こんにちは。Algomatic LLM STUDIO 機械学習エンジニアの宮脇です(@catshun_)。
本記事では、エージェントシステムで基盤となる「計画」について、その先駆けとなる Plan-and-Solve Prompting (Wang+'23, ACL) について紹介します。
Wang+'23 - Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models (ACL) aclanthology.org
また Plan-and-Solve Prompting を LangGraph で実装した例についても以下の記事で解説していますので同時に参照ください。
おことわり
- 本記事では説明のため論文中の事例を翻訳等によって改変している箇所があります。詳細については必ず論文を参照してください。
- 本記事は LLM におけるプロンプト手法等の背景知識を持つ方向けの記事になります。
- 記事の誤り等がありましたらご指摘いただけますと幸いです。
- 急流な領域のため最近の言語モデルにおいては異なる結果を示す場合もあります。
1. 本研究の概要
- 新しいプロンプト Plan-and-Solve (PS) Prompting を提案した。数学的推論、常識推論、記号推論における性能評価において Zero-shot CoT を上回る正解率を示した。
- 具体的には Zero-shot CoT (Kojima+'22) の
Let's think step by step.を以下のプロンプトに置換する。
Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step. # まず問題を理解し、問題を解決するための計画を立ててください。 # そして、その計画を実行に移し、一歩一歩問題を解決してください。
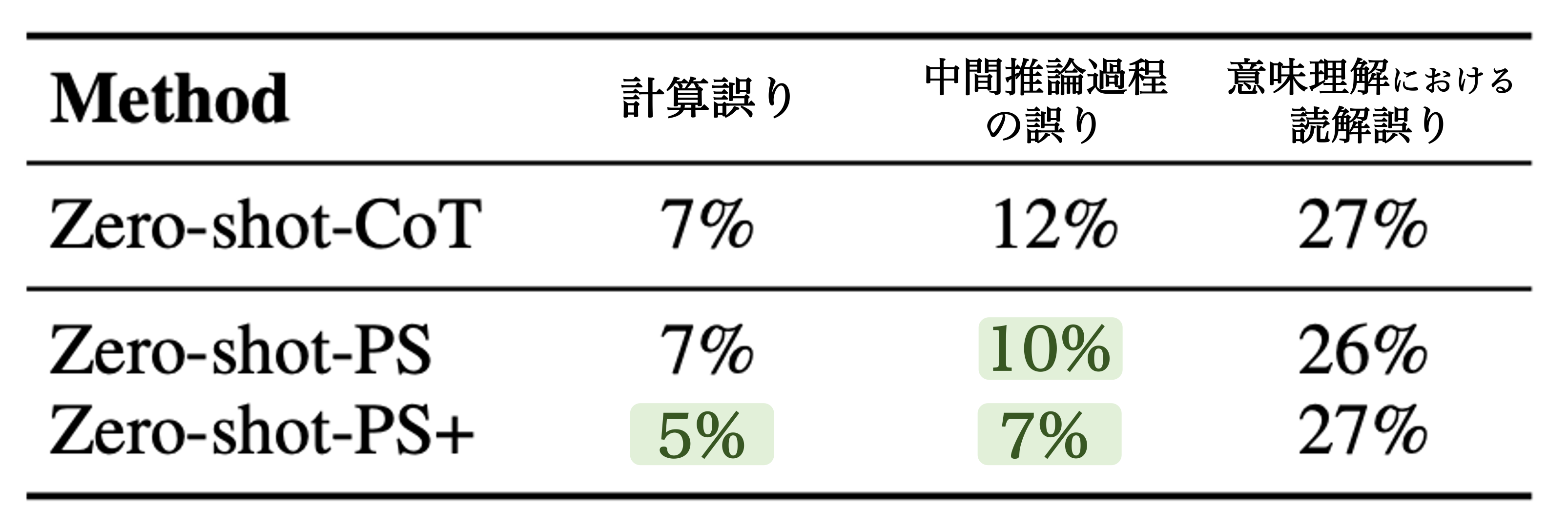
- PS Prompting における計算誤りや中間過程における推論誤り軽減するために、PS Prompting をベースとしてより詳細な指示文を追加した PS+ Prompting を提案した。
2. 先行研究と比べてどこがすごい?
