こんにちは。NEO(x) の宮脇(@catshun_)です。
本記事はなつやすみ特集として、これから LLM プロダクトを開発する方に向けて『LLMプロダクト開発のことはじめ』をテーマとした 5分で読める コラムを紹介します🌻
ゆるく書くつもりなので、役に立つかどうかは分かりません 🙏
📝 目次はこちら
- 特集の導入、問いをデザインする
- LLM から良い回答をえるための第一歩
- プロンプトエンジニアリング👈
- LLMプロダクトの評価と検証
前回までのおさらい
前回までの記事では、以下について述べました。
- #01. 導入
- LLM の性能を信じてまず試す
- タスク構造を明らかにする
- #02. 良い応答を得るためのプロンプトの記述
- 望ましい出力を得るためにプロンプトに制約を設ける
- ベストプラクティスに従う
前回までの話は LLM プロダクト開発における初期段階で意識したい話 でしたが、本記事からは 初期~中期段階で意識したい LLM プロダクトの性能改善のための話 に着目したいと思います👏
前回の記事では、プロンプト作成については「あいまい性のない詳細な記述を心がけ、地道に改良を重ねること」が重要であると述べました。 本記事では、応答品質をさらに向上させるための プロンプトエンジニアリング について紹介します📈
なお本記事の内容は検証されていない経験則による話、最新のモデルでは解決されている話が含まれる場合があります。批判思考を持ちながらお読みください。
本記事は以下の資料を参考にしています。
より理解を深めたい方は、こちらも併せてご参照ください。
Few-shot プロンプト
我々(依頼者)が他者(被依頼者)にタスクを依頼する場合、まず依頼者がお手本を見せることでタスクの実行イメージを被依頼者に伝えることがありますが、few-shot プロンプトはこのお手本を数回見せる(few-shot)というタスク指示を与えます。
具体的には、タスクの (入力例, 出力例) のペアをデモンストレーションとしてプロンプトに含めます。このデモンストレーションの数に応じて zero-shot, one-shot, ..., k-shot といい、とくに k≧1 の場合に few-shot といいます(数が多い場合は many-shot と呼ばれたりもします)。

上図 (右) のように、一般的には few-shot の場合 zero-shot よりも性能が良くなることが知られており、OpenAI や Anthropic のプロンプトガイドにも few-shot プロンプトが勧められています。
Few-shot は事例の正しさよりバランスを意識する
正直なところわたしは few-shot プロンプトには苦手意識がありまして、プロンプト作成の初期段階では使用しない ようにしています。
というのも、プロンプトごとにデモンストレーションを作成する必要がある ことに加え、経験則ですが コンテキストが不十分な場合にデモンストレーションから回答してしまう ことがあります🫠
わかりやすく例えると、(実際に以下のような単純な例では発生しませんが)以下のようなプロンプトを使用した際、
system_prompt = """以下の例文を英語から日本語に翻訳してください。 /example 英語: apple 日本語: りんご /example 英語: 日本語: """
LLM から りんご と、デモンストレーションで使用した解答が出力されてしまう感じです。
--- デモンストレーションはバランスを考慮する
プロンプト作成の後期段階で few-shot を使う場合は、ドメインの類似性、問題形式の類似性、解答のバランス に注意してデモンストレーションを設計します。
一般的に 対象となる質問に対して類似するデモンストレーションを用意すると性能が改善される ことが示されており、検索器を用いてデモンストレーションを動的に検索する仕組みが提案されていたりします (Li+'21; Yang+'22)。

類似性の言及対象についてはいくつかあるとは思いますが、ドメインの類似性 (e.g. 就業規則, 部署など) や 問題形式の類似性 (e.g. 質問応答, フィードバックなど) などを意識します。
また 解答のバランス は、下図のように ラベル分布 と 順番 の2つの観点で注意しています。

