こんにちは、Algomatic LLM STUDIO インターンのなべ(@_h0jicha)です。
前回の記事では、LLM の日本語性能を評価するための様々なベンチマークを紹介しました。
しかし、こうしたベンチマークには以下のような課題が存在します。
- ベンチマークの導入に負担がかかってしまうため、もっと 気軽に評価したい
- 既存のベンチマークによる評価が難しく独自実装が必要なとき、あらかじめ基本的な機能が搭載されている評価ツールを利用したい
- LLM の評価とともに、LLM を使用する際の プロンプトの評価も同時に行いたい
そこで本記事では、LLM の出力品質を評価する際に活用できる promptfoo について紹介します。
目次
promptfoo とは?
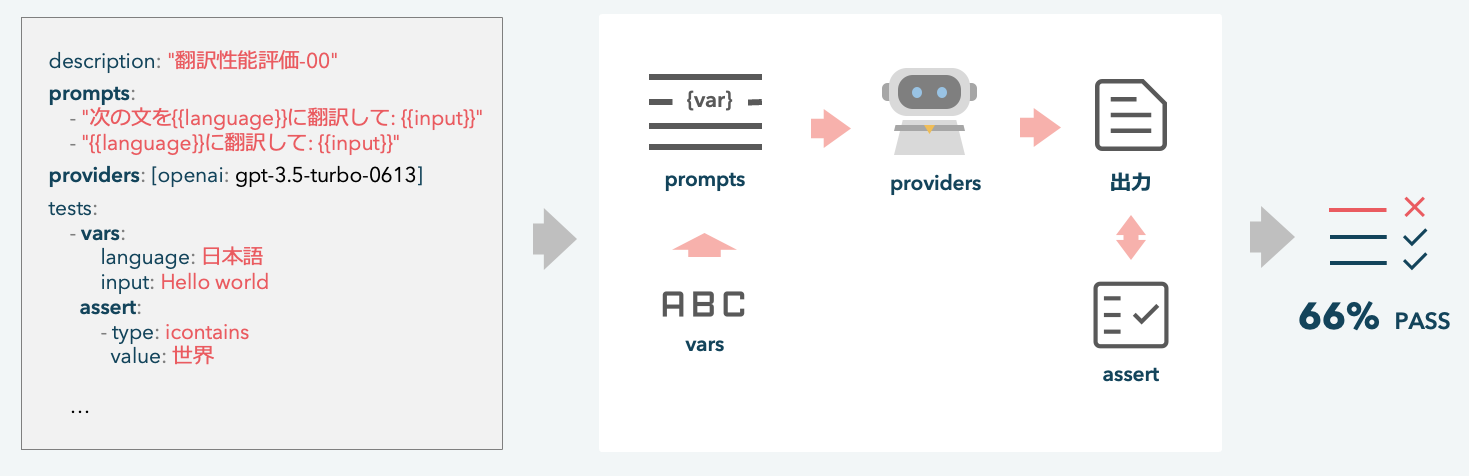
promptfoo は LLM が出力するテキストの品質を評価するツール です。
ソフトウェアのテスト設計に影響を受けており、LLM の出力に対してテスト項目を指定する(アサーション)ことで、LLM の応答品質を定量的に評価します。
実際の評価結果は以下のように表示されます。
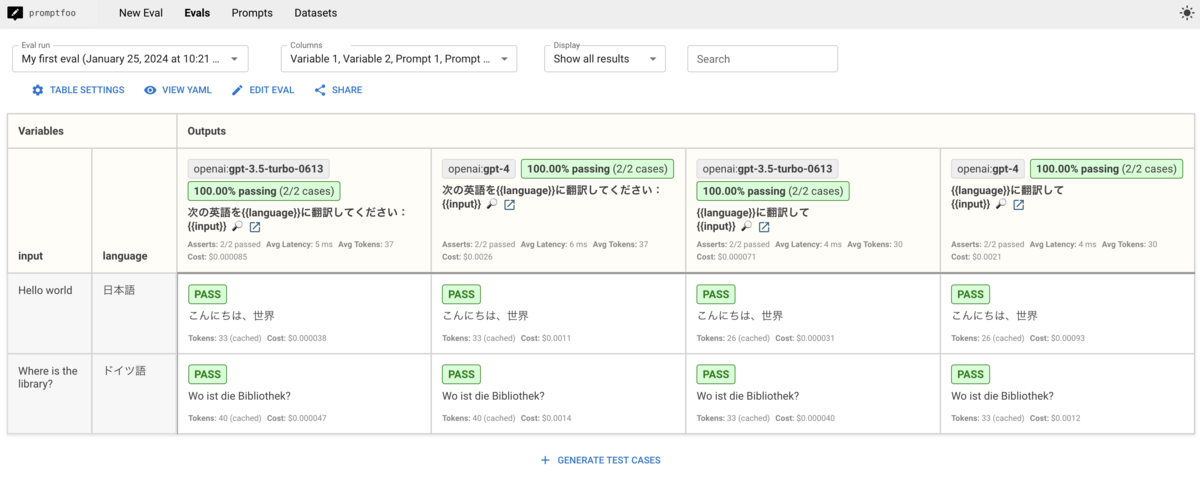
評価結果は表形式で表現されており、プロンプトテンプレートに代入する変数である Variables と変数を代入したプロンプトを入力した際の出力結果 Outputs に分けられています。
promptfoo では事前にテスト項目を設定することで評価を行います。テストの通過状況は、LLM の各出力にある PASS の記載や、LLM とプロンプトの各組にある 100.00% passing という記載から分かります。
promptfoo にはアサーションのプリセットとして様々なものが用意されているため、promptfoo を使用しない場合と比べて 高速かつ容易な実験準備 が可能になっています。
導入方法
それでは、promptfoo を実際に導入してみましょう。
環境構築
まず、promptfoo の実験環境を構築します。以下のコマンドを実行します(今回は npx を使用します)。