- Zero-shot CoT (Kojima+'22) の
Let's think step-by-stepでは単純な指示文で複雑な推論を誘発させるため、推論が複雑化すると中間推論過程における推論誤り等が発生する。一方で Zero-shot PS Prompting, Zero-shot PS+ Prompting はより精緻な推論を促すプロンプトを LLM に与えるため、Zero-shot CoT における推論誤りをやや改善する。
- また PS Prompting は中間推論過程を誘発するための few-shot examples を必要としない。6 つの公開された評価データセットにおいて、PS Prompting は(容易に汎化可能であることが期待される)簡潔なプロンプト手法で Zero-shot CoT の推論性能を一貫して上回り、Few-shot CoT と同程度の性能を示した。
3. 技術や手法のキモはどこ?
Zero-shot PS Prompting では ①推論過程の生成 ②解答抽出 の 2 段階の方法で質問に対する回答を行う。以下 ① について説明する(② では ① で生成された推論過程に対して Therefore, the answer (arabic numerals) is の解答生成を促す文字列を連結したプロンプトを LLM に入力することで解答を抽出する。詳細については論文を参照されたい)。
-- どうやって中間推論過程を誘発させるか?
PS Prompting
LLM に ①計画立案 (Plan) と ②計画実行 (Solve) の逐次実行を促す PS Prompting を提案する。
Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step. # まず問題を理解し、問題を解決するための計画を立ててください。 # そして、その計画を実行に移し、一歩一歩問題を解決してください。
以下のような複雑な推論過程を伴う問題を例に挙げる(例題は解説のため日本語に翻訳した)。

上記の問題に対する Zero-shot CoT, PS Prompting の推論結果を下図に示す。Zero-shot CoT は中間推論過程をボトムアップに生成する一方で、PS Prompting では初めに計画を伴うことでトップダウンに推論過程を生成する。

-- PS Prompting は出力結果に対してどれくらい計画立案を実現させるか?
これについては 4.2節 Analysis で述べられている。実際に 100 件の推論結果 (対象は恐らく GSM8K) を無作為に抽出して調査したところ 90 件の予測結果に対して計画立案の中間推論過程が含まれていたそう。
- 敢えてツッコミを入れておくと、実際のシナリオでは曖昧な入力文が想定されるため 90% の計画立案が他のタスクで担保されるかについては明らかでない。
- また計画に対する構成性の評価についても明らかでない。曖昧性を含む入力文から応答生成が可能である LLM を用いることで解答生成が可能であるが、プログラム実行を伴う推論において PS Prompting が有効であるかどうかについては別途議論が必要になる。
PS+ Prompting
PS Prompting をベースのプロンプトとして、より高品質な推論過程の生成を LLM に促すための PS+ Prompting を提案する。具体的には extract relevant variables and their corresponding numerals や pay attention to calculation and common sense という節を追加することで、LLM が入力文中の関連情報を抽出し、正しい計算や常識的推論を行うよう促す ことで、推論誤りの軽減を期待する。
Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer. # まず問題を理解し、関連する変数とそれに対応する数字を抽出し、計画を立ててください。 # そして、その計画を実行し、中間結果を計算し(計算と常識に注意してください)、段階的に問題を解き、答えを示してください。
-- LLM が入力文中の関連情報を見落とすと後続する推論過程に悪影響を及ぼすか?
