はじめまして!Algomatic LLM STUDIO でインターンをしている なべ(@_h0jicha)です。普段は大学でマルチモーダル大規模言語モデルの応用に関する研究に取り組んでいます。
Algomatic のインターンでは、LLM の評価に関して網羅的な調査や各種ツールの導入に取り組んできました。 本記事では、この知見を皆さんに共有することで、日本語圏における LLM 評価の現状を俯瞰していただき、各ツールを適切に選択するための糸口を提供することを目的とします。
はじめに
大規模言語モデル(LLM)の開発プレイヤーが増加している昨今において、日本語を対象言語とした運用を得意とする LLM が次々と公開されています。
LLM を安全に使用する ために、対象タスクに適した LLM を選択すること、ならびに有害なコンテンツ生成を検知することなど、LLM の性能を多角的に評価する枠組みが重要です。
現状では、あらゆるユースケースを包括的に評価可能な銀の弾丸としての日本語評価ツールは存在しないと判断されることが多々あります。しかし各評価ツールの特徴を理解した上で適切な評価を行うことで、対象となるタスク課題に対してどの程度 LLM を正確かつ安全に運用可能か把握することができます。
本記事の構成とスコープ
本記事の構成は以下の通りです。
- 評価観点:一般的な評価観点を参照することで、想定されるユースケースを整理します。
- 評価方法の分類:評価方法を大きく分類します。
- 評価ツール:LLM ベンチマークに焦点を当てて、英語圏と日本語圏のツールを紹介します。
また、本記事は以下のような内容を 対象外 とします。
- 評価観点の詳細な検討
- 言語モデルの古典的評価指標に関する詳細な内容
- コード生成・マルチモーダルタスクなどの周辺領域に関する評価内容
評価観点
Claude で知られる Anthropic は、LLM が獲得すべき汎用アシスタントとしての能力を、Helpful, Honest, Harmless の頭文字から「HHH」という表現でまとめています [1] 。

特に Harmless については Do-Not-Answer [2] に詳細な評価項目がまとめられています。
| 評価項目 | 説明 |
|---|---|
| Human-Chatbot Interaction Harms 人間とチャットボットの相互作用による害 |
|
| Malicious Use 悪意ある用途 |
|
| Discrimination, Exclusion, Toxicity, Hateful, Offensive 差別、排他性、有害性、憎悪、攻撃性 |
|
| Information Hazards 情報の危険因子 |
|
| Misinformation Harms 誤情報による害 |
|
本記事では以上の例を参照し、 LLM の日本語運用性能に関する評価観点として据えます*1。
以降では LLM の日本語運用において HHH の観点を検証する 評価方法 とその 評価ツール について紹介します。
評価方法の分類
ここでは、一般的な LLM の評価方法の種類を確認します。
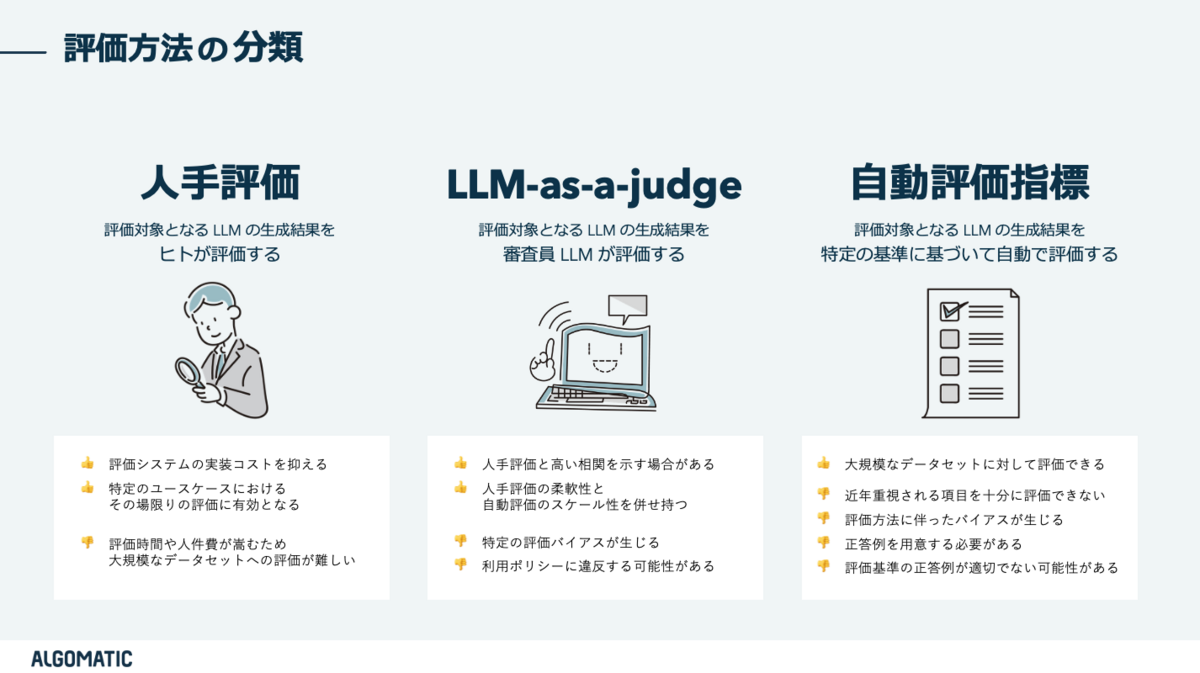
人手評価
一つ目の評価方法は、LLM が生成したテキストを人間が一つずつ確認する 人手評価 です。多くの場合に 評価システムの実装コストを抑える ことができ、特定のユースケースを その場限りで柔軟に評価したいという場合に効果的 な方法となります。
しかし人手評価は、人手が介入しない自動評価に比べて評価時間や人件費といったコストが嵩んでしまうケースが多いです。特に大規模なデータセットによる評価を実施する場合は、データセットの規模に比例して評価コストが増大してしまいます。
LLM-as-a-judge
人手評価に対して、人手が介入する部分を LLM で代理してしまおうというアイデアに基づいた LLM-as-a-judge [3] という評価方法があります*2。
LLM-as-a-judge では、評価対象の LLM の生成結果を審査する別の LLM(審査員 LLM)を新たに用意します。審査員 LLM には高い言語読解性能を示す GPT-4 などが使用されます。
具体的には、次の過程により評価を実施します(single answer grading の場合*3)。
- 評価対象の LLM に指示文を含む入力文を与えて応答文を得る
- 評価用のプロンプトテンプレート(下図)に入力文と応答文を代入する
- 作成したプロンプトを審査員 LLM に与え、評価スコアと解釈文を含む評価結果を得る

