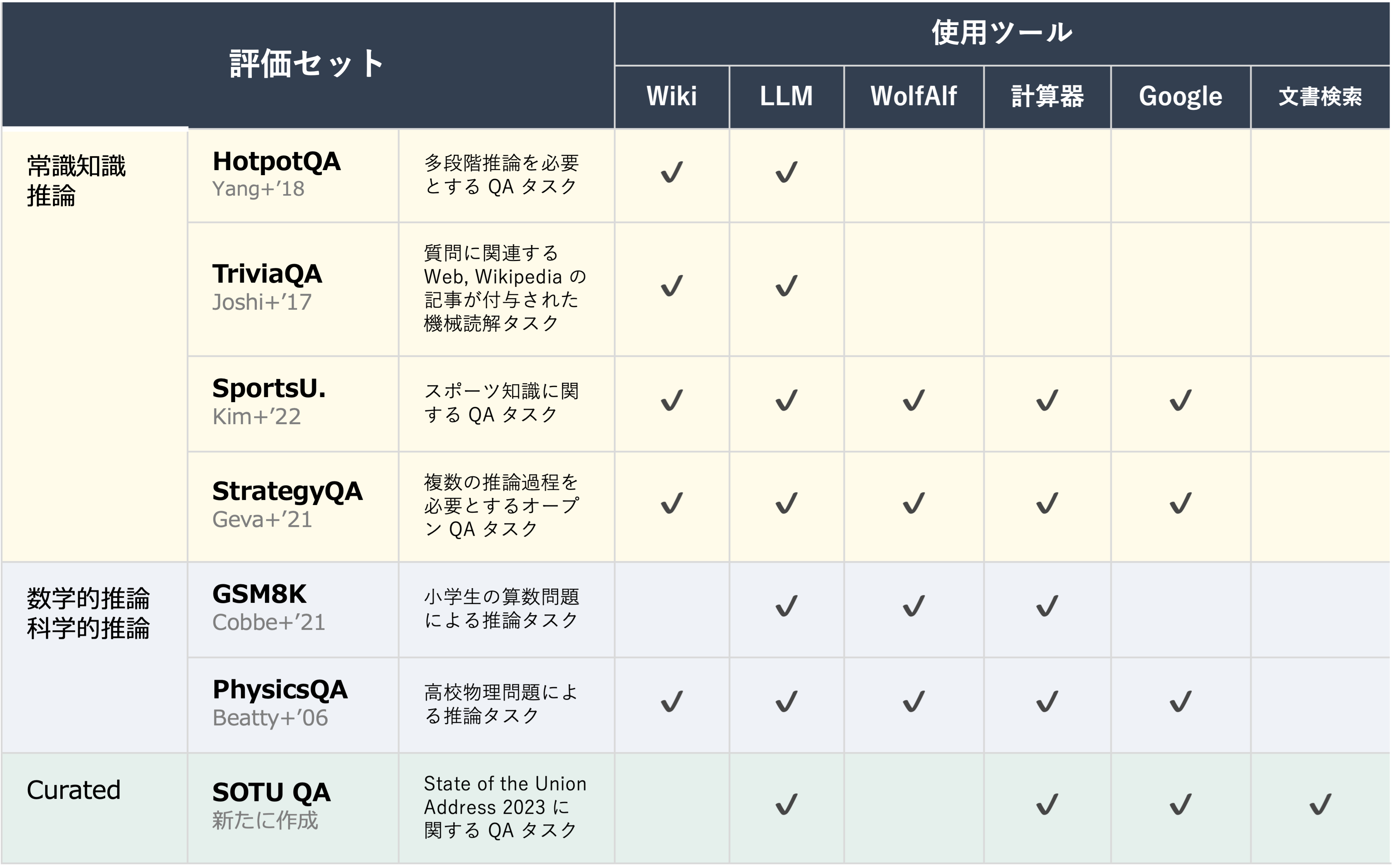
評価基準には完全一致 (EM) および文字重複に基づく F1 スコア(正解とのトークン重複文字数が多いほど値が大きくなる)のほか、"CA." と "California" のような意味的に同一であるものを正解と判定するために GPT-4 を用いた正解率 (Acc) を採用する。
比較対象とするベースライン
- Direct Prompt: LLM に直接タスク指示と質問を入力する標準的なゼロショット手法。
- Chainof-Thought (Wei+'22, Kojima+'23): Direct Prompt に加えて LLM に例題と "think step by step" を入力する。
- ReAct (Yao+'23): 思考・行動・観測を 1 つのサイクルとする推論手法。推論を中断して行動を実行し、行動結果に基づいて次にやるべきことを LLM が決定していく。
先行研究との正答率比較
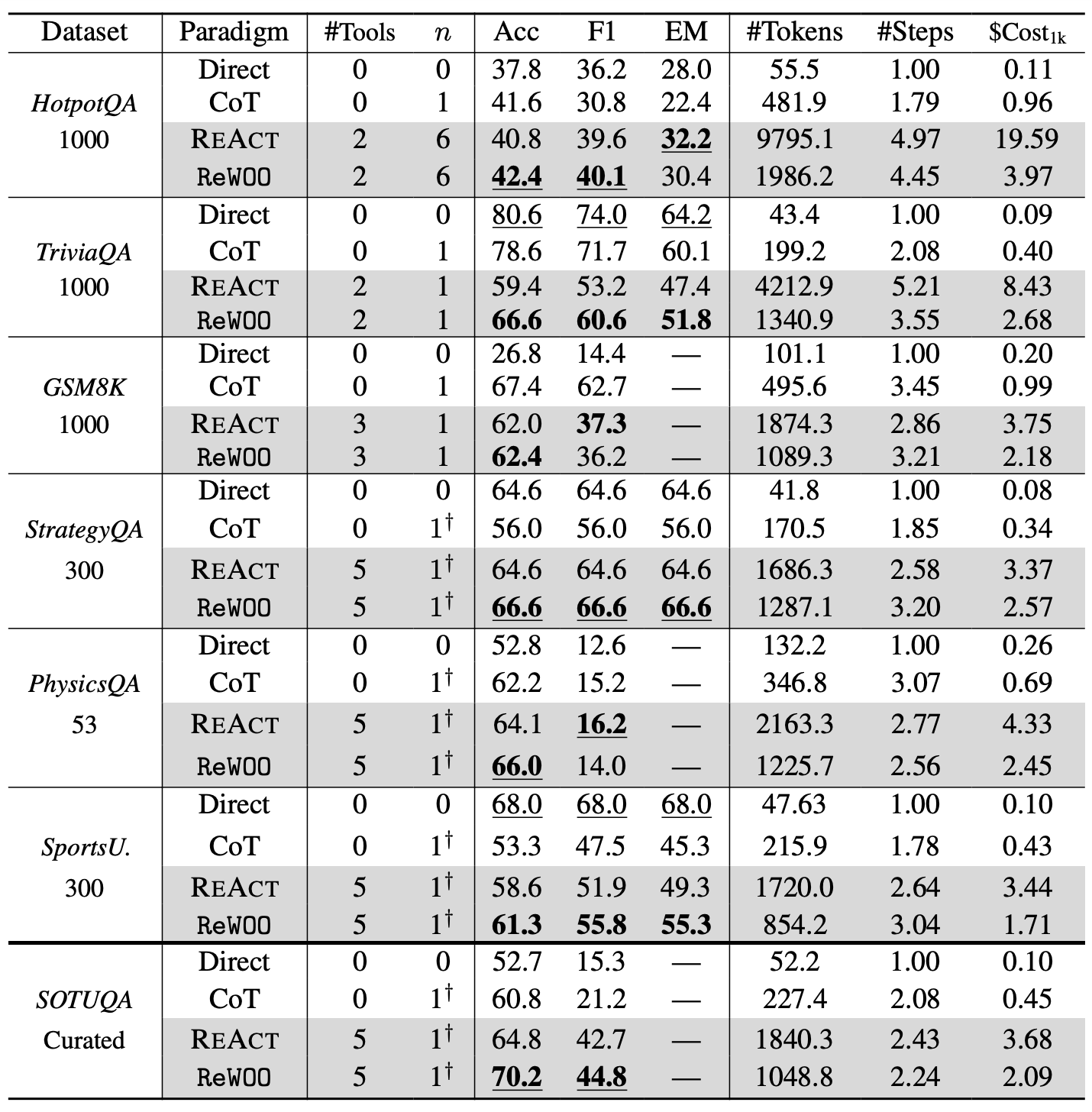
表 2 より全ての評価セットにおいて ReWOO の正解率が ReAct を凌駕した。加えてトークン消費量の 6 評価セットに対する平均消費数は ReAct に対して 64% 抑制し 高いトークン効率を示した。