$ npx promptfoo@latest init hello-promptfoo $ cd hello-promptfoo
これを実行すると、カレントディレクトリ配下に hello-promptfoo ディレクトリが作成され、その配下に promptfooconfig.yaml が作成されます。
この promptfooconfig.yaml に、実験設定を記述していきます。
実験設定
実験の設定例として、上に示した簡単な翻訳タスクを評価するための設定を記述します。
# 実験の説明 description: 'My first eval' # 実験で使用するプロンプト prompts: - "次の英語を{{language}}に翻訳してください:{{input}}" - "{{language}}に翻訳して\n{{input}}" # 実験で使用する評価対象LLM (LLM APIs) providers: [openai:gpt-3.5-turbo-0613, openai:gpt-4] # テストケース設定 tests: - vars: # プロンプトに代入する変数の設定 language: 日本語 input: Hello world assert: # 応答結果に対して適用するアサーションの設定 - type: icontains value: 世界 - vars: language: ドイツ語 input: Where is the library? assert: - type: icontains value: bibliothek
重要な内容は以下の通りです。
promptsにプロンプトを記載する。プロンプト内で変数を使用するためには、{{language}}のように{{}}で変数名を囲む。providersに評価対象 LLM を記載するtestsにテストケースを記載する。各要素は、vars,assertメンバをもつ。varsには、プロンプト内の変数に代入する値を記載するassertには、適用したいアサーションの設定を記載する(詳細は後述)
以上で実験準備が完了しました!