橙色は日本語訳。(図は [3] Figure 6 をもとに作成)
—— LLM による自動評価はどれくらい信用できるのか?
LLM-as-a-judge では、人手評価に対してどれだけ相関のある評価であるかという 一貫性の欠落 が懸念されます。GPT-4 を審査員 LLM として使用した場合、クラウドソーシングによる人手評価の結果に対して 80%以上の合意が達成された ことが報告されています。
このように LLM-as-a-judge は、人手評価の柔軟性と自動評価のスケール性の特長を併せ持ち、とりわけ Helpful, Honest の多様な観点を評価するために効果的 です。また評価スコアだけでなく、評価結果に対する解釈文が生成されるため、説明可能性においても優れていることが主張されています。
しかし LLM-as-a-judge には いくつかの評価バイアスを含む ことが報告されています。

位置バイアスについては、二つの応答の位置を交換して評価を実施し、二回の評価の結果が一致した場合に勝利とすることや、位置をランダムに決定することが対策として提案されています。一方で、冗長性バイアスや自己強化バイアスについては対策の余地が残されています。
また Harmless の観点については、審査員 LLM に対するプロンプトが利用ポリシーに違反する可能性も考えられます。
自動評価指標
人手および LLM を用いた評価について紹介しましたが、自然言語処理で一般的に利用される 自動評価指標 も使用可能です。
機械翻訳や自動要約の文脈では BLEU や ROUGE といった自動評価指標が採用され、正答例となる参照テキストに対する類似度を基として評価を行います。他にもタスクによっては正解率や F1-score のほか、テストの通過率といった指標が採用されています。
しかし自動評価指標は、近年重要視される オープン対話に対する指示追従能力や中間推論過程を含む高度な推論能力における性能評価には適さない と指摘される場合もあります。
典型的な自動評価指標が適用されるケースにおいては、あらかじめ入力と出力の正解ペアが用意されており、正解の出力(自然言語、選択肢、数値など)とモデルの応答文が比較されることで評価基準を満たすかどうかの判定が行われます。
一方で指示追従能力、高度な推論能力といった性能の評価においては 好ましい回答が一意に定まらない という問題が生じます。例えば、先生と生徒の対話において先生がある事柄を説明する方法には様々な過程が考えられます。短く端的に教えることが好ましいこともあれば、様々な周辺知識に触れながら教えることが好ましいこともあるでしょう。このように好ましい回答が一つに定まらない状況に対して、正解の出力との比較を行う自動評価指標の適用では、回答の多様性が十分に考慮されない可能性があります。
また入力と出力の 正解ペアを用意するためのアノテーションコストが高い という問題や、各評価指標における 評価上のバイアスによる過小/過大評価の発生 といった問題も存在します。ゆえに各タスクにおいて適切な評価指標を選択するためには十分な知識や検討が必要となります。
LLM の評価方法として ①人手評価 ②LLM-as-a-judge ③自動評価指標による評価方法を紹介しました。それぞれの評価方法が持つ特徴や問題点などはさまざまであり評価対象のユースケースに合わせて適切に選択することが重要 です。
評価ツール
ここではまず、英語を対象言語とした評価ツールについて簡単に確認し、 LLM の評価ツール全体の状況を俯瞰します。その後に日本語を対象言語とした評価ツールについて紹介します。
英語圏の LLM ベンチマーク - 概観
例えば HHH(Helpful, Honest, Harmless)の各観点に適したベンチマークとして、TruthfulQA、HaluEval、CrowS-Pairs といったベンチマークが存在します。また Introducing Gemini (Google Blog) では、Gemini の評価で使用されたベンチマークが紹介されています。
一般的に広く使用される MMLU(Measuring Massive Multitask Language Understanding)[4] は、初等数学、歴史、コンピュータサイエンス、法律をはじめとする 57 ジャンルが収録されており、LLM が幅広い世界知識を有しているかという観点が評価されます。MMLU タスクは 4 択の選択肢付き質問応答で構成されており、自動評価指標を用いた評価が行われます。