一方、TriviaQA, SportsU. のような読解や特定の一般知識を問うタスクでは、Direct Prompting の方が正答率が高い。ツール実行を伴うタスクの複雑化が正答率に悪い影響を与える可能性 を示唆した。

HotpotQA における ReAct, ReWOO のエラー分析の結果を上の表 A.2 に示す。ReWOO では推論誤りが ReAct 76 件に比べ 51 件と少ないことから 計画立案をはじめに行うトップダウン式の推論 が対象タスクの道の踏み外しの抑制を実現すると考えられる。
-- ツール利用を伴うタスクの複雑化は応答品質に悪い影響を与えるか?
以下の図 5 では HotpotQA を解く上で使用するツール数と正解率の関係を示す。
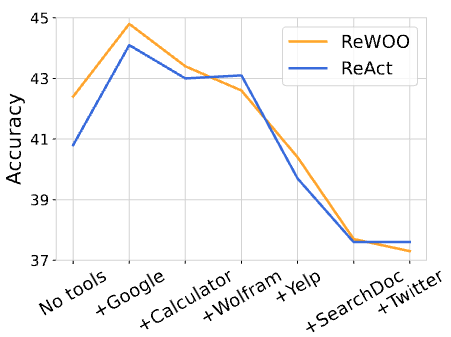
図 5 では 使用するツール数が多いほど正解率が低下する ことを示す。また追加の定性評価として、著者は 20 件の HotpotQA においてツール数を {2, 7} とした際の正解率を比較している。結果はツール数を 2 とした際の応答品質が高いことを示した。ツール数が 7 であるとき検索用途に Google ではなく Yelp(口コミサイトを参照するツール) 呼び出すなど、ツールの選択誤りが見られた。
-- ツールの実行結果が誤っていた際の正答率への影響は?