promptfooconfig.yaml に 設定を宣言的に記載していくだけ で基本的な実験準備が完了する様子を体感していただけたでしょうか。
評価実行
実験を開始するために、以下のコマンドを実行します。
$ npx promptfoo@latest eval
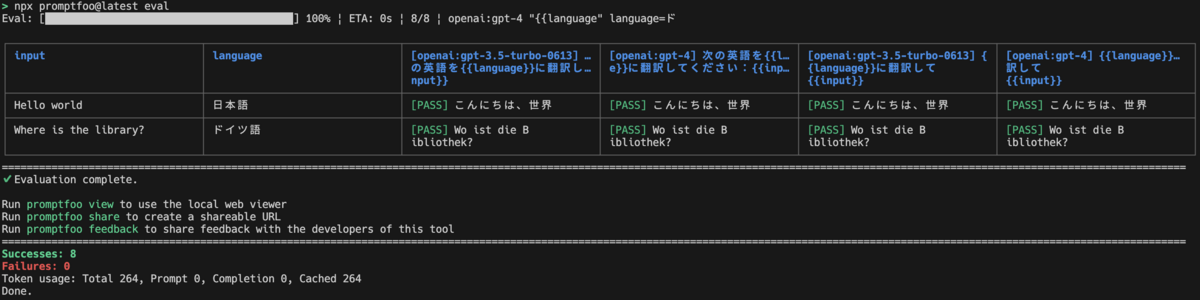
プログレスバーを通して実験の進捗を確認することができ、実験が完了すると以下のように CLI 上で実験結果が表示されます。
さらに実験結果を GUI 上で確認したい場合は、以下のコマンドを実行します。
# 評価結果を確認するための webui server を作成 $ npx promptfoo@latest view -y
実行が完了すると、ブラウザに以下のようなタブが開かれます。
また、評価結果を他の人と共有したい場合は、以下のコマンドで共有リンクを生成することができます。
# 評価結果を共有するための UUID-based URL を表示 (TTL 2 weeks) $ npx promptfoo@latest share
アサーションについて
このように簡単に評価を実施できる promptfoo ですが、前述の通り、様々なアサーションのプリセットを活用することでさらに多様な評価基準を使用することができます。
上の評価では assert.type の値として icontains を指定しました。
これは部分文字列一致を判定する評価基準で、この assert.type を アサーションタイプ と呼びます。
promptfoo をより効果的に活用するために、どのようなアサーションタイプが提供されているのか確認していきましょう。
アサーションタイプの概要
実際に各バージョンで提供されているアサーションタイプは ドキュメント や 実装中の定義 で確認することができます。ただし一部内容が未実装のものがあり、本記事を読まれている時点で実装されているかどうかは runAssertion から確認することができます。
アサーションタイプは大きく 決定的評価指標(Deterministic eval metrics) と モデルグレード評価指標(Model-graded eval metrics) に分けられます。
以下では、この分類に基づいてアサーションタイプを見ていきましょう。
なお、すべてのアサーションタイプは 接頭辞として not- を付与すると否定条件 となります(例: not-icontains )。
決定的評価指標(Deterministic eval metrics)
決定的評価指標では、LLM の出力テキストに対してルールベースな処理を適用します。
ここでは、適用する処理によって 文字列一致系、JSON 形式系、閾値系、自作系 に分けてまとめます。
なお、名称部分のリンクから詳細を確認することができます。
文字列一致系
equals:完全一致contains:部分文字列一致contains-all:部分文字列一致(複数文字列が指定されたときに AND を適用)contains-any:部分文字列一致(複数文字列が指定されたときに OR を適用)starts-with:始端文字列一致regex:正規表現マッチング
contains 系のタイプは、接頭辞として i を付与すると大文字・小文字の差異を無視 して一致判定を行います。(例: icontainsは大文字・小文字の差異を無視した部分文字列一致判定となります。 )
JSON 形式系
is-json:JSON形式かどうかを判定contains-json:部分文字列としてJSON形式を含むかどうかを判定is-valid-openai-function-call:providersで定義されたfunctionsの形式かどうかを判定is-valid-openai-tools-call:providersで定義されたtoolsの形式かどうかを判定
JSON 形式判定系のタイプは、アサーション設定の value メンバに JSON schema を指定して内容を検証 することも可能です。
閾値系
閾値系のアサーションタイプは、アサーション設定に threshold メンバを記載することで、その値との比較に基づいてテストの通過が判定されます。
cost:推論費用がthresholdドル 未満か (現在は OpenAI GPT, Custom Providers のみ可能)latency:推論時間がthresholdms 未満かlevenshtein:レーベンシュタイン距離 の値がthreshold未満かperplexity: Perplexity の値がthreshold未満か(現在は OpenAI GPT, Azure GPT のみ可能)rouge-n: ROUGE-N の値がthresholdより大きいか
promptfoo には、推論コストを削減するために キャッシュ の機能があります。
latency を使用する際には、この機能を disabled にしておく必要があります。