あくまで経験則ではありますが、デモンストレーションの出現になんらかの傾りが生じないよう、ランダムに並び替えたり、正解ラベルの割合を事前に算出して制御したりします。
--- デモンストレーションは正確性を担保するのが正解とはいえない
日本語が難しく正しく伝わらないかもしれませんが、few-shot として与えるデモンストレーションは、正解であることに越したことはないと思いますが、必ずしも正確性を担保している状態が最適であるかどうかは断定できません。

実際にデモンストレーションの正誤が(多少)誤っている場合でも精度が著しく低下するとはいえず、また出力例を類似する誤答に置換する 反事実プロンプト (Zhou+'23) なども提案されています。
また few-shot プロンプトではないですが、タスクに関連する背景情報(コンテキスト)に関してもハルシネーションが一部含まれるコンテキストを挿入する方が、LLM の参照性が上がる可能性もあります (Cuconasu+'24; Köksal+'24)。
思考の連鎖(Chain-of-Thought; CoT)
思考の連鎖 (Chain-of-Thought) とは、中間推論過程を LLM に明示的に追跡させることで、「AだからBで、ゆえにCだ」のような思考を促す 手法です。

Few-shot プロンプトにおいて、(入力, 出力) ペアの代わりに、(入力, 中間推論過程, 出力) ペアを入力する ことで、対象タスクにおいて中間推論を誘発するというのが few-shot CoT と呼ばれます。
一方で (入力, 出力) ペアを呼び出し毎に用意するのは大変であるため、入出力ペアを必要とせずに中間推論を誘発させる のが zero-shot CoT (Kojima+'22) と呼ばれるもので、「ステップバイステップに考えて」といった表現を用います。
中間推論を促して複雑なタスクを単純なタスクに構成的に分解することで、よい応答を得る というのが思考の連鎖で狙うところになります。
--- 中間推論過程といっても様々な記述形式がある
Few-shot CoT では、タスクを構成的に分解してサブタスクの系列として中間推論過程を記述する ことが多いですが、他にも様々な記述形式が考えられます。
対照プロンプト という手法では、正解の推論過程と同時に 誤った推論過程 もプロンプトに組み込む方法が提案されています。