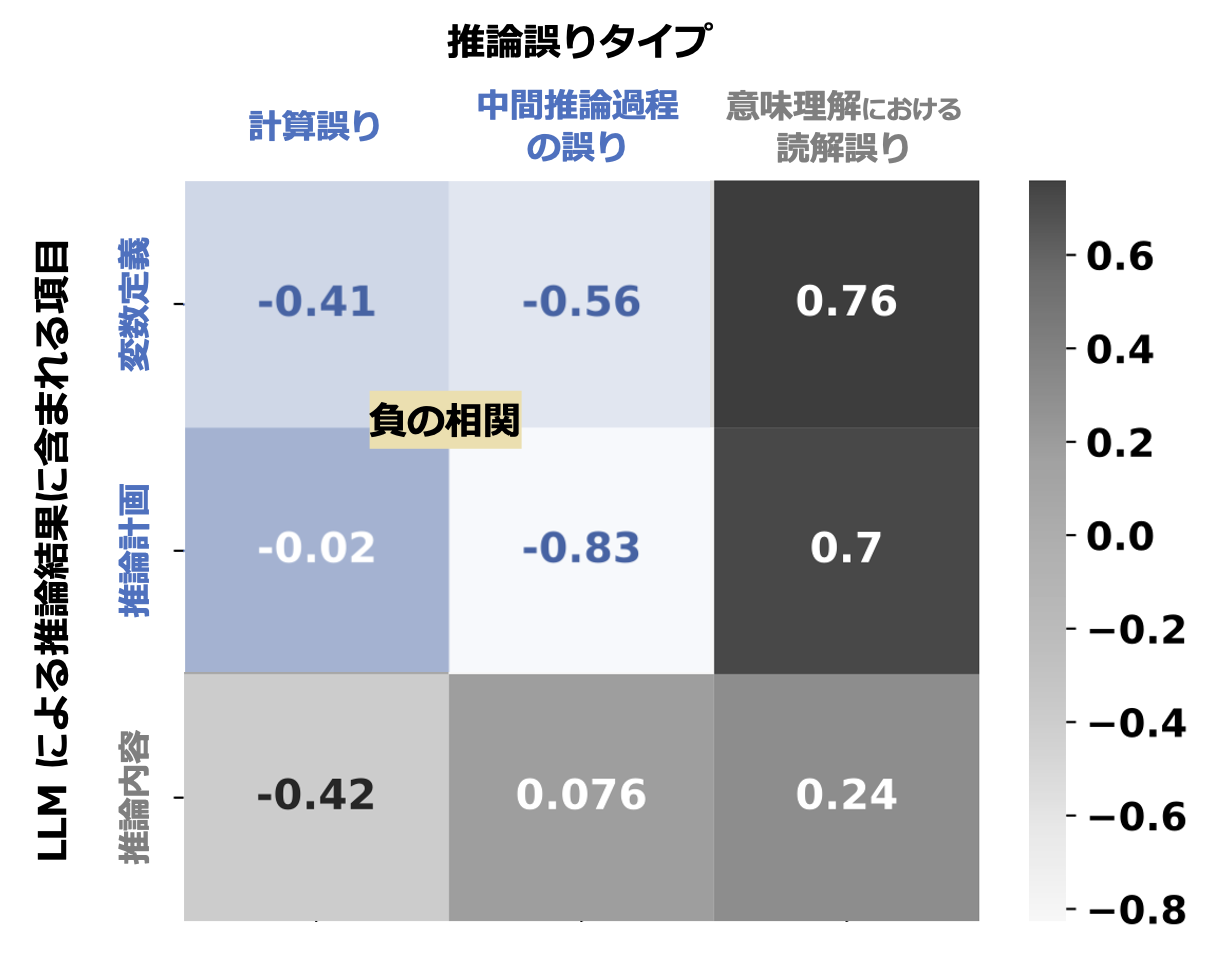
PS+ Prompting では LLM に関連情報を正しく抽出させる指示(extract relevant variables ~)が含まれる。図5 ではこれら指示文の有効性を調査するために、(x) 推論誤りが発生した際の誤りタイプと (y) 推論結果に含まれている関連情報(変数、計画、推論内容)をそれぞれカウントすることで相関を算出している。推論結果に変数の定義や推論計画が含まれると、計算誤りや中間推論過程の誤りが軽減される(負の相関を示す)ことが分かる。
4. どうやって有効だと検証した?
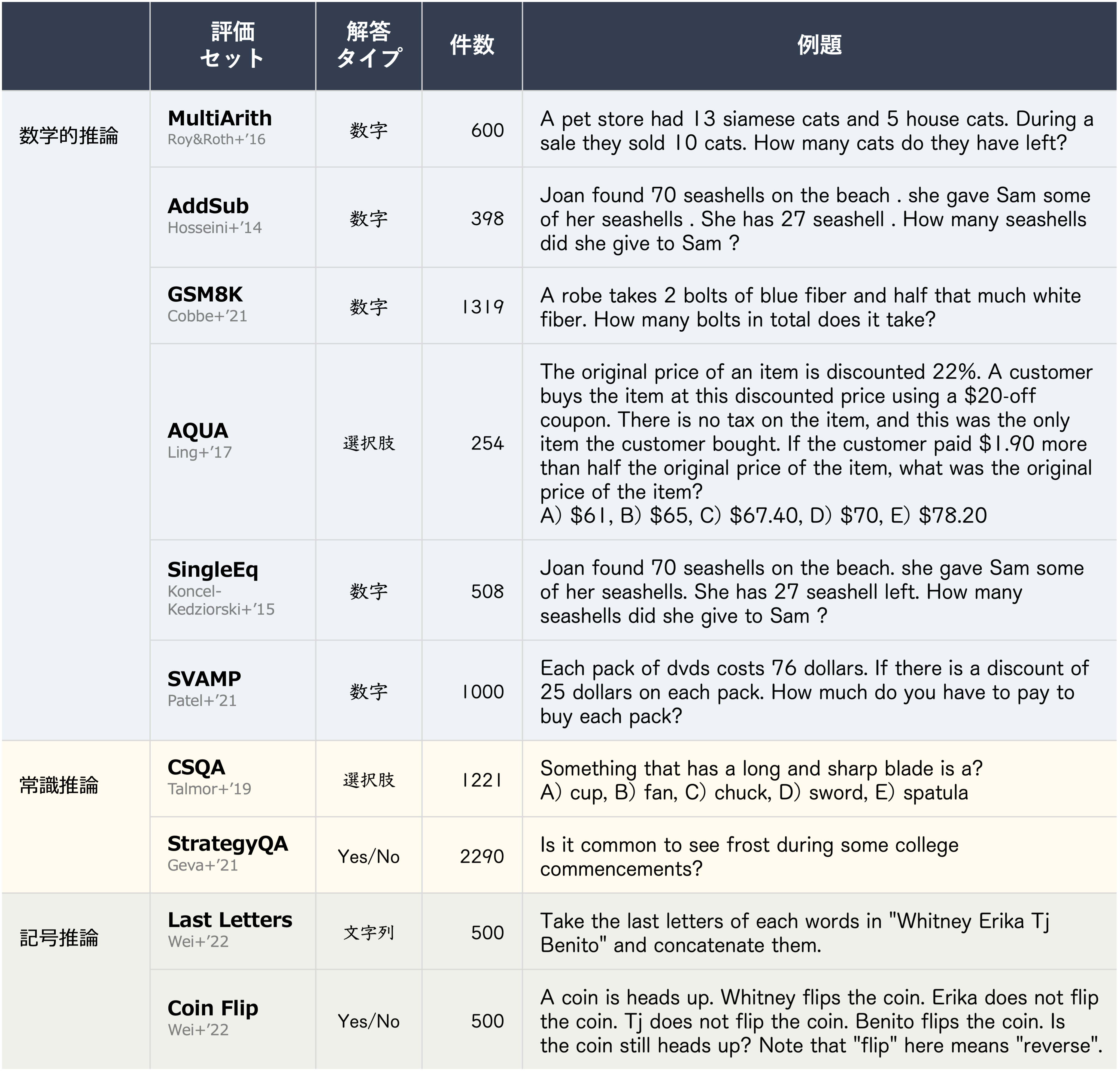
評価データセット
一般的に使用される数学的推論、常識推論、記号推論の評価セットを使用して性能を評価した。
先行研究との比較
数学的推論
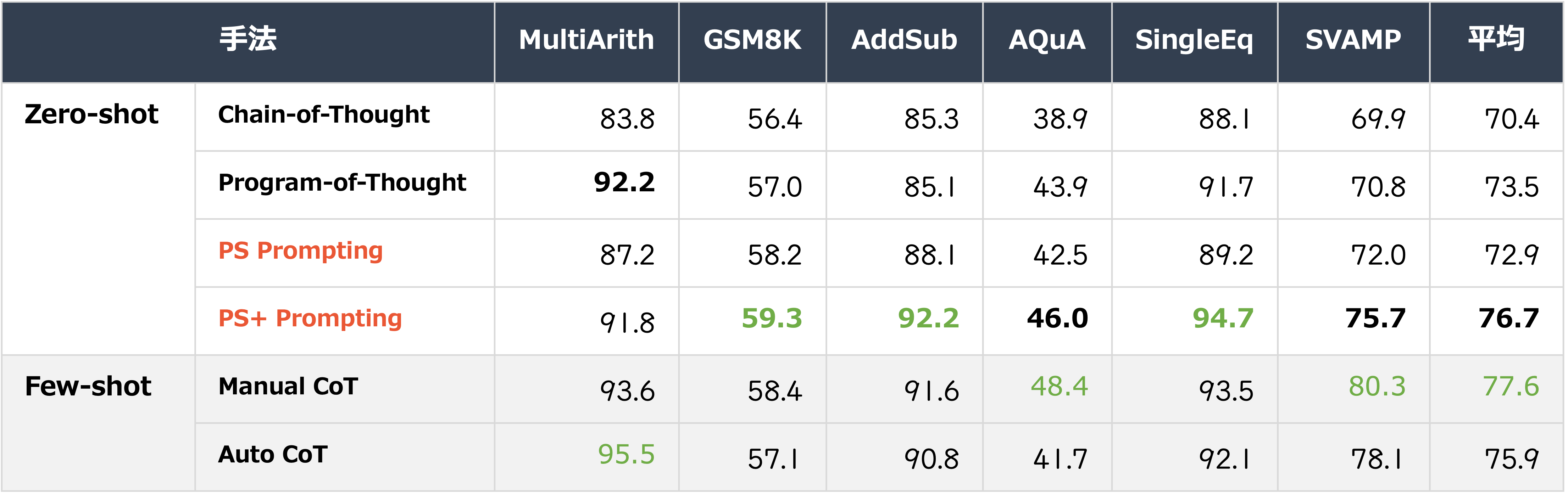
上の 表2. は数学的推論における先行研究との正解率を比較した結果を示す。Zero-shot の設定において PS+ Prompting が Chain-of-Thought (Kojima+'22), Program-of-Thought (Chen+'22) に対して優れた性能を示した。また一部の評価セットで Few-shot CoT と同等以上の正解率を示した。