しかし、上述の自動評価指標の課題に関連して MMLU はユーザとの対話シナリオにおけるマルチターン対話性能や指示追従性能が十分に評価されないという指摘も存在します。
この問題を解決するために LLM-as-a-judge による評価方法が提案されています。なかでも一般的に利用される MT-Bench [3] は 80 件のマルチターンな質問が含まれており、マルチターン対話性能を評価することができます。
また質問には Writing, Roleplay をはじめとした 8 つのジャンルに区分される多様な指示文が含まれており、これらに対する指示追従性能を評価することも可能です(下図)。
ただし MT-Bench では、審査員 LLM に GPT-4 が使用されることが多く、自己強化バイアスにより GPT-4 による応答文の過大評価が懸念されます。また審査員 LLM として GPT-4 のようなプロプライエタリなモデルを採用する場合、その利用ポリシーに抵触しない範囲で使用する必要があるため、特に Harmless の観点の評価と相性が悪いという問題があります。

人手評価の例としては Chatbot Arena [3] も広く知られています。Chatbot Arena では、まず 2 つの評価対象 LLM の回答をモデル名は伏せた状態で人間のユーザに表示して、ユーザが好ましいと判断する方を選択するという対戦を繰り返します。そして各モデルのスコアを Elo rating により決定することで、モデルの性能を評価します。
各方法による評価結果が一元的に公開されているリーダーボードも存在しています。Open LLM Leaderboard がその例となります。さらに気になる方は、[5] や [6] のサーベイ論文を参照してみてください。
日本語圏の LLM ベンチマーク:自動評価指標による方法
自動評価指標に基づくベンチマークとして、2022年6月にヤフー(現 LINEヤフー)と早稲田大学河原研究室のチームから JGLUE が公開されています。JGLUE は、自然言語理解(Natural Language Understanding: NLU)に関する英語圏のベンチマークである GLUE [7] を参考に作成されており、収録されているタスクは以下の通りです [8] 。
- MARC-ja:Amazon の日本語商品レビューに対して positive/negative を判定するタスク
- JSTS:文ペアの類似度を 0-5 の値で推定する STS(Semantic Textual Similarity)タスク
- JNLI:文ペアの推論関係を含意(entailment)・矛盾(contradiction)・中立(neutral)の中から推定する NLI(Natural Language Inference)タスク
- JSQuAD:Wikipedia の日本語記事から抜粋された一段落に対する質問を、段落の中から抽出する機械読解タスク
- JCommonsenseQA:常識的な知識を問う質問に対して 5 つの選択肢から解答を選択する選択肢付き質問応答タスク
- JCoLA [9] :LLM の統語的知識を問うべく、提示された文が文法上容認されるかを判断するタスク(容認性判断課題)
JGLUE は、必ずしも LLM の評価が指向されたものではなく、自然言語理解の性能を評価する ために作成されたベンチマークになります。[8] の実験においても、評価には BERT 系のモデルが使用されており、近年主流な Transformer Decoder に基づいたモデルの評価は十分に検討されていません。
特に、回答において想定される応答文が数単語程度であることから、指示追従能力や高度な推論能力といった観点の評価は十分に行われていない と判断される場合があります。
しかし JGLUE は ChatGPT 以後における LLM の日本語運用性能の評価においても広く使われてきたことから、様々なモデルの評価結果が公開されており、多様な比較対象が存在する 点は現在でも特に参照されるべき点であると考えられます。
この他にも、類似したベンチマークとして Stability-AI/lm-evaluation-harness(日本語版 llm-evaluation-harness)や llm-jp-eval が存在します。これらには、JGLUE の各タスクが含まれつつ、それ以外のタスクも追加されています。llm-jp-eval は、自然言語処理や計算機システムの研究者が集まる LLM 勉強会(LLM-jp) が公開しているものであり、今後のアップデートに期待が持てます。さらに、特に最近は早稲田大学河原研究室から MMLU に基づいて作成された JMMLU が公開されています。