また、rouge-n を使用する際の参照テキストの指定方法についてはドキュメントに詳細がないですが、実装箇所 を見ると value メンバに値を指定すれば良いことがわかります。
自作系
アサーションの内容を独自に実装することもできます。
python:自作 python 関数による評価javascript:自作 javascript 関数による評価webhook:LLM の出力テキストを webhook URL に POST して評価結果を受け取る
スクリプトを実験設定ファイルに直接書きたくない場合は、異なるスクリプトファイルを参照することもできます(pythonの例)。
モデルグレード評価指標(Model-graded eval metrics)
モデルグレード評価指標では、評価対象 LLM とは異なる機械学習モデルを評価に活用します。
ここでは、用意するモデルの種類ごとに 埋め込み・分類、LLM-as-a-judge、RAG 評価 に分けて見ていきます。
埋め込み・分類
similar:valueに指定したテキストに対する類似度がthreshold未満か(デフォルトでは類似度を求めるために OpenAItext-embedding-ada-002が使用されます)classifier:providerに指定したモデルによるテキスト分類
例えば、classifier で facebook/roberta-hate-speech-dynabench-r4-target を使用して有害なテキストを判定するためには、アサーション設定を以下のようにします。
assert: - type: classifier provider: huggingface:text-classification:facebook/roberta-hate-speech-dynabench-r4-target # スコアが 0.5 より大きい場合、LLMの出力テキストは有害でないとする value: nothate threshold: 0.5
LLM-as-a-judge 系
評価対象 LLM の出力テキストを 審査員 LLM によって評価する LLM-as-a-judge を実施することもできます。
llm-rubric:valueに指定された要求を満たすかどうかmodel-graded-closedqa:valueに指定された要求を満たすかどうか(llm-rubricと類似)answer-relevance:元のプロンプト(クエリ)と関連しているかどうかfactuality:valueに指定した内容(事実)に反していないかどうか
RAG 系
他にも、RAG の評価に活用することができるものも存在します(参考)。
context-faithfulness:文脈を汲んだ応答になっているかcontext-recall:文脈の中に ground truth が含まれるかcontext-relevance:文脈が元々のクエリと関連しているか
おわりに
本記事では LLM の評価ツールである promptfoo の概要とアサーションについて解説しました。
promptfoo には便利な機能が他にもたくさんあります。
- 重み付きアサーション:全体のスコアに対するアサーションの影響を調節
- チャット形式の評価:複数メッセージを文脈として保つ
- テストファイルの読み込み:csv ファイルからテストケースを読み込む
- アサーションテンプレート:アサーションを使いまわす(JSON Schema の
$ref) - タグ付けによるスコアリング:アサーションに独自タグを設定して、タグごとのスコアを確認
気になったら 公式ドキュメント や 実装 をご参照ください。
Algomatic LLM STUDIO では、LLM を活用した新たなプロダクトの開発に取り組んでいます。
今回の内容に少しでも興味を持たれた方や、LLM を活用したプロダクトの開発に興味をお持ちの方は、是非一度お話ししてみませんか?
下記のリンクから30秒でカジュアル面談が応募できますので、ぜひご連絡ください!
参考
- Ribeiro+'20 - Beyond Accuracy: Behavioral Testing of NLP Models with CheckList (ACL)
- Ribeiro+'22 - Adaptive Testing and Debugging of NLP Models (ACL)
- Lanham+'23 - Measuring Faithfulness in Chain-of-Thought Reasoning
- Ribeiro+'23 - Medium | Testing Language Models (and Prompts) Like We Test Software
- にょす氏+'24 - note | 推しのプロンプト実験管理ツール「promptfoo」を解説
- Gunosy テックブログ+'24 | LLMのプロンプトをCI/CDで評価する。promptfooを使って
筆者情報

*1:LangChain の PromptTemplate のように、変数を代入することができるものです。