それぞれの先行研究の概要については以下に述べる。



常識推論
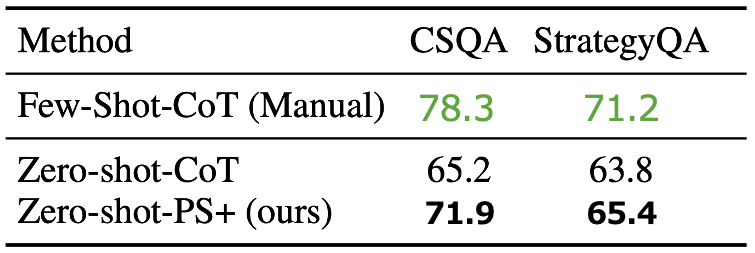
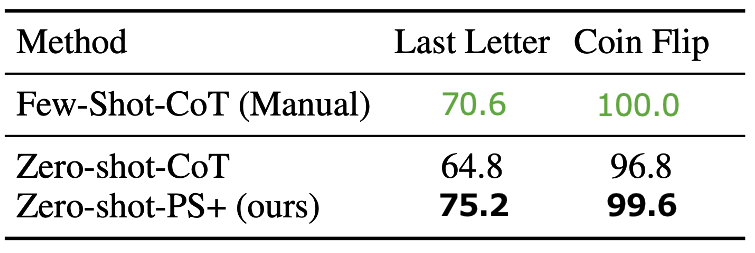
記号推論
Self-Consistency を用いた評価
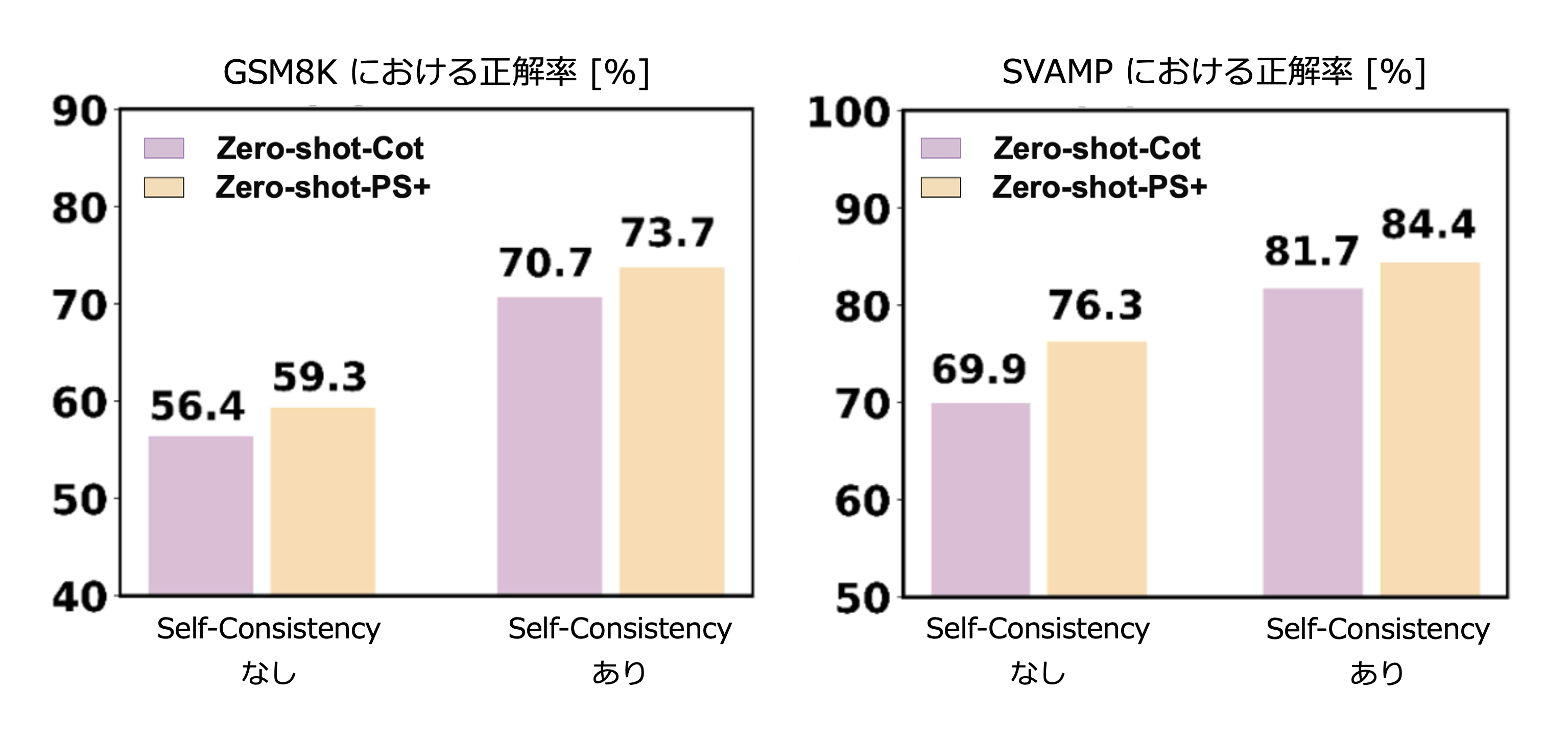
複数回にわたって LLM に解答を生成した上で、最も一貫した解答を最終的な予測結果として採用する Self-Consistency を用いると、Zero-shot CoT (Kojima+'22) と同様に正解率が一貫して向上する。
Self-Consistency の概要については以下に述べる。

5. 議論はある?
知見
- 先行研究に対する差分が単純であるものの、PS Prompting の計画立案における筋の良さや高い汎化性を示した。
- PS+ Prompting は Zero-shot CoT に対して一貫して高い正解率を示しており、また一部の評価セットで Few-shot CoT と同等以上の正解率を示した。