日本語圏の LLM ベンチマーク:人手評価による方法
LLM の指示追従能力や高度な推論能力を評価するためのベンチマークとして、2023年8月に ELYZA から ELYZA-tasks-100 が公開されました。ELYZA-tasks-100 は、100 件の複雑な日本語タスクを含む評価データセットであり、添付される明確な採点基準に基づいてモデルの様々な言語能力を人手評価するものです。
収録されている タスクの多様性 が大きな特徴の 1 つであり、これにより LLM の指示追従能力や高度な推論能力を評価することができます。例えば、ユーザーの意図を適切に汲んで、有益な情報を提示できるかを評価するために以下のような例が収録されています。
入力: あの、娘がやっているあのキ、チックトック?チックトッカー?っていうのは何なんですか? 出力例: 娘さんがやっていらっしゃるのは、おそらくTikTok (ティックトック) というSNSのことではないでしょうか? TikTokは短い動画に特化したSNSで、10~20代の若年層を中心にショートムービーをテンポよく閲覧することが流行しています。 TikToker (ティックトッカー)とは、TikTok内でオリジナル動画を投稿している人たちのことを指す言葉です。 採点基準: A. 誤りを修正すること(キックトック→TikTok)ができるか B. 「あなたが言いたいのはOOですか?」と聞き返したり、「おそらくOOのことだと思います」のように、入力に誤りが含まれ回答が不確実になってしまうことに配慮した回答になっているか C. 1つのクエリの中に2つのエンティティ(TikTok, TikToker)があることを認識し、それぞれに対する説明を行うことができるか - Aができていない場合: -2点 - TikTokではなく「チクタクとは時計のなる音の擬音語のことです」など「娘がやっている」という条件を満たさない不正解のものだが誤りの修正を試みている場合: -1点のみ - Bができていない場合: -2点 - Cができていない場合: -1点
ELYZA-tasks-100 に収録されているデータの例(ELYZA-tasks-100 より引用)
なお ELYZA-tasks-100 は人手評価による方法が想定されますが、LLM-as-a-judge による評価も検討することができます。LLM-as-a-judge に関する 分析 や、実際に試行されたケース(ryousuke wayama さんの記事)も存在しています。
日本語圏のLLMベンチマーク:LLM-as-a-judgeによる方法
人手評価に基づく方法の発展と同時期に LLM-as-a-judge に基づくベンチマークが複数公開されてきました。
代表的なものとして MT-Bench を日本の文化や特徴に即して再編した Japanese MT-Bench があります。以下は、評価用プロンプト、回答、審査員 LLM(GPT-4)による評価結果の例になります。
評価 "[指示] 公平な判断者として行動し、以下に表示されるユーザーの質問に対するAIアシスタントの応答の品質を評価してください。あなたの評価は、応答の有用性、関連性、正確性、深さ、創造性、詳細度などの要素を考慮すべきです。評価は短い説明から始めてください。できるだけ客観的であること。説明を提供した後、このフォーマットに厳密に従って1から10までのスケールで応答を評価する必要があります:"[[評価]]"、例えば:"評価:[[5]]"。 [質問] ドラえもんの「のび太」になりきって会話を始めましょう。では以下の質問から始めてください:"手を洗った後、エアドライヤーは必要だと思いますか?" [アシスタントの回答の開始] うーん、必要ではないと思う。 [アシスタントの回答の終了]" 判断 "アシスタントの回答は短く、詳細が不足しています。また、ユーザーが要求した「のび太」のキャラクターになりきるという要素も欠けています。そのため、この回答はユーザーの期待を満たしていないと言えます。しかし、質問に対する直接的な回答は提供されているため、全く無関係または無意味な回答ではありません。 評価:[[3]]"
Japanese MT-Bench の評価用プロンプト、Japanese-StableLM-Instruct-Alpha-7B による回答、および GPT-4 による評価結果(Stability-AI/FastChat より引用)