表 3 では HotpotQA において、ツールの実行結果が "No evidence found" となった場合に LLM に再度問いかけた際の性能変化を示す。
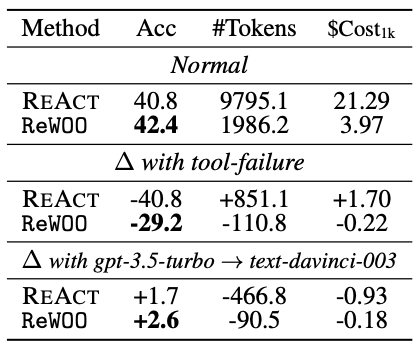
"Δ with tool-failure" を見ると、LLM に切り替えた際の ReWOO の正解率低下分は ReAct に対して少ない。これは実際のシナリオにおいても ReAct に対してより頑健なシステムを構築可能であることを示唆する。
Planner の微調整による正解率の変化
図 6 は ReWOO における Planner を GPT-3.5, Alpaca, Planner にそれぞれ置換した際の評価セットに対する正解率を示す。
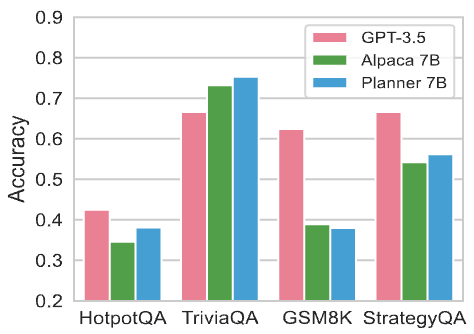
HotpotQA, TriviaQA における in-domain 評価タスクにおいて Planner は GPT-3.5 と同程度の正解率を示したことから、少なくとも in-domain の評価タスクにおいては ReWOO のパラメータ効率とスケーラビリティを大幅に改善する可能性を示唆する結果となった。
5. 議論はある?
知見
- 数学的推論や一部の知識推論において ReWOO が ReAct よりも高いトークン効率で同等以上の正解率を達成する。一方で読解や特定の一般知識を問うタスクにおいては Direct Prompting が有効な場合もある。
- ツール数が膨大になる場合にはツール選択のアルゴリズムを変更した方が望ましい場合がある。
- 経験則的に ReAct では few-shot に対象タスクとは異なる例題を用いると指定外のツールを選択する傾向があると思われたが、ReAct, ReWOO どちらも大幅な性能低下は見られなかった。Few-shot の例題は対象タスクと類似するものを選択すると良いという説のほか、counterfactual な例題を選択する Köksal+'23, Cuconasu+'24 のような参照能力向上の効果があるのか?
議論・改善の余地
- おそらく Decomposed Prompting (Khot+'23), Least-to-Most Prompting (Zhou+'23), Self-Ask (Press+'23), PS-Prompting (Wang+'23) のような LLM における構成的推論の成功を仮定していると思うが、計画を伴う推論がなぜ良いのかについての議論が丁寧にされていると嬉しい。
AlfWorld (Shridhar+'21) のような入力文に不要な情報が多く含まれる場合は計画自体が困難であり、経験による内省や自己改善が必要となる (Zhou+'24; Hirsch+'24)。

AlfWorld のタスク例。 動機実行であるため推論速度が遅い。非同期や並列化の処理 (Kim+'23) が必要。
- 関数並び替え (Gupta+'23](https://arxiv.org/abs/2211.11559) やプログラム記述 (Surís+'23; Subramanian+'23) などの、タスク系列としての計画の記述・実行方法については議論の余地がある。
実応用においてはツール数が膨大になった場合の代替案について検討する必要がある (Ahn+'22; Qiao+'23; Yuan+'24)。

B.2.. ツールの利用方法に関するプロンプト。 曖昧なクエリに対する LLM の構成性についての議論があっても良い。実務では問い返し (Hu+'24) や補完が計画立案の前段階として必要になる場合がありそう。
- ツールとしての Google 呼び出しは効果的であるが、一方でツールによる実行誤りや LLM の代替はまだまだ改善の余地がある。
6. 次に読むべき論文は?
- Kim+’23 - An LLM Compiler for Parallel Function Calling
- Yao+'23 - ReAct: Synergizing Reasoning and Acting in Language Models (ICLR)
- Gupta+'23 - Visual Programming: Compositional Visual Reasoning Without Training (CVPR)
- Zhu+'24 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
おわりに
本記事では decompose-first な計画立案を伴う ReWOO について解説しました。
以前 VisProg (Gupta+'23, CVPR) というインターリーブ型の構成的推論を採用した地理空間情報×LLM なアプリケーションの話を Geography&Language Study Group という研究会で発表しているので、こちらも参照していただけると嬉しいです。