- PS+ Prompting におけるキモは中間推論に対して特定性を高める指示にあり、この指示は具体的な説明だと良い。
議論・改善の余地
- PoT との比較実験の結果を示したが、計画の媒体(自然言語, プログラム (Chen+'23; Gao+'23), PDDL (Dagan+'23), etc..)や推論方法(Tree-of-Thought (Yao+'23), Graph-of-Thought (Besta+'23), etc..)などが後続する研究で提案されている。
- Skelton-of-Thought (Ning+'24) のような並列実行による高速化も考えられる。
- 生成された計画や推論過程における評価。例えば構成性に対する Compositional Gap (Press+'23) などはあるか、などの議論があっても良い。
- 曖昧なクエリに対してどれくらい生成品質が担保されるのかについて議論があっても良い (Zhang+'24)。
- 実際に使ってみると、内省 (Shinn+'23; Madaan+’23) や自己改善 (Gou+'23; Shridhar+'23; Lu+'24) を含まないと難しい場合も多々ある。
6. 次に読むべき論文は?
- Huang+’24 - Understanding the planning of LLM agents: A survey
- Kojima+'22 - Large Language Models are Zero-Shot Reasoners (NeurIPS)
- Chen+'23 - Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks (TMLR)
Ning+'24 - Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation (ICLR)
- Microsoft guidanceでPlan-and-Solveプロンプトを実装してみた|mah_lab / 西見 公宏
- 宮脇+'23 - Prompt Engineering サーベイ
おわりに
本記事では、Plan-and-Solve Prompting について解説しました。 今後も LLM エージェントやマルチエージェントシステム等についての技術発信をしていこうと思うので、ぜひよろしくお願いします。
LLM を活用したプロダクトの開発に興味をお持ちの方は、ぜひご連絡ください! 下記のリンクからカジュアル面談の応募ができます。