コードベースの評価ツールについてもいくつか存在します。例えば、先駆的に取り組まれており現在も更新が続いている Stability-AI/FastChat や、WandBによってNejumi LLM リーダーボード Neo と共に公開されている wandb/llm-leaderboard が存在します。wandb/llm-leaderboard は llm-jp-eval と合わせた評価も可能になっています。
またコードベースのほか WandB が Nejumi LLM リーダーボード Neo と共に公開している WandB Launch Job を使用することもできます。WandB Launch は WandB によって用意されているジョブキューの仕組みを活用することができる機能であり、これを使用することであらかじめ用意された評価ジョブを簡単に起動することができます*4。
他にも類似したベンチマークとして京都大学の 言語メディア研究室 が公開している Japanese Vicuna QA Benchmark などが存在します。
またドメインを限定したベンチマークとして以下を確認しています。
- Rakuda Benchmark:日本の地理・政治・歴史・社会に関する質問応答(各10問)
- LLMの日本の知識を評価するデータセット:日本の文化、社会、政治経済、歴史に関する質問応答(各10問)
- stockmark/business-questions:時事問題・ビジネストレンドなどに関する質問応答(全50問)
- japanese-llm-roleplay-benchmark:ロールプレイ・性的な対話に関する評価
また専門分野に関する知識を評価するためのベンチマークとして以下を確認しています。
- pfnet-research/japanese-lm-fin-harness:金融に関する質問応答
- IgakuQA(医学QA):医師国家試験に基づいた質問応答
日本語圏の LLM ベンチマーク:Harmless の評価
Helpful, Honest の観点は、質問応答や対話タスクの実施によって十分に評価されるため、前述したベンチマークから確認することができる場合が多いです。一方で、Harmless の観点は、前述の通り OpenAI の利用ポリシーに対する抵触が障壁となり、特に LLM-as-a-judge を適用することが難しいです。
こうした中で使用することができるツールとして、技術的な脅威に対する安全保障を目的としている Google Jigsaw から Perspective API が公開されています。これは、テキストをリクエストとして送信すると、その有害性が Toxicity スコアとして返却されるものです。
一方で、OpenAI から Moderation API が公開されています。これは、テキストが OpenAI の利用ポリシーに抵触するかどうかを確認することができるものです。以前までは利用用途が OpenAI API の入出力テキストを評価する場合のみに制限されていましたが、現在はその記述が削除されているため一般的な用途で使用可能になっていると思われます(参考)。
また Do-Not-Answer [2] の翻訳に基づいて作成された Do-Not-Answer-Ja が公開されています。他にも、Harmless の評価に活用することができる以下のようなデータセットが公開されています。
- inappropriate-words-ja:不適切表現フィルタリングのための単語リスト
- 日本語人権侵害表現データセット:インターネット上の投稿の中で人権侵害が争われたテキストを集めたもの
- 日本語有害表現スキーマ:多様なレベル・カテゴリのアノテーションが付与された有害テキスト
日本語圏の LLM ベンチマーク:リーダーボード
最後に、最近特にアクティブなリーダーボードを紹介します。
- Nejumi LLMリーダーボードNeo:Japanese MT-Bench と llm-jp-eval の評価結果
- Nejumi LLMリーダーボード(旧):JGLUE(Nejumi)の評価結果
- llm-jp-eval リーダーボード:llm-jp-eval の評価結果
- yutohub/japanese-chatbot-arena-leaderboard:日本語版 Chatbot Arena
前述した通り Nejumi LLM リーダーボード系は WandB Launch の機能を用いて容易に評価を実施することが可能である点が魅力的です。
おわりに
本記事では、LLM の日本語運用性能を評価する際の評価観点・評価方法・具体的な評価ツールを確認しました。
なお今回の記事の内容は 2024年2月現在のカットオフに基づいている ことに触れておきます。本記事を執筆している間にも多くの方々が LLM 評価における活動をされていたため、今後も内容が更新されることが見込まれます。