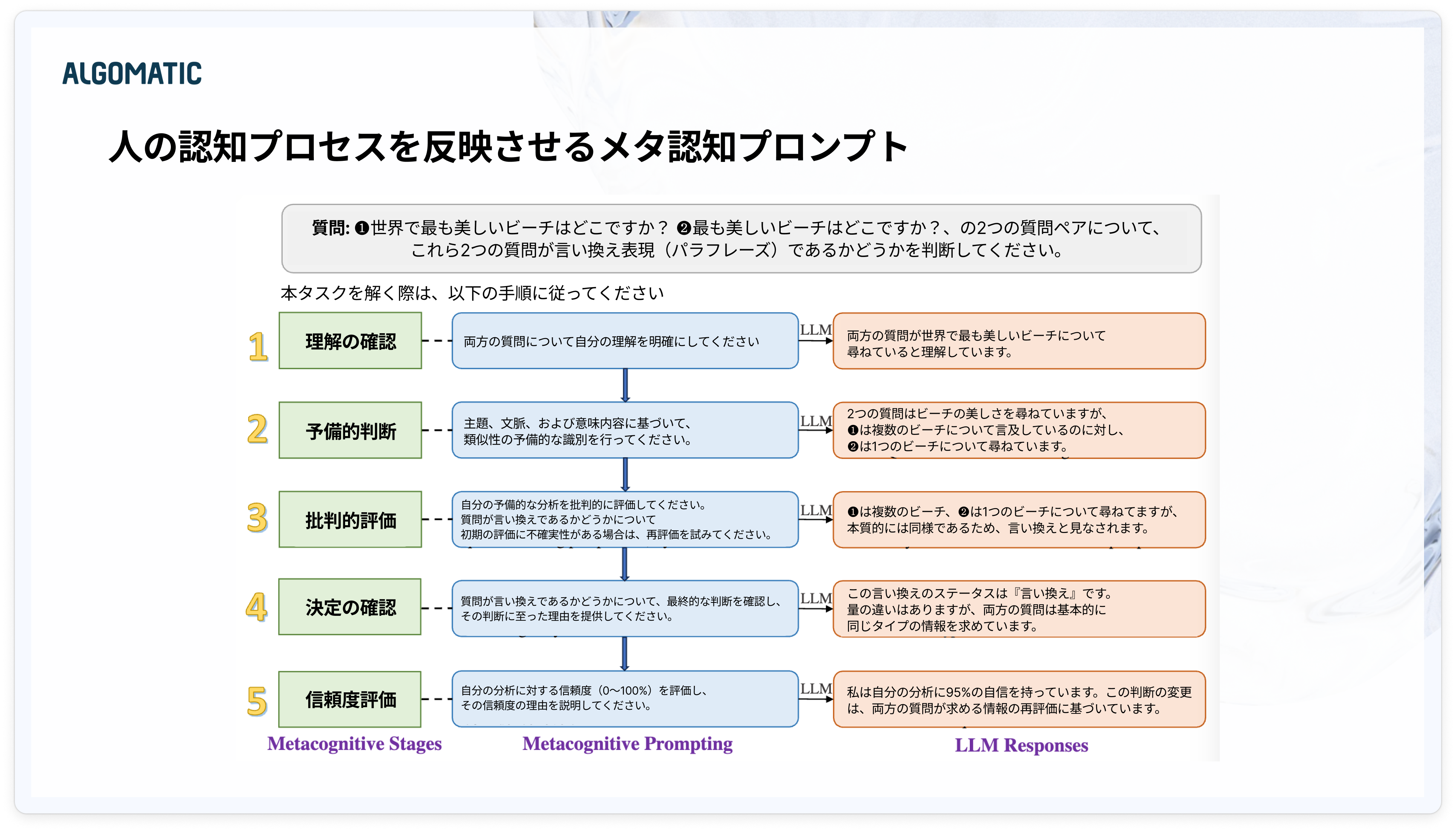
また メタ認知プロンプト では、ヒトの内省的推論プロセスに着想を得ることで、LLMの内的知識と新たな洞察を活用する手法が提案されています。
機械的なタスクでは推論手順を示して思考の連鎖を促す
Few-shot CoT も「ステップバイステップに考えて」という zero-shot CoT も、手法として優れている点があることは理解しつつ、ルールや規定を単純に適用する 機械的なタスク のプロンプト作成においては使用の機会が多くないです。
というのも意思決定プロセスや出力が事前に決定されている場合は、推論手順の全体像を先に示した上で「この手順で考えて」と指示する ことが多いです。
--- ダミーの出力を用いて思考の連鎖を促す
LLM からの応答文を後処理としてパースする場合や、構造化データとして出力する場合は、ダミーの出力を用いることで暗黙的に思考の連鎖を期待する ことがあります。

ダミーの出力は、無関係な情報である場合、対象タスクに対してうまく応答してくれない場合があるので、対象タスクに関連する情報や、対象タスクを解く際に必要となる補足情報を指定します。
次回予告
ここまでの #01~03 では LLMプロダクト開発におけるプロンプト設計、特に LLM からよい応答を得るための方法 について述べてきました。
次回は LLM からよい応答を得るために設計したプロンプトに着目して、「プロンプトの良さ」を担保するための評価とテスト について紹介します。 具体的には以下の話を少しだけ拡張してお話ししたいと思います!
おわりに
弊社ブログではプロンプト作成における自動化という記事も投稿していますのでこちらもご覧ください。
Algomatic では LLM を活用したプロダクト開発等を行っています。 LLM を活用したプロダクト開発に興味がある方は、下記リンクからカジュアル面談の応募ができるのでぜひお話ししましょう!