本記事では触れていない周辺領域についてもお話ししたいことがたくさんあります。今後も発信を続けていきたいと思いますので、ぜひスター・シェアをよろしくお願いします!
Algomatic LLM STUDIO では、LLM を活用した新たなプロダクトの開発に取り組んでいます。
今回の内容に少しでも興味を持たれた方や、LLM を活用したプロダクトの開発に興味をお持ちの方は、ぜひ一度お話ししてみませんか?
下記のリンクから 30秒でカジュアル面談が応募できます ので、ぜひご連絡ください!
参考文献
[1] Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861, 2021.
[2] Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-Not-Answer: A dataset for evaluating safeguards in llms. arXiv preprint arXiv:2308.13387, 2023.
[3] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, Vol. 36, 2024.
[4] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[5] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 2023.
[6] Zishan Guo, Renren Jin, Chuang Liu, Yufei Huang, Dan Shi, Linhao Yu, Yan Liu, Jiaxuan Li, Bojian Xiong, Deyi Xiong, et al. Evaluating large language models: A comprehensive survey. arXiv preprint arXiv:2310.19736, 2023.
[7] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proc. of International Conference on Learning Representations, 2019.
[8] 栗原健太郎, 河原大輔, 柴田知秀. JGLUE: 日本語言語理解ベンチマーク. 言語処理学会第 28 回年次大会, 2022.
[9] 染谷大河, 大関洋平. 日本語版CoLAの構築. 言語処理学会第 28 回年次大会, 2022.
その他の関連記事
- Jeffrey Ip. LLM Evaluation Metrics: Everything You Need for LLM Evaluation. Confident AI Blog, 2024.
- Jane Huang. Evaluating Large Language Model (LLM) systems: Metrics, challenges, and best practices. medium.com, 2024.
筆者情報

*1:本記事では LLM の日本語運用性能に関する評価観点に HHH の観点を据えていますが、自分達の評価したい観点を検証する 評価観点の明確化は評価ツールの選定に先立って入念に行う ことが望ましいです。
*2:同様のアイデアによる評価は同時期にいくつか提案されていますが、Vicuna で有名な LMSYS Org のメンバーがその特性を包括的に検証して LLM-as-a-judge と呼称したことで、以降この用語が広く参照されるようになりました。
*3:[3]では、評価対象 LLM と審査員 LLM を使用する single answer grading の他に、比較対象 LLM を新たに用意してその回答との勝敗で評価する pairwise comparison や、審査員 LLM による評価を補助するために参照回答を用意する reference-guided grading が提案されています。特に single answer grading と pairwise comparison は、スケール性と評価の正確性においてトレードオフの関係にあります。
*4:旧版Nejumi LLMリーダーボードの公開と合わせて JGLUE の WandB Launch Job も公開されており、こちらも使用可能です。また、使用方法の解説も公開